 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach YOLO to Remember: A Self-Distillation Approach for Continual Object Detection
Paper and Code
Mar 06, 2025
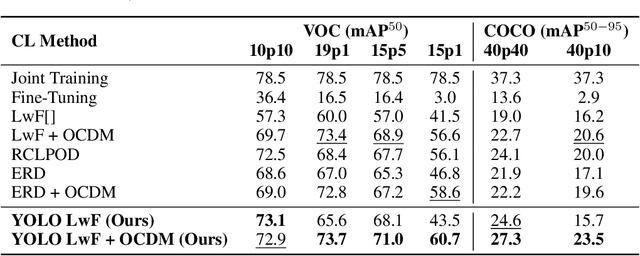
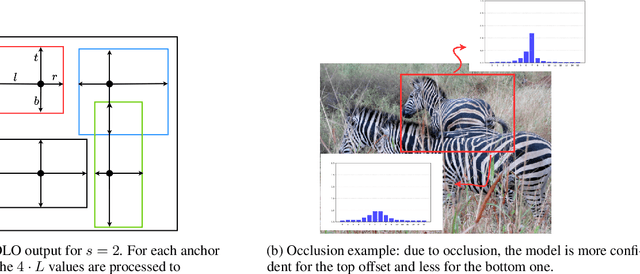
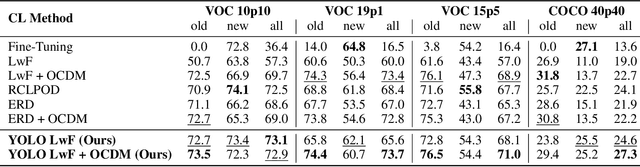
Real-time object detectors like YOLO achieve exceptional performance when trained on large datasets for multiple epochs. However, in real-world scenarios where data arrives incrementally, neural networks suffer from catastrophic forgetting, leading to a loss of previously learned knowledge. To address this, prior research has explored strategies for Class Incremental Learning (CIL) in Continual Learning for Object Detection (CLOD), with most approaches focusing on two-stage object detectors. However, existing work suggests that Learning without Forgetting (LwF) may be ineffective for one-stage anchor-free detectors like YOLO due to noisy regression outputs, which risk transferring corrupted knowledge. In this work, we introduce YOLO LwF, a self-distillation approach tailored for YOLO-based continual object detection. We demonstrate that when coupled with a replay memory, YOLO LwF significantly mitigates forgetting. Compared to previous approaches, it achieves state-of-the-art performance, improving mAP by +2.1% and +2.9% on the VOC and COCO benchmarks, respectively.