 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Chains: Unraveling the Links in Multi-Hop Knowledge Unlearning
Paper and Code

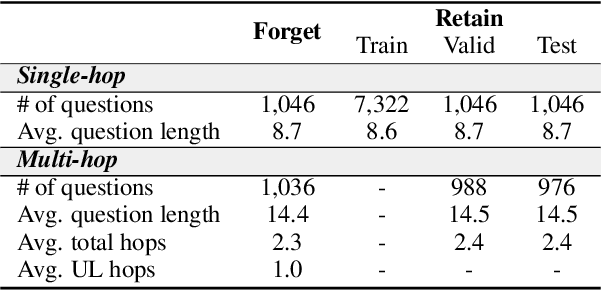
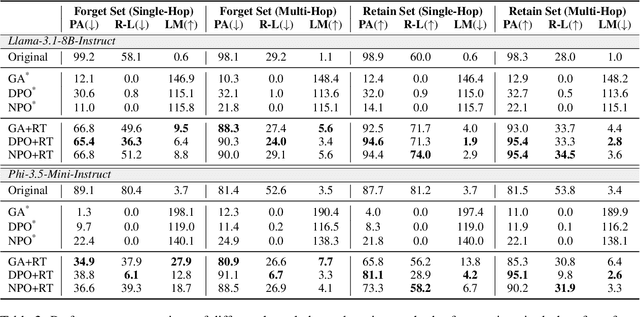

Large language models (LLMs) serve as giant information stores, often including personal or copyrighted data, and retraining them from scratch is not a viable option. This has led to the development of various fast, approximate unlearning techniques to selectively remove knowledge from LLMs. Prior research has largely focused on minimizing the probabilities of specific token sequences by reversing the language modeling objective. However, these methods still leave LLMs vulnerable to adversarial attacks that exploit indirect references. In this work, we examine the limitations of current unlearning techniques in effectively erasing a particular type of indirect prompt: multi-hop queries. Our findings reveal that existing methods fail to completely remove multi-hop knowledge when one of the intermediate hops is unlearned. To address this issue, we propose MUNCH, a simple uncertainty-based approach that breaks down multi-hop queries into subquestions and leverages the uncertainty of the unlearned model in final decision-making. Empirical results demonstrate the effectiveness of our framework, and MUNCH can be easily integrated with existing unlearning techniques, making it a flexible and useful solution for enhancing unlearning processes.