 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer Abstraction for Nested Generation of Options (MANGO) in Hierarchical Reinforcement Learning
Aug 25, 2025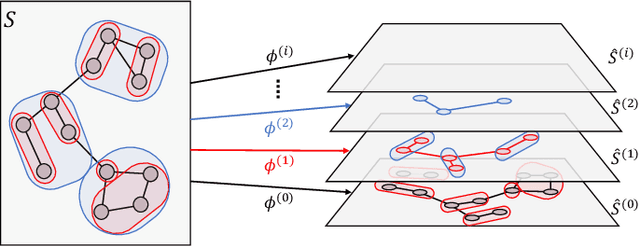
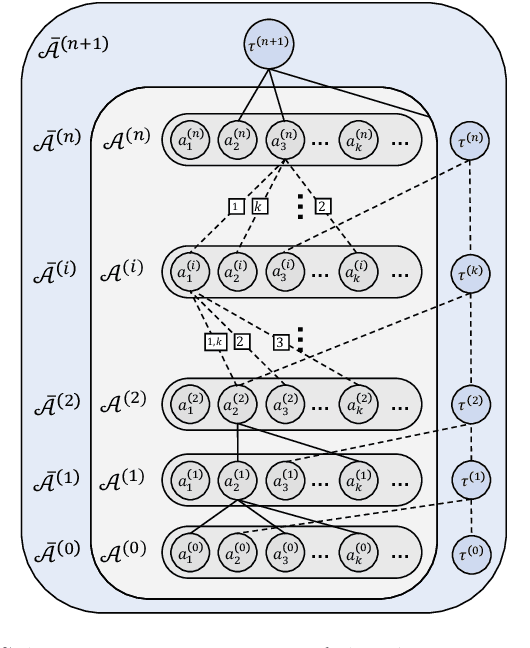

This paper introduces MANGO (Multilayer Abstraction for Nested Generation of Options), a novel hierarchical reinforcement learning framework designed to address the challenges of long-term sparse reward environments. MANGO decomposes complex tasks into multiple layers of abstraction, where each layer defines an abstract state space and employs options to modularize trajectories into macro-actions. These options are nested across layers, allowing for efficient reuse of learned movements and improved sample efficiency. The framework introduces intra-layer policies that guide the agent's transitions within the abstract state space, and task actions that integrate task-specific components such as reward functions. Experiments conducted in procedurally-generated grid environments demonstrate substantial improvements in both sample efficiency and generalization capabilities compared to standard RL methods. MANGO also enhances interpretability by making the agent's decision-making process transparent across layers, which is particularly valuable in safety-critical and industrial applications. Future work will explore automated discovery of abstractions and abstract actions, adaptation to continuous or fuzzy environments, and more robust multi-layer training strategies.
Simple and Effective Specialized Representations for Fair Classifiers
May 16, 2025



Fair classification is a critical challenge that has gained increasing importance due to international regulations and its growing use in high-stakes decision-making settings. Existing methods often rely on adversarial learning or distribution matching across sensitive groups; however, adversarial learning can be unstable, and distribution matching can be computationally intensive. To address these limitations, we propose a novel approach based on the characteristic function distance. Our method ensures that the learned representation contains minimal sensitive information while maintaining high effectiveness for downstream tasks. By utilizing characteristic functions, we achieve a more stable and efficient solution compared to traditional methods. Additionally, we introduce a simple relaxation of the objective function that guarantees fairness in common classification models with no performance degradation. Experimental results on benchmark datasets demonstrate that our approach consistently matches or achieves better fairness and predictive accuracy than existing methods. Moreover, our method maintains robustness and computational efficiency, making it a practical solution for real-world applications.
Advancing Constrained Monotonic Neural Networks: Achieving Universal Approximation Beyond Bounded Activations
May 05, 2025



Conventional techniques for imposing monotonicity in MLPs by construction involve the use of non-negative weight constraints and bounded activation functions, which pose well-known optimization challenges. In this work, we generalize previous theoretical results, showing that MLPs with non-negative weight constraint and activations that saturate on alternating sides are universal approximators for monotonic functions. Additionally, we show an equivalence between the saturation side in the activations and the sign of the weight constraint. This connection allows us to prove that MLPs with convex monotone activations and non-positive constrained weights also qualify as universal approximators, in contrast to their non-negative constrained counterparts. Our results provide theoretical grounding to the empirical effectiveness observed in previous works while leading to possible architectural simplification. Moreover, to further alleviate the optimization difficulties, we propose an alternative formulation that allows the network to adjust its activations according to the sign of the weights. This eliminates the requirement for weight reparameterization, easing initialization and improving training stability. Experimental evaluation reinforces the validity of the theoretical results, showing that our novel approach compares favourably to traditional monotonic architectures.
Reinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
Edge Delayed Deep Deterministic Policy Gradient: efficient continuous control for edge scenarios
Dec 09, 2024
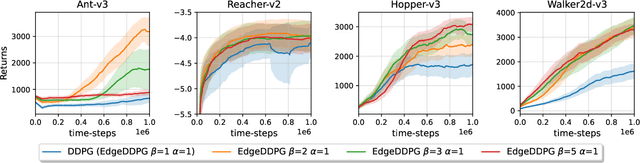


Deep Reinforcement Learning is gaining increasing attention thanks to its capability to learn complex policies in high-dimensional settings. Recent advancements utilize a dual-network architecture to learn optimal policies through the Q-learning algorithm. However, this approach has notable drawbacks, such as an overestimation bias that can disrupt the learning process and degrade the performance of the resulting policy. To address this, novel algorithms have been developed that mitigate overestimation bias by employing multiple Q-functions. Edge scenarios, which prioritize privacy, have recently gained prominence. In these settings, limited computational resources pose a significant challenge for complex Machine Learning approaches, making the efficiency of algorithms crucial for their performance. In this work, we introduce a novel Reinforcement Learning algorithm tailored for edge scenarios, called Edge Delayed Deep Deterministic Policy Gradient (EdgeD3). EdgeD3 enhances the Deep Deterministic Policy Gradient (DDPG) algorithm, achieving significantly improved performance with $25\%$ less Graphics Process Unit (GPU) time while maintaining the same memory usage. Additionally, EdgeD3 consistently matches or surpasses the performance of state-of-the-art methods across various benchmarks, all while using $30\%$ fewer computational resources and requiring $30\%$ less memory.
AI Olympics challenge with Evolutionary Soft Actor Critic
Sep 02, 2024

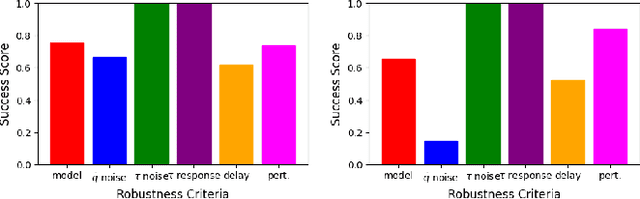

In the following report, we describe the solution we propose for the AI Olympics competition held at IROS 2024. Our solution is based on a Model-free Deep Reinforcement Learning approach combined with an evolutionary strategy. We will briefly describe the algorithms that have been used and then provide details of the approach
Exploiting Estimation Bias in Deep Double Q-Learning for Actor-Critic Methods
Feb 14, 2024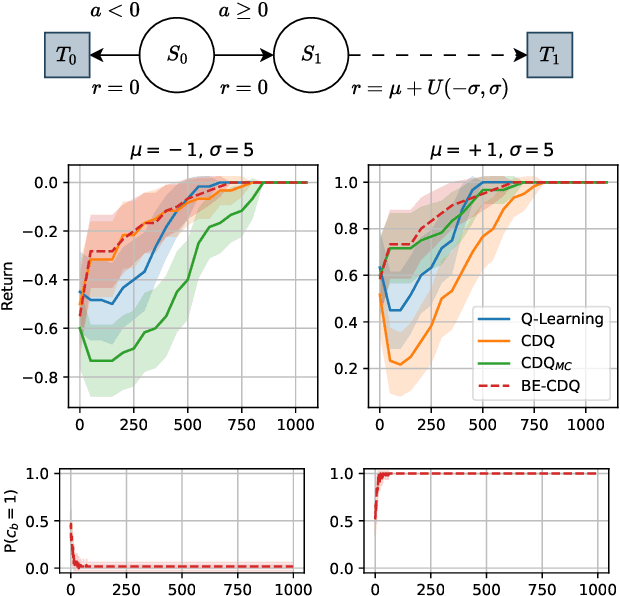

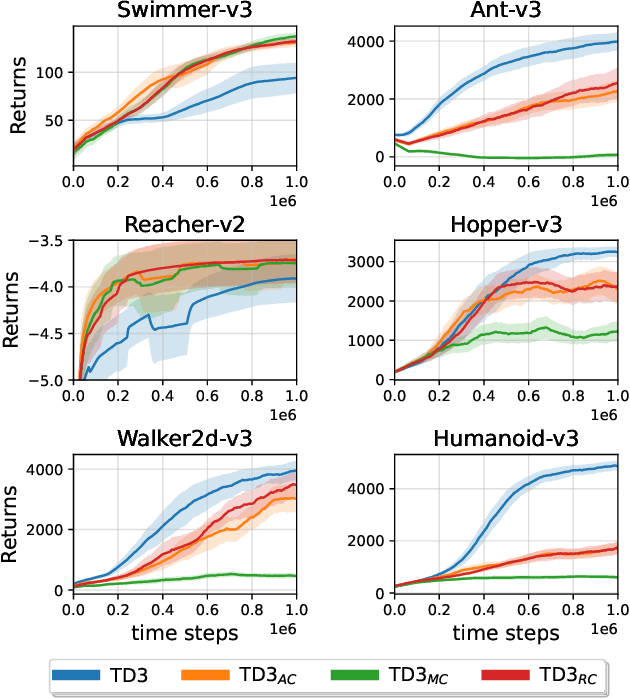

This paper introduces innovative methods in Reinforcement Learning (RL), focusing on addressing and exploiting estimation biases in Actor-Critic methods for continuous control tasks, using Deep Double Q-Learning. We propose two novel algorithms: Expectile Delayed Deep Deterministic Policy Gradient (ExpD3) and Bias Exploiting - Twin Delayed Deep Deterministic Policy Gradient (BE-TD3). ExpD3 aims to reduce overestimation bias with a single $Q$ estimate, offering a balance between computational efficiency and performance, while BE-TD3 is designed to dynamically select the most advantageous estimation bias during training. Our extensive experiments across various continuous control tasks demonstrate the effectiveness of our approaches. We show that these algorithms can either match or surpass existing methods like TD3, particularly in environments where estimation biases significantly impact learning. The results underline the importance of bias exploitation in improving policy learning in RL.