 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
Average-Reward Maximum Entropy Reinforcement Learning for Underactuated Double Pendulum Tasks
Sep 13, 2024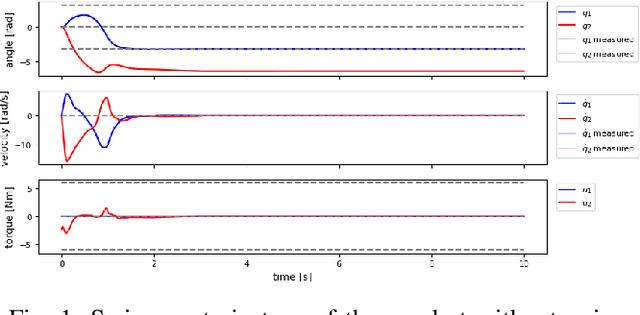
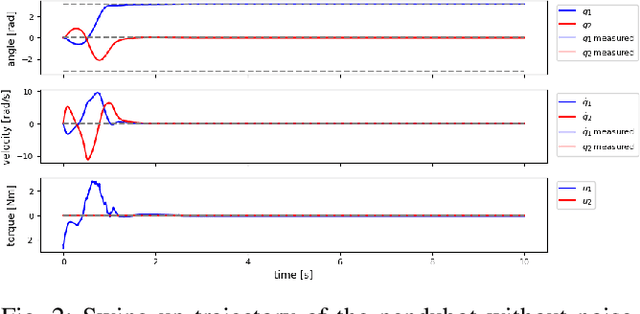
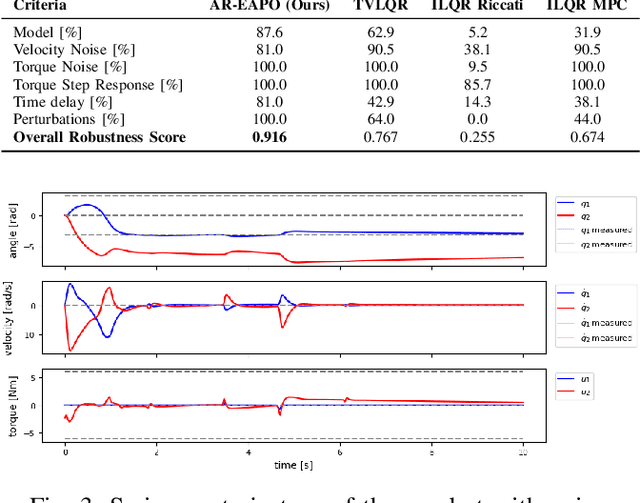
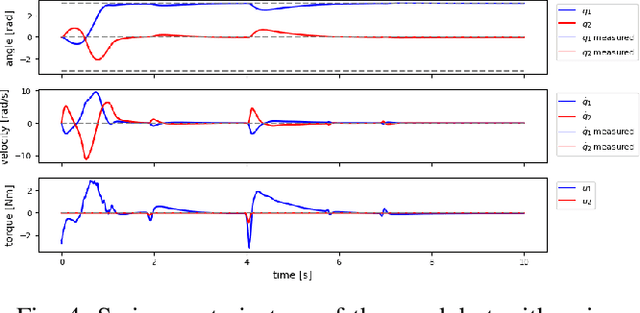
This report presents a solution for the swing-up and stabilisation tasks of the acrobot and the pendubot, developed for the AI Olympics competition at IROS 2024. Our approach employs the Average-Reward Entropy Advantage Policy Optimization (AR-EAPO), a model-free reinforcement learning (RL) algorithm that combines average-reward RL and maximum entropy RL. Results demonstrate that our controller achieves improved performance and robustness scores compared to established baseline methods in both the acrobot and pendubot scenarios, without the need for a heavily engineered reward function or system model. The current results are applicable exclusively to the simulation stage setup.
Maximum Entropy On-Policy Actor-Critic via Entropy Advantage Estimation
Jul 25, 2024Entropy Regularisation is a widely adopted technique that enhances policy optimisation performance and stability. A notable form of entropy regularisation is augmenting the objective with an entropy term, thereby simultaneously optimising the expected return and the entropy. This framework, known as maximum entropy reinforcement learning (MaxEnt RL), has shown theoretical and empirical successes. However, its practical application in straightforward on-policy actor-critic settings remains surprisingly underexplored. We hypothesise that this is due to the difficulty of managing the entropy reward in practice. This paper proposes a simple method of separating the entropy objective from the MaxEnt RL objective, which facilitates the implementation of MaxEnt RL in on-policy settings. Our empirical evaluations demonstrate that extending Proximal Policy Optimisation (PPO) and Trust Region Policy Optimisation (TRPO) within the MaxEnt framework improves policy optimisation performance in both MuJoCo and Procgen tasks. Additionally, our results highlight MaxEnt RL's capacity to enhance generalisation.
The Bid Picture: Auction-Inspired Multi-player Generative Adversarial Networks Training
Mar 20, 2024This article proposes auction-inspired multi-player generative adversarial networks training, which mitigates the mode collapse problem of GANs. Mode collapse occurs when an over-fitted generator generates a limited range of samples, often concentrating on a small subset of the data distribution. Despite the restricted diversity of generated samples, the discriminator can still be deceived into distinguishing these samples as real samples from the actual distribution. In the absence of external standards, a model cannot recognize its failure during the training phase. We extend the two-player game of generative adversarial networks to the multi-player game. During the training, the values of each model are determined by the bids submitted by other players in an auction-like process.