 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavFormer: IGRF Forecasting in Moving Coordinate Frames
Jan 14, 2026Triad magnetometer components change with sensor attitude even when the IGRF total intensity target stays invariant. NavFormer forecasts this invariant target with rotation invariant scalar features and a Canonical SPD module that stabilizes the spectrum of window level second moments of the triads without sign discontinuities. The module builds a canonical frame from a Gram matrix per window and applies state dependent spectral scaling in the original coordinates. Experiments across five flights show lower error than strong baselines in standard training, few shot training, and zero shot transfer. The code is available at: https://anonymous.4open.science/r/NavFormer-Robust-IGRF-Forecasting-for-Autonomous-Navigators-0765
Breaking Chains: Unraveling the Links in Multi-Hop Knowledge Unlearning
Oct 17, 2024
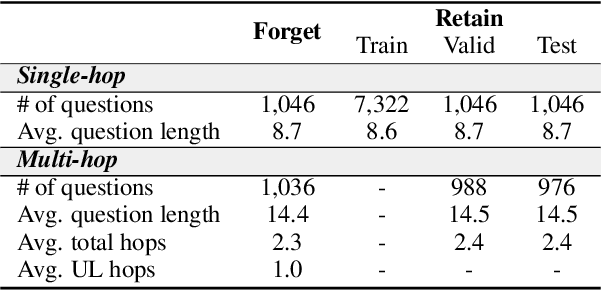
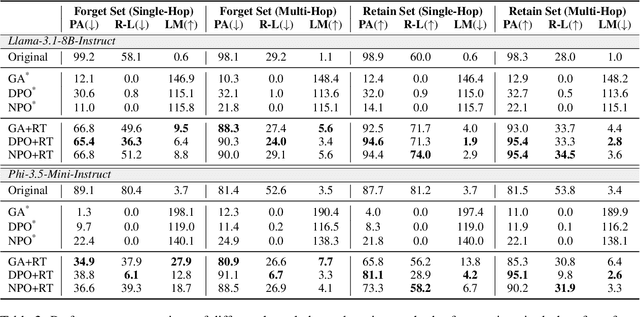

Large language models (LLMs) serve as giant information stores, often including personal or copyrighted data, and retraining them from scratch is not a viable option. This has led to the development of various fast, approximate unlearning techniques to selectively remove knowledge from LLMs. Prior research has largely focused on minimizing the probabilities of specific token sequences by reversing the language modeling objective. However, these methods still leave LLMs vulnerable to adversarial attacks that exploit indirect references. In this work, we examine the limitations of current unlearning techniques in effectively erasing a particular type of indirect prompt: multi-hop queries. Our findings reveal that existing methods fail to completely remove multi-hop knowledge when one of the intermediate hops is unlearned. To address this issue, we propose MUNCH, a simple uncertainty-based approach that breaks down multi-hop queries into subquestions and leverages the uncertainty of the unlearned model in final decision-making. Empirical results demonstrate the effectiveness of our framework, and MUNCH can be easily integrated with existing unlearning techniques, making it a flexible and useful solution for enhancing unlearning processes.
Online-Score-Aided Federated Learning: Taming the Resource Constraints in Wireless Networks
Aug 12, 2024While FL is a widely popular distributed ML strategy that protects data privacy, time-varying wireless network parameters and heterogeneous system configurations of the wireless device pose significant challenges. Although the limited radio and computational resources of the network and the clients, respectively, are widely acknowledged, two critical yet often ignored aspects are (a) wireless devices can only dedicate a small chunk of their limited storage for the FL task and (b) new training samples may arrive in an online manner in many practical wireless applications. Therefore, we propose a new FL algorithm called OSAFL, specifically designed to learn tasks relevant to wireless applications under these practical considerations. Since it has long been proven that under extreme resource constraints, clients may perform an arbitrary number of local training steps, which may lead to client drift under statistically heterogeneous data distributions, we leverage normalized gradient similarities and exploit weighting clients' updates based on optimized scores that facilitate the convergence rate of the proposed OSAFL algorithm. Our extensive simulation results on two different tasks -- each with three different datasets -- with four popular ML models validate the effectiveness of OSAFL compared to six existing state-of-the-art FL baselines.
Protecting Privacy Through Approximating Optimal Parameters for Sequence Unlearning in Language Models
Jun 20, 2024Although language models (LMs) demonstrate exceptional capabilities on various tasks, they are potentially vulnerable to extraction attacks, which represent a significant privacy risk. To mitigate the privacy concerns of LMs, machine unlearning has emerged as an important research area, which is utilized to induce the LM to selectively forget about some of its training data. While completely retraining the model will guarantee successful unlearning and privacy assurance, it is impractical for LMs, as it would be time-consuming and resource-intensive. Prior works efficiently unlearn the target token sequences, but upon subsequent iterations, the LM displays significant degradation in performance. In this work, we propose Privacy Protection via Optimal Parameters (POP), a novel unlearning method that effectively forgets the target token sequences from the pretrained LM by applying optimal gradient updates to the parameters. Inspired by the gradient derivation of complete retraining, we approximate the optimal training objective that successfully unlearns the target sequence while retaining the knowledge from the rest of the training data. Experimental results demonstrate that POP exhibits remarkable retention performance post-unlearning across 9 classification and 4 dialogue benchmarks, outperforming the state-of-the-art by a large margin. Furthermore, we introduce Remnant Memorization Accuracy that quantifies privacy risks based on token likelihood and validate its effectiveness through both qualitative and quantitative analyses.
SNAP: Unlearning Selective Knowledge in Large Language Models with Negative Instructions
Jun 18, 2024Instruction-following large language models (LLMs), such as ChatGPT, have become increasingly popular with the general audience, many of whom are incorporating them into their daily routines. However, these LLMs inadvertently disclose personal or copyrighted information, which calls for a machine unlearning method to remove selective knowledge. Previous attempts sought to forget the link between the target information and its associated entities, but it rather led to generating undesirable responses about the target, compromising the end-user experience. In this work, we propose SNAP, an innovative framework designed to selectively unlearn information by 1) training an LLM with negative instructions to generate obliterated responses, 2) augmenting hard positives to retain the original LLM performance, and 3) applying the novel Wasserstein regularization to ensure adequate deviation from the initial weights of the LLM. We evaluate our framework on various NLP benchmarks and demonstrate that our approach retains the original LLM capabilities, while successfully unlearning the specified information.
Cross-Lingual Unlearning of Selective Knowledge in Multilingual Language Models
Jun 18, 2024



Pretrained language models memorize vast amounts of information, including private and copyrighted data, raising significant safety concerns. Retraining these models after excluding sensitive data is prohibitively expensive, making machine unlearning a viable, cost-effective alternative. Previous research has focused on machine unlearning for monolingual models, but we find that unlearning in one language does not necessarily transfer to others. This vulnerability makes models susceptible to low-resource language attacks, where sensitive information remains accessible in less dominant languages. This paper presents a pioneering approach to machine unlearning for multilingual language models, selectively erasing information across different languages while maintaining overall performance. Specifically, our method employs an adaptive unlearning scheme that assigns language-dependent weights to address different language performances of multilingual language models. Empirical results demonstrate the effectiveness of our framework compared to existing unlearning baselines, setting a new standard for secure and adaptable multilingual language models.
PairEval: Open-domain Dialogue Evaluation with Pairwise Comparison
Apr 01, 2024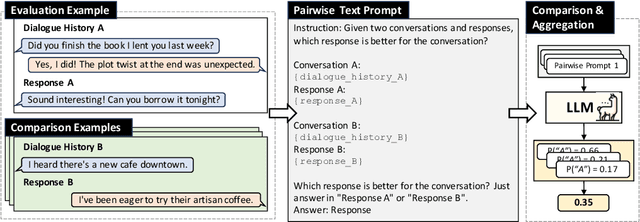



Building a reliable and automated evaluation metric is a necessary but challenging problem for open-domain dialogue systems. Recent studies proposed evaluation metrics that assess generated responses by considering their relevance to previous dialogue histories. Although effective, these metrics evaluate individual responses directly rather than considering their relative quality compared to other responses. To handle this, we propose PairEval, a novel dialogue evaluation metric for assessing responses by comparing their quality against responses in different conversations. PairEval is built on top of open-sourced and moderate-size language models, and we make them specialized in pairwise comparison between dialogue responses. Extensive experiments on multiple benchmarks demonstrate that our metric exhibits a higher correlation with human judgments than baseline metrics. We also find that the proposed comparative metric is more robust in detecting common failures from open-domain dialogue systems, including repetition and speaker insensitivity.
SimCKP: Simple Contrastive Learning of Keyphrase Representations
Oct 12, 2023
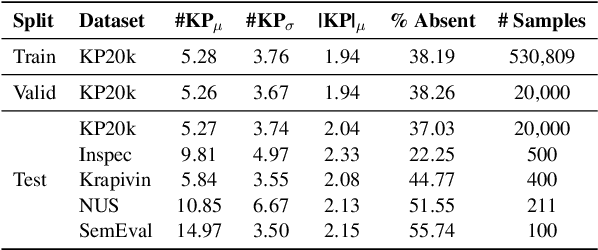
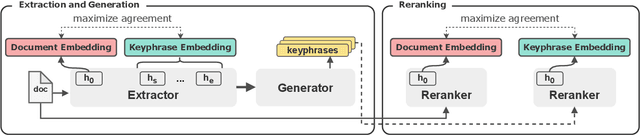
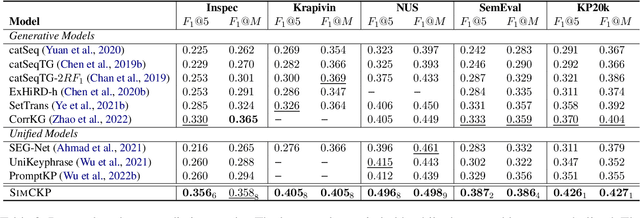
Keyphrase generation (KG) aims to generate a set of summarizing words or phrases given a source document, while keyphrase extraction (KE) aims to identify them from the text. Because the search space is much smaller in KE, it is often combined with KG to predict keyphrases that may or may not exist in the corresponding document. However, current unified approaches adopt sequence labeling and maximization-based generation that primarily operate at a token level, falling short in observing and scoring keyphrases as a whole. In this work, we propose SimCKP, a simple contrastive learning framework that consists of two stages: 1) An extractor-generator that extracts keyphrases by learning context-aware phrase-level representations in a contrastive manner while also generating keyphrases that do not appear in the document; 2) A reranker that adapts scores for each generated phrase by likewise aligning their representations with the corresponding document. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed approach, which outperforms the state-of-the-art models by a significant margin.
PRiSM: Enhancing Low-Resource Document-Level Relation Extraction with Relation-Aware Score Calibration
Sep 25, 2023



Document-level relation extraction (DocRE) aims to extract relations of all entity pairs in a document. A key challenge in DocRE is the cost of annotating such data which requires intensive human effort. Thus, we investigate the case of DocRE in a low-resource setting, and we find that existing models trained on low data overestimate the NA ("no relation") label, causing limited performance. In this work, we approach the problem from a calibration perspective and propose PRiSM, which learns to adapt logits based on relation semantic information. We evaluate our method on three DocRE datasets and demonstrate that integrating existing models with PRiSM improves performance by as much as 26.38 F1 score, while the calibration error drops as much as 36 times when trained with about 3% of data. The code is publicly available at https://github.com/brightjade/PRiSM.
Two Tales of Platoon Intelligence for Autonomous Mobility Control: Enabling Deep Learning Recipes
Jul 19, 2023This paper presents the deep learning-based recent achievements to resolve the problem of autonomous mobility control and efficient resource management of autonomous vehicles and UAVs, i.e., (i) multi-agent reinforcement learning (MARL), and (ii) neural Myerson auction. Representatively, communication network (CommNet), which is one of the most popular MARL algorithms, is introduced to enable multiple agents to take actions in a distributed manner for their shared goals by training all agents' states and actions in a single neural network. Moreover, the neural Myerson auction guarantees trustfulness among multiple agents as well as achieves the optimal revenue of highly dynamic systems. Therefore, we survey the recent studies on autonomous mobility control based on MARL and neural Myerson auction. Furthermore, we emphasize that integration of MARL and neural Myerson auction is expected to be critical for efficient and trustful autonomous mobility services.