 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Arbitration Control for an Ensemble of Diversified DQN variants in Continual Reinforcement Learning
Sep 05, 2025Deep reinforcement learning (RL) models, despite their efficiency in learning an optimal policy in static environments, easily loses previously learned knowledge (i.e., catastrophic forgetting). It leads RL models to poor performance in continual reinforcement learning (CRL) scenarios. To address this, we present an arbitration control mechanism over an ensemble of RL agents. It is motivated by and closely aligned with how humans make decisions in a CRL context using an arbitration control of multiple RL agents in parallel as observed in the prefrontal cortex. We integrated two key ideas into our model: (1) an ensemble of RLs (i.e., DQN variants) explicitly trained to have diverse value functions and (2) an arbitration control that prioritizes agents with higher reliability (i.e., less error) in recent trials. We propose a framework for CRL, an Arbitration Control for an Ensemble of Diversified DQN variants (ACED-DQN). We demonstrate significant performance improvements in both static and continual environments, supported by empirical evidence showing the effectiveness of arbitration control over diversified DQNs during training. In this work, we introduced a framework that enables RL agents to continuously learn, with inspiration from the human brain.
MOGAM: A Multimodal Object-oriented Graph Attention Model for Depression Detection
Mar 21, 2024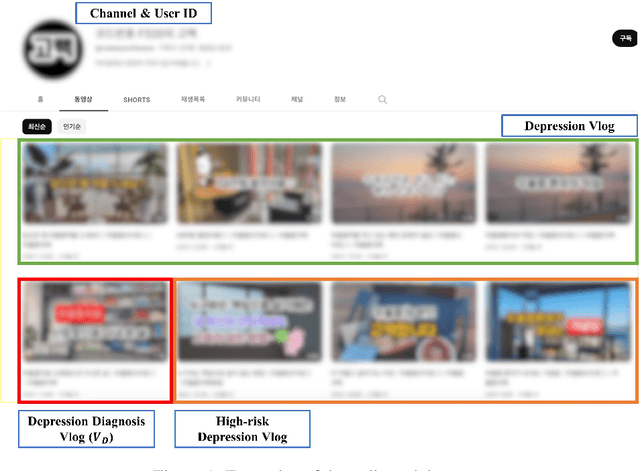
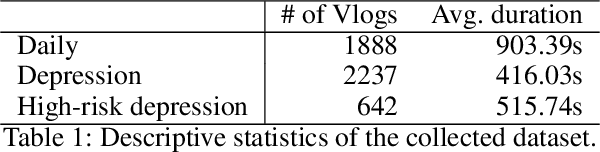
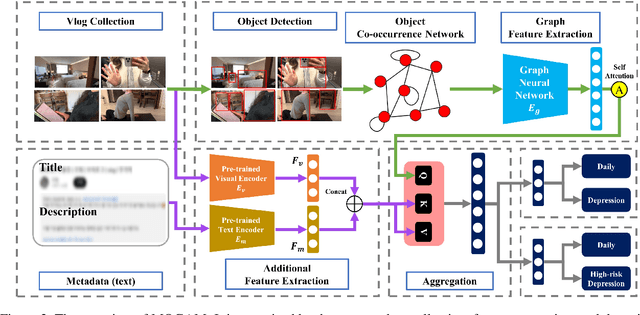
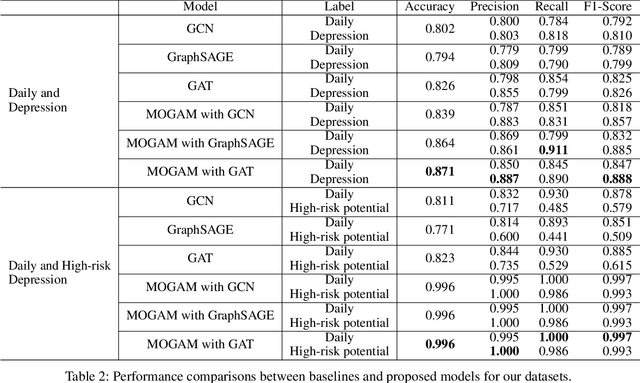
Early detection plays a crucial role in the treatment of depression. Therefore, numerous studies have focused on social media platforms, where individuals express their emotions, aiming to achieve early detection of depression. However, the majority of existing approaches often rely on specific features, leading to limited scalability across different types of social media datasets, such as text, images, or videos. To overcome this limitation, we introduce a Multimodal Object-Oriented Graph Attention Model (MOGAM), which can be applied to diverse types of data, offering a more scalable and versatile solution. Furthermore, to ensure that our model can capture authentic symptoms of depression, we only include vlogs from users with a clinical diagnosis. To leverage the diverse features of vlogs, we adopt a multimodal approach and collect additional metadata such as the title, description, and duration of the vlogs. To effectively aggregate these multimodal features, we employed a cross-attention mechanism. MOGAM achieved an accuracy of 0.871 and an F1-score of 0.888. Moreover, to validate the scalability of MOGAM, we evaluated its performance with a benchmark dataset and achieved comparable results with prior studies (0.61 F1-score). In conclusion, we believe that the proposed model, MOGAM, is an effective solution for detecting depression in social media, offering potential benefits in the early detection and treatment of this mental health condition.
SWIPT-enabled NOMA in Distributed Antenna System with Imperfect Channel State Information for Max-Sum-Rate and Max-Min Fairness
Mar 18, 2022



Motivated by the fact that the data rate of non-orthogonal multiple access (NOMA) can be greatly increased with the help of the distributed antenna system (DAS), we presents a framework in which the DAS contributes not only to the data rate but also the energy harvesting of simultaneous wireless information and power transfer (SWIPT) enabled NOMA. This study considers the sum-rate maximization problem and the max-min fairness problem for SWIPT-enabled NOMA in DAS and proposes two different schemes of power splitting and power allocation for SWIPT and NOMA, respectively, with imperfect channel state information (CSI). Numerical results validate the theoretical findings and demonstrate that the proposed framework of using SWIPT-enabled NOMA in DAS achieves the higher data rates than the existing SWIPT-enabled NOMA while guaranteeing the minimum harvested energy.
Contextual Skipgram: Training Word Representation Using Context Information
Feb 17, 2021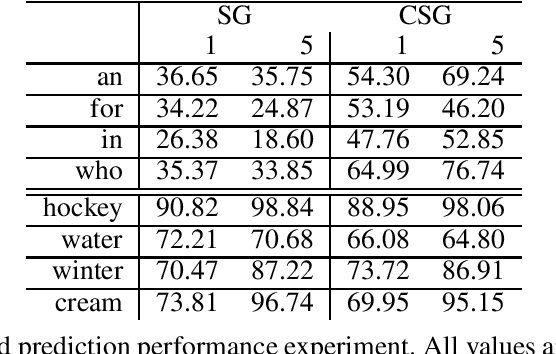
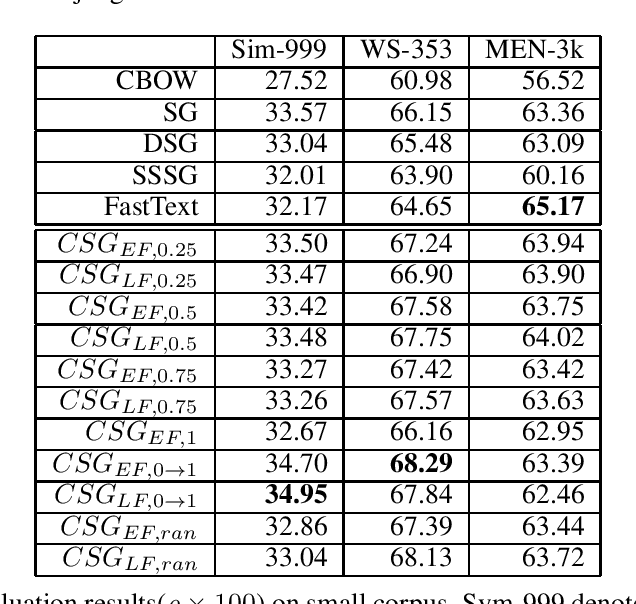
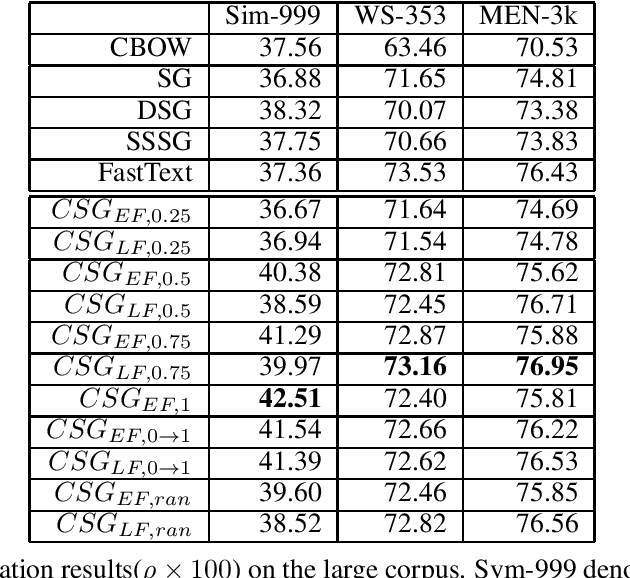
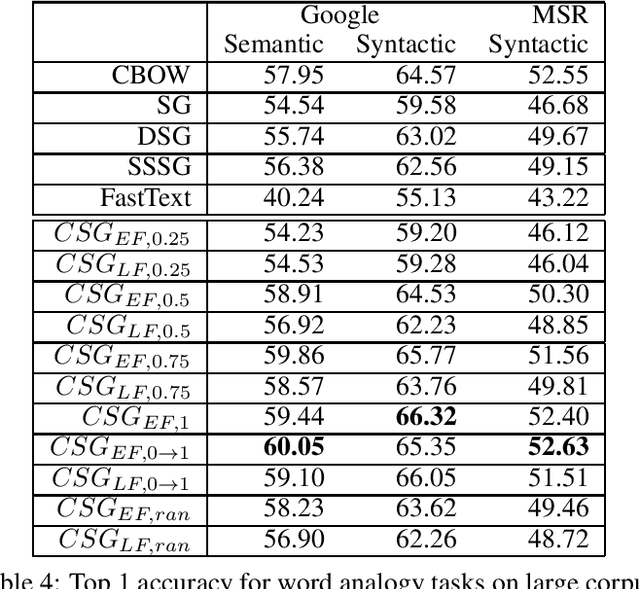
The skip-gram (SG) model learns word representation by predicting the words surrounding a center word from unstructured text data. However, not all words in the context window contribute to the meaning of the center word. For example, less relevant words could be in the context window, hindering the SG model from learning a better quality representation. In this paper, we propose an enhanced version of the SG that leverages context information to produce word representation. The proposed model, Contextual Skip-gram, is designed to predict contextual words with both the center words and the context information. This simple idea helps to reduce the impact of irrelevant words on the training process, thus enhancing the final performance
On the Reliability and Generalizability of Brain-inspired Reinforcement Learning Algorithms
Jul 09, 2020



Although deep RL models have shown a great potential for solving various types of tasks with minimal supervision, several key challenges remain in terms of learning from limited experience, adapting to environmental changes, and generalizing learning from a single task. Recent evidence in decision neuroscience has shown that the human brain has an innate capacity to resolve these issues, leading to optimism regarding the development of neuroscience-inspired solutions toward sample-efficient, and generalizable RL algorithms. We show that the computational model combining model-based and model-free control, which we term the prefrontal RL, reliably encodes the information of high-level policy that humans learned, and this model can generalize the learned policy to a wide range of tasks. First, we trained the prefrontal RL, and deep RL algorithms on 82 subjects' data, collected while human participants were performing two-stage Markov decision tasks, in which we manipulated the goal, state-transition uncertainty and state-space complexity. In the reliability test, which includes the latent behavior profile and the parameter recoverability test, we showed that the prefrontal RL reliably learned the latent policies of the humans, while all the other models failed. Second, to test the ability to generalize what these models learned from the original task, we situated them in the context of environmental volatility. Specifically, we ran large-scale simulations with 10 Markov decision tasks, in which latent context variables change over time. Our information-theoretic analysis showed that the prefrontal RL showed the highest level of adaptability and episodic encoding efficacy. This is the first attempt to formally test the possibility that computational models mimicking the way the brain solves general problems can lead to practical solutions to key challenges in machine learning.