 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy On-Policy Actor-Critic via Entropy Advantage Estimation
Jul 25, 2024Entropy Regularisation is a widely adopted technique that enhances policy optimisation performance and stability. A notable form of entropy regularisation is augmenting the objective with an entropy term, thereby simultaneously optimising the expected return and the entropy. This framework, known as maximum entropy reinforcement learning (MaxEnt RL), has shown theoretical and empirical successes. However, its practical application in straightforward on-policy actor-critic settings remains surprisingly underexplored. We hypothesise that this is due to the difficulty of managing the entropy reward in practice. This paper proposes a simple method of separating the entropy objective from the MaxEnt RL objective, which facilitates the implementation of MaxEnt RL in on-policy settings. Our empirical evaluations demonstrate that extending Proximal Policy Optimisation (PPO) and Trust Region Policy Optimisation (TRPO) within the MaxEnt framework improves policy optimisation performance in both MuJoCo and Procgen tasks. Additionally, our results highlight MaxEnt RL's capacity to enhance generalisation.
The Bid Picture: Auction-Inspired Multi-player Generative Adversarial Networks Training
Mar 20, 2024This article proposes auction-inspired multi-player generative adversarial networks training, which mitigates the mode collapse problem of GANs. Mode collapse occurs when an over-fitted generator generates a limited range of samples, often concentrating on a small subset of the data distribution. Despite the restricted diversity of generated samples, the discriminator can still be deceived into distinguishing these samples as real samples from the actual distribution. In the absence of external standards, a model cannot recognize its failure during the training phase. We extend the two-player game of generative adversarial networks to the multi-player game. During the training, the values of each model are determined by the bids submitted by other players in an auction-like process.
TT-BLIP: Enhancing Fake News Detection Using BLIP and Tri-Transformer
Mar 19, 2024Detecting fake news has received a lot of attention. Many previous methods concatenate independently encoded unimodal data, ignoring the benefits of integrated multimodal information. Also, the absence of specialized feature extraction for text and images further limits these methods. This paper introduces an end-to-end model called TT-BLIP that applies the bootstrapping language-image pretraining for unified vision-language understanding and generation (BLIP) for three types of information: BERT and BLIP\textsubscript{Txt} for text, ResNet and BLIP\textsubscript{Img} for images, and bidirectional BLIP encoders for multimodal information. The Multimodal Tri-Transformer fuses tri-modal features using three types of multi-head attention mechanisms, ensuring integrated modalities for enhanced representations and improved multimodal data analysis. The experiments are performed using two fake news datasets, Weibo and Gossipcop. The results indicate TT-BLIP outperforms the state-of-the-art models.
Cross-Modal Contrastive Representation Learning for Audio-to-Image Generation
Jul 20, 2022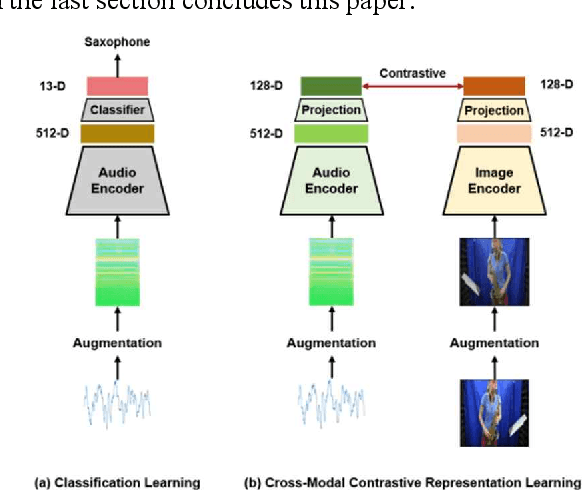

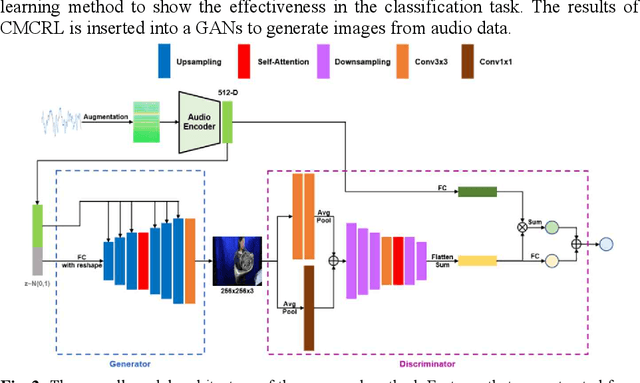

Multiple modalities for certain information provide a variety of perspectives on that information, which can improve the understanding of the information. Thus, it may be crucial to generate data of different modality from the existing data to enhance the understanding. In this paper, we investigate the cross-modal audio-to-image generation problem and propose Cross-Modal Contrastive Representation Learning (CMCRL) to extract useful features from audios and use it in the generation phase. Experimental results show that CMCRL enhances quality of images generated than previous research.
Micro Batch Streaming: Allowing the Training of DNN models Using a large batch size on Small Memory Systems
Oct 24, 2021
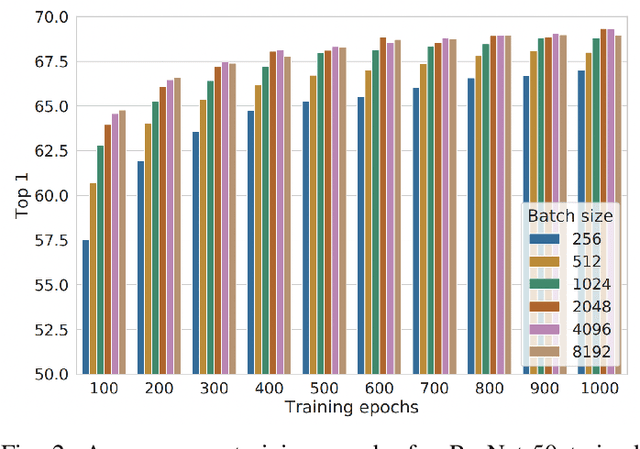

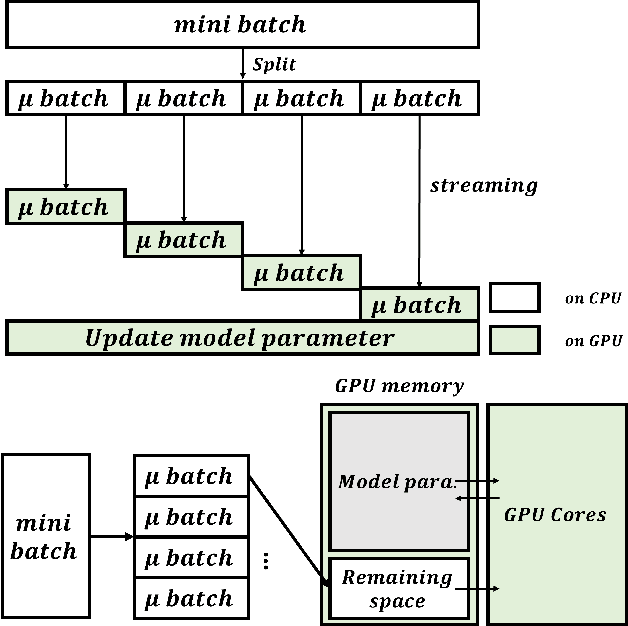
The size of the deep learning models has greatly increased over the past decade. Such models are difficult to train using a large batch size, because commodity machines do not have enough memory to accommodate both the model and a large data size. The batch size is one of the hyper-parameters used in the training model, and it is dependent on and is limited by the target machine memory capacity and it is dependent on the remaining memory after the model is uploaded. A smaller batch size usually results in performance degradation. This paper proposes a framework called Micro-Batch Streaming (MBS) to address this problem. This method helps deep learning models to train by providing a batch streaming algorithm that splits a batch into the appropriate size for the remaining memory size and streams them sequentially to the target machine. A loss normalization algorithm based on the gradient accumulation is used to maintain the performance. The purpose of our method is to allow deep learning models to train using mathematically determined optimal batch sizes that cannot fit into the memory of a target system.
Introduction to Quantum Reinforcement Learning: Theory and PennyLane-based Implementation
Aug 16, 2021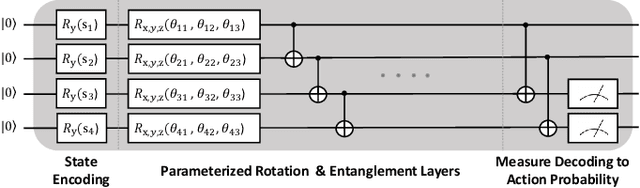
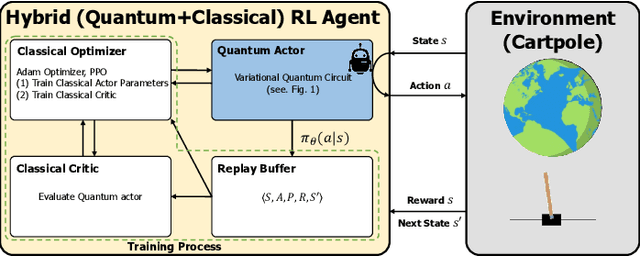

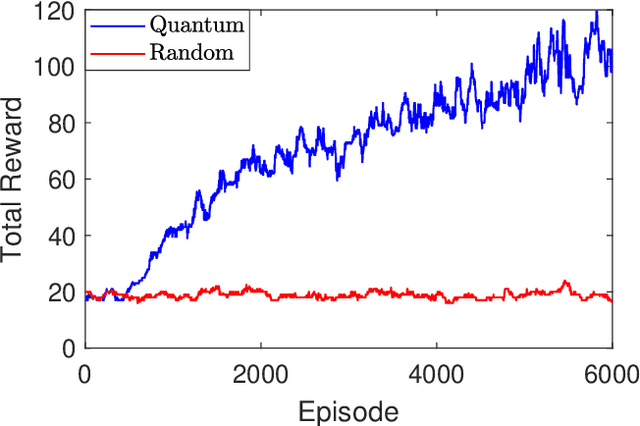
The emergence of quantum computing enables for researchers to apply quantum circuit on many existing studies. Utilizing quantum circuit and quantum differential programming, many research are conducted such as \textit{Quantum Machine Learning} (QML). In particular, quantum reinforcement learning is a good field to test the possibility of quantum machine learning, and a lot of research is being done. This work will introduce the concept of quantum reinforcement learning using a variational quantum circuit, and confirm its possibility through implementation and experimentation. We will first present the background knowledge and working principle of quantum reinforcement learning, and then guide the implementation method using the PennyLane library. We will also discuss the power and possibility of quantum reinforcement learning from the experimental results obtained through this work.
Contextual Skipgram: Training Word Representation Using Context Information
Feb 17, 2021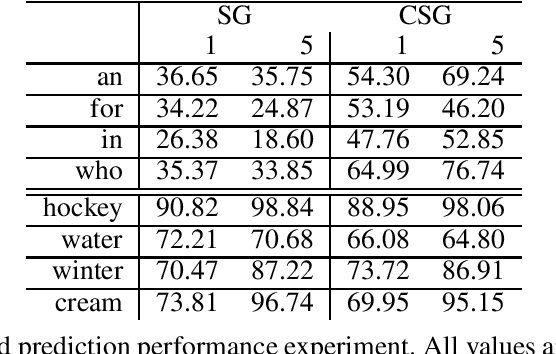
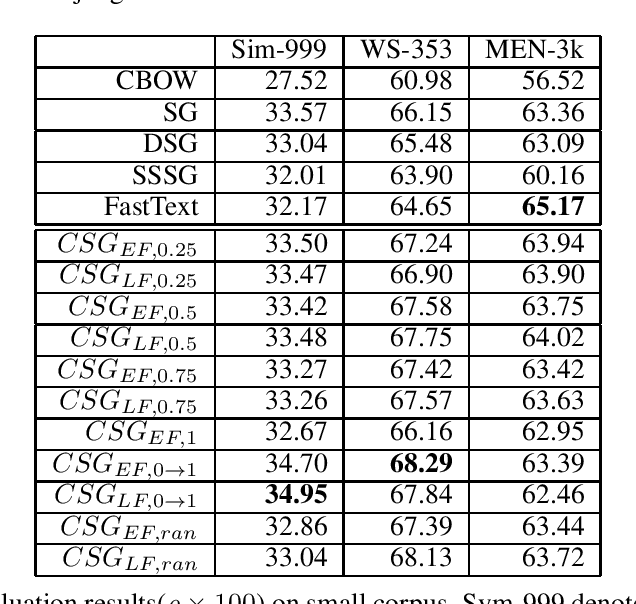
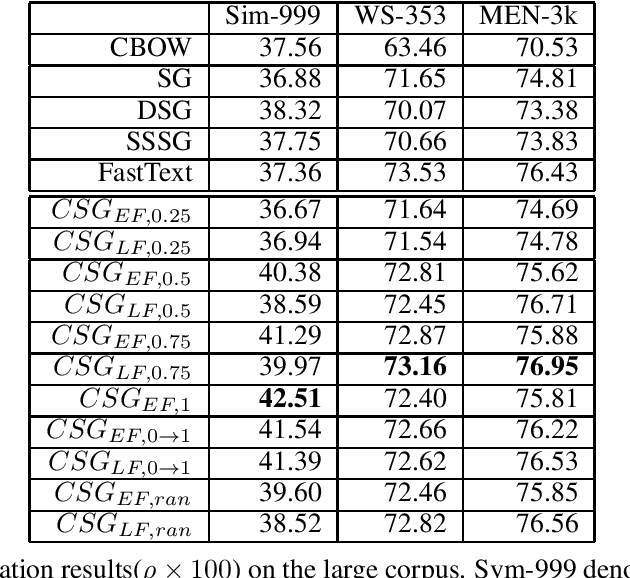
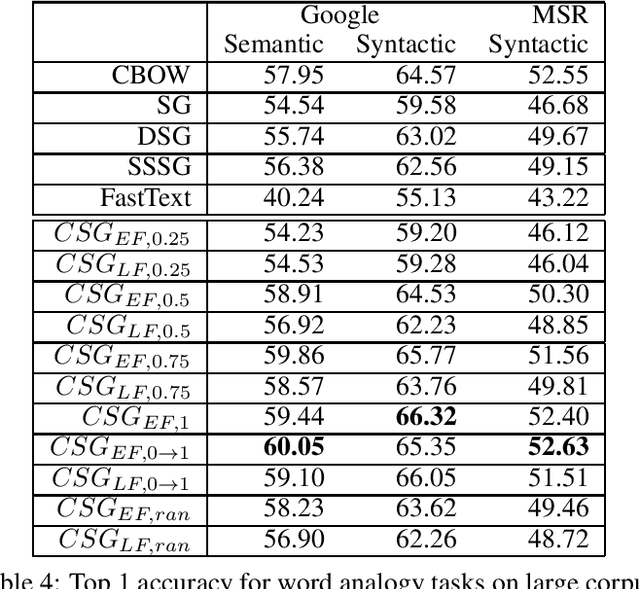
The skip-gram (SG) model learns word representation by predicting the words surrounding a center word from unstructured text data. However, not all words in the context window contribute to the meaning of the center word. For example, less relevant words could be in the context window, hindering the SG model from learning a better quality representation. In this paper, we propose an enhanced version of the SG that leverages context information to produce word representation. The proposed model, Contextual Skip-gram, is designed to predict contextual words with both the center words and the context information. This simple idea helps to reduce the impact of irrelevant words on the training process, thus enhancing the final performance
Privacy-Preserving Deep Learning Computation for Geo-Distributed Medical Big-Data Platforms
Jan 09, 2020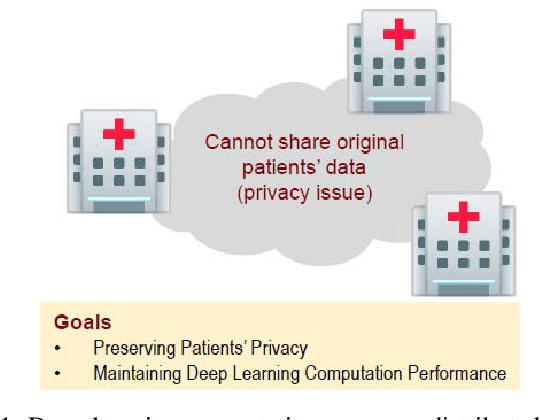
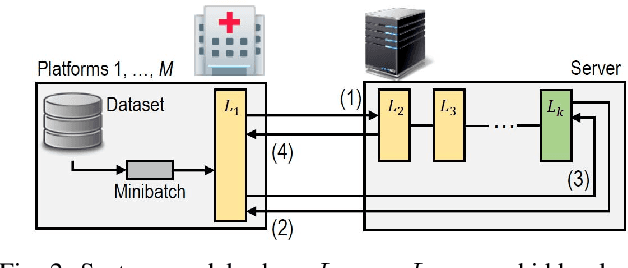
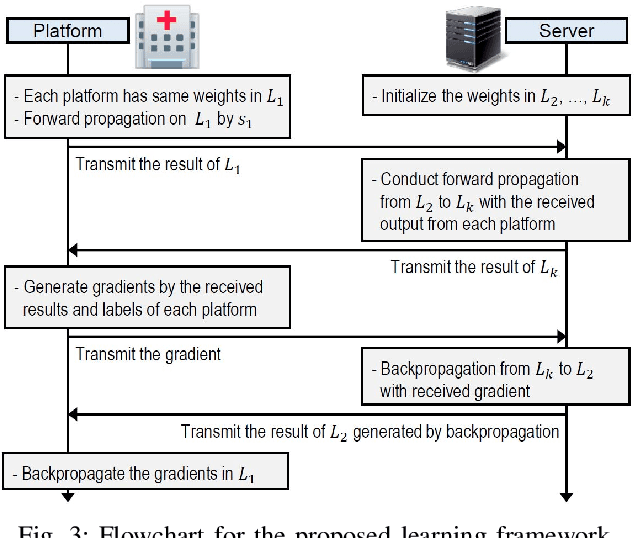
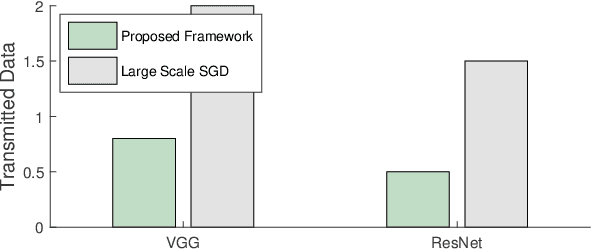
This paper proposes a distributed deep learning framework for privacy-preserving medical data training. In order to avoid patients' data leakage in medical platforms, the hidden layers in the deep learning framework are separated and where the first layer is kept in platform and others layers are kept in a centralized server. Whereas keeping the original patients' data in local platforms maintain their privacy, utilizing the server for subsequent layers improves learning performance by using all data from each platform during training.