 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Analysis Systems and Down Syndrome
Feb 10, 2025The ethical, social and legal issues surrounding facial analysis technologies have been widely debated in recent years. Key critics have argued that these technologies can perpetuate bias and discrimination, particularly against marginalized groups. We contribute to this field of research by reporting on the limitations of facial analysis systems with the faces of people with Down syndrome: this particularly vulnerable group has received very little attention in the literature so far. This study involved the creation of a specific dataset of face images. An experimental group with faces of people with Down syndrome, and a control group with faces of people who are not affected by the syndrome. Two commercial tools were tested on the dataset, along three tasks: gender recognition, age prediction and face labelling. The results show an overall lower accuracy of prediction in the experimental group, and other specific patterns of performance differences: i) high error rates in gender recognition in the category of males with Down syndrome; ii) adults with Down syndrome were more often incorrectly labelled as children; iii) social stereotypes are propagated in both the control and experimental groups, with labels related to aesthetics more often associated with women, and labels related to education level and skills more often associated with men. These results, although limited in scope, shed new light on the biases that alter face classification when applied to faces of people with Down syndrome. They confirm the structural limitation of the technology, which is inherently dependent on the datasets used to train the models.
Testing software for non-discrimination: an updated and extended audit in the Italian car insurance domain
Feb 10, 2025Context. As software systems become more integrated into society's infrastructure, the responsibility of software professionals to ensure compliance with various non-functional requirements increases. These requirements include security, safety, privacy, and, increasingly, non-discrimination. Motivation. Fairness in pricing algorithms grants equitable access to basic services without discriminating on the basis of protected attributes. Method. We replicate a previous empirical study that used black box testing to audit pricing algorithms used by Italian car insurance companies, accessible through a popular online system. With respect to the previous study, we enlarged the number of tests and the number of demographic variables under analysis. Results. Our work confirms and extends previous findings, highlighting the problematic permanence of discrimination across time: demographic variables significantly impact pricing to this day, with birthplace remaining the main discriminatory factor against individuals not born in Italian cities. We also found that driver profiles can determine the number of quotes available to the user, denying equal opportunities to all. Conclusion. The study underscores the importance of testing for non-discrimination in software systems that affect people's everyday lives. Performing algorithmic audits over time makes it possible to evaluate the evolution of such algorithms. It also demonstrates the role that empirical software engineering can play in making software systems more accountable.
Detecting discriminatory risk through data annotation based on Bayesian inferences
Jan 27, 2021



Thanks to the increasing growth of computational power and data availability, the research in machine learning has advanced with tremendous rapidity. Nowadays, the majority of automatic decision making systems are based on data. However, it is well known that machine learning systems can present problematic results if they are built on partial or incomplete data. In fact, in recent years several studies have found a convergence of issues related to the ethics and transparency of these systems in the process of data collection and how they are recorded. Although the process of rigorous data collection and analysis is fundamental in the model design, this step is still largely overlooked by the machine learning community. For this reason, we propose a method of data annotation based on Bayesian statistical inference that aims to warn about the risk of discriminatory results of a given data set. In particular, our method aims to deepen knowledge and promote awareness about the sampling practices employed to create the training set, highlighting that the probability of success or failure conditioned to a minority membership is given by the structure of the data available. We empirically test our system on three datasets commonly accessed by the machine learning community and we investigate the risk of racial discrimination.
The invisible power of fairness. How machine learning shapes democracy
Mar 22, 2019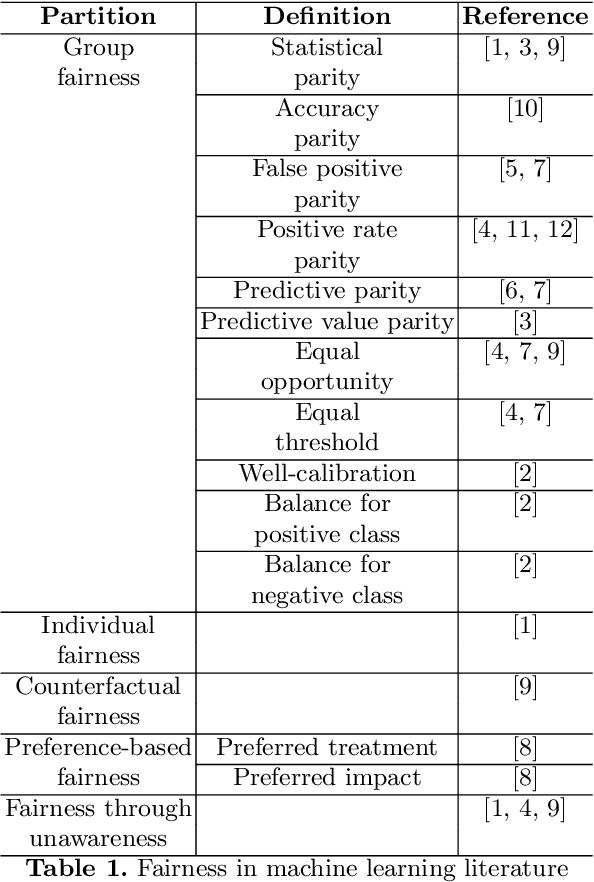
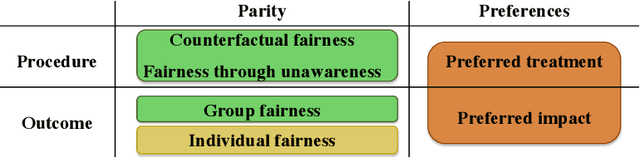
Many machine learning systems make extensive use of large amounts of data regarding human behaviors. Several researchers have found various discriminatory practices related to the use of human-related machine learning systems, for example in the field of criminal justice, credit scoring and advertising. Fair machine learning is therefore emerging as a new field of study to mitigate biases that are inadvertently incorporated into algorithms. Data scientists and computer engineers are making various efforts to provide definitions of fairness. In this paper, we provide an overview of the most widespread definitions of fairness in the field of machine learning, arguing that the ideas highlighting each formalization are closely related to different ideas of justice and to different interpretations of democracy embedded in our culture. This work intends to analyze the definitions of fairness that have been proposed to date to interpret the underlying criteria and to relate them to different ideas of democracy.