 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveWeb-IE: A Benchmark For Online Web Information Extraction
Mar 14, 2026Web information extraction (WIE) is the task of automatically extracting data from web pages, offering high utility for various applications. The evaluation of WIE systems has traditionally relied on benchmarks built from HTML snapshots captured at a single point in time. However, this offline evaluation paradigm fails to account for the temporally evolving nature of the web; consequently, performance on these static benchmarks often fails to generalize to dynamic real-world scenarios. To bridge this gap, we introduce \dataset, a new benchmark designed for evaluating WIE systems directly against live websites. Based on trusted and permission-granted websites, we curate natural language queries that require information extraction of various data categories, such as text, images, and hyperlinks. We further design these queries to represent four levels of complexity, based on the number and cardinality of attributes to be extracted, enabling a granular assessment of WIE systems. In addition, we propose Visual Grounding Scraper (VGS), a novel multi-stage agentic framework that mimics human cognitive processes by visually narrowing down web page content to extract desired information. Extensive experiments across diverse backbone models demonstrate the effectiveness and robustness of VGS. We believe that this study lays the foundation for developing practical and robust WIE systems.
Evaluating and Improving Automatic Speech Recognition Systems for Korean Meteorological Experts
Oct 24, 2024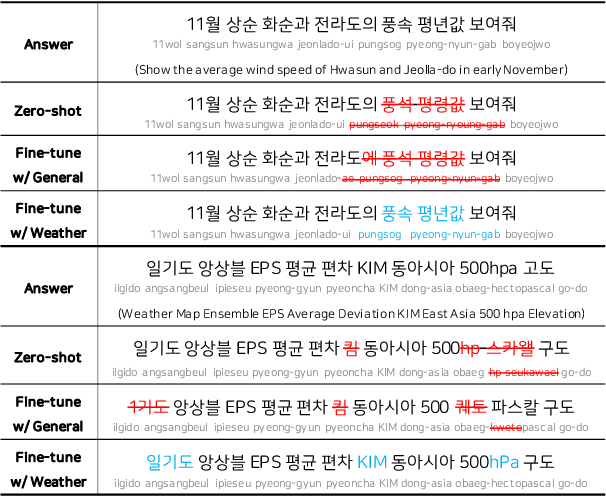



This paper explores integrating Automatic Speech Recognition (ASR) into natural language query systems to improve weather forecasting efficiency for Korean meteorologists. We address challenges in developing ASR systems for the Korean weather domain, specifically specialized vocabulary and Korean linguistic intricacies. To tackle these issues, we constructed an evaluation dataset of spoken queries recorded by native Korean speakers. Using this dataset, we assessed various configurations of a multilingual ASR model family, identifying performance limitations related to domain-specific terminology. We then implemented a simple text-to-speech-based data augmentation method, which improved the recognition of specialized terms while maintaining general-domain performance. Our contributions include creating a domain-specific dataset, comprehensive ASR model evaluations, and an effective augmentation technique. We believe our work provides a foundation for future advancements in ASR for the Korean weather forecasting domain.
Breaking Chains: Unraveling the Links in Multi-Hop Knowledge Unlearning
Oct 17, 2024
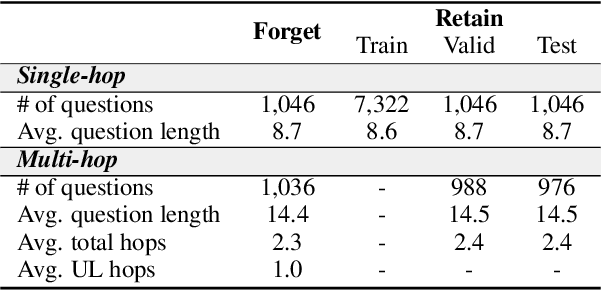
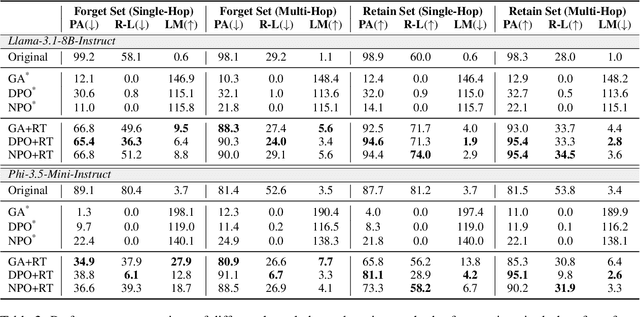

Large language models (LLMs) serve as giant information stores, often including personal or copyrighted data, and retraining them from scratch is not a viable option. This has led to the development of various fast, approximate unlearning techniques to selectively remove knowledge from LLMs. Prior research has largely focused on minimizing the probabilities of specific token sequences by reversing the language modeling objective. However, these methods still leave LLMs vulnerable to adversarial attacks that exploit indirect references. In this work, we examine the limitations of current unlearning techniques in effectively erasing a particular type of indirect prompt: multi-hop queries. Our findings reveal that existing methods fail to completely remove multi-hop knowledge when one of the intermediate hops is unlearned. To address this issue, we propose MUNCH, a simple uncertainty-based approach that breaks down multi-hop queries into subquestions and leverages the uncertainty of the unlearned model in final decision-making. Empirical results demonstrate the effectiveness of our framework, and MUNCH can be easily integrated with existing unlearning techniques, making it a flexible and useful solution for enhancing unlearning processes.
Evaluating Visual and Cultural Interpretation: The K-Viscuit Benchmark with Human-VLM Collaboration
Jun 24, 2024To create culturally inclusive vision-language models (VLMs), the foremost requirement is developing a test benchmark that can diagnose the models' ability to respond to questions reflecting cultural elements. This paper addresses the necessity for such benchmarks, noting that existing research has relied on human annotators' manual efforts, which impedes diversity and efficiency. We propose a semi-automated pipeline for constructing cultural VLM benchmarks to enhance diversity and efficiency. This pipeline leverages human-VLM collaboration, where VLMs generate questions based on guidelines, human-annotated examples, and image-wise relevant knowledge, which are then reviewed by native speakers for quality and cultural relevance. The effectiveness of our adaptable pipeline is demonstrated through a specific application: creating a dataset tailored to Korean culture, dubbed K-Viscuit. The resulting benchmark features two types of questions: Type 1 questions measure visual recognition abilities, while Type 2 assess fine-grained visual reasoning skills. This ensures a thorough diagnosis of VLM models across various aspects. Our evaluation using K-Viscuit revealed that open-source models notably lag behind proprietary models in understanding Korean culture, highlighting areas for improvement. We provided diverse analyses of VLM performance across different cultural aspects. Besides, we explored the potential of incorporating external knowledge retrieval to enhance the generation process, suggesting future directions for improving cultural interpretation ability of VLMs. Our dataset and code will be made publicly available.
PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments
Jun 18, 2024


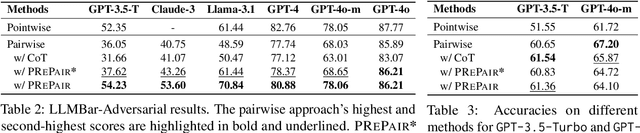
Pairwise evaluation using large language models (LLMs) is widely used for evaluating natural language generation (NLG) tasks. However, the reliability of LLMs is often compromised by biases, such as favoring verbosity and authoritative tone. In the study, we focus on the comparison of two LLM-based evaluation approaches, pointwise and pairwise. Our findings demonstrate that pointwise evaluators exhibit more robustness against undesirable preferences. Further analysis reveals that pairwise evaluators can accurately identify the shortcomings of low-quality outputs even when their judgment is incorrect. These results indicate that LLMs are more severely influenced by their bias in a pairwise evaluation setup. To mitigate this, we propose a hybrid method that integrates pointwise reasoning into pairwise evaluation. Experimental results show that our method enhances the robustness of pairwise evaluators against adversarial samples while preserving accuracy on normal samples.
Can Tool-augmented Large Language Models be Aware of Incomplete Conditions?
Jun 18, 2024



Recent advancements in integrating large language models (LLMs) with tools have allowed the models to interact with real-world environments. However, these tool-augmented LLMs often encounter incomplete scenarios when users provide partial information or the necessary tools are unavailable. Recognizing and managing such scenarios is crucial for LLMs to ensure their reliability, but this exploration remains understudied. This study examines whether LLMs can identify incomplete conditions and appropriately determine when to refrain from using tools. To this end, we address a dataset by manipulating instances from two datasets by removing necessary tools or essential information for tool invocation. We confirm that most LLMs are challenged to identify the additional information required to utilize specific tools and the absence of appropriate tools. Our research can contribute to advancing reliable LLMs by addressing scenarios that commonly arise during interactions between humans and LLMs.
Translation Deserves Better: Analyzing Translation Artifacts in Cross-lingual Visual Question Answering
Jun 04, 2024
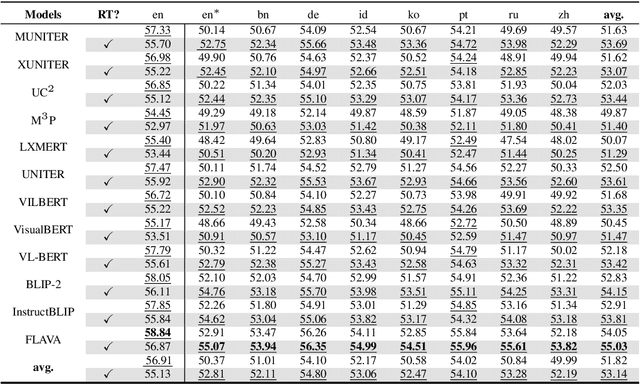


Building a reliable visual question answering~(VQA) system across different languages is a challenging problem, primarily due to the lack of abundant samples for training. To address this challenge, recent studies have employed machine translation systems for the cross-lingual VQA task. This involves translating the evaluation samples into a source language (usually English) and using monolingual models (i.e., translate-test). However, our analysis reveals that translated texts contain unique characteristics distinct from human-written ones, referred to as translation artifacts. We find that these artifacts can significantly affect the models, confirmed by extensive experiments across diverse models, languages, and translation processes. In light of this, we present a simple data augmentation strategy that can alleviate the adverse impacts of translation artifacts.
PairEval: Open-domain Dialogue Evaluation with Pairwise Comparison
Apr 01, 2024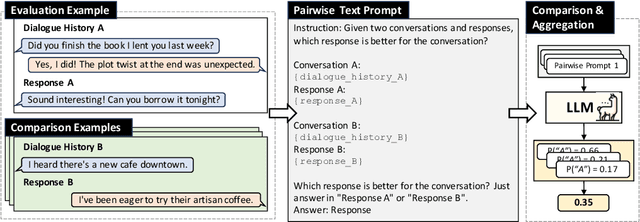



Building a reliable and automated evaluation metric is a necessary but challenging problem for open-domain dialogue systems. Recent studies proposed evaluation metrics that assess generated responses by considering their relevance to previous dialogue histories. Although effective, these metrics evaluate individual responses directly rather than considering their relative quality compared to other responses. To handle this, we propose PairEval, a novel dialogue evaluation metric for assessing responses by comparing their quality against responses in different conversations. PairEval is built on top of open-sourced and moderate-size language models, and we make them specialized in pairwise comparison between dialogue responses. Extensive experiments on multiple benchmarks demonstrate that our metric exhibits a higher correlation with human judgments than baseline metrics. We also find that the proposed comparative metric is more robust in detecting common failures from open-domain dialogue systems, including repetition and speaker insensitivity.
Learning to Diversify Neural Text Generation via Degenerative Model
Sep 22, 2023



Neural language models often fail to generate diverse and informative texts, limiting their applicability in real-world problems. While previous approaches have proposed to address these issues by identifying and penalizing undesirable behaviors (e.g., repetition, overuse of frequent words) from language models, we propose an alternative approach based on an observation: models primarily learn attributes within examples that are likely to cause degeneration problems. Based on this observation, we propose a new approach to prevent degeneration problems by training two models. Specifically, we first train a model that is designed to amplify undesirable patterns. We then enhance the diversity of the second model by focusing on patterns that the first model fails to learn. Extensive experiments on two tasks, namely language modeling and dialogue generation, demonstrate the effectiveness of our approach.
DEnsity: Open-domain Dialogue Evaluation Metric using Density Estimation
May 08, 2023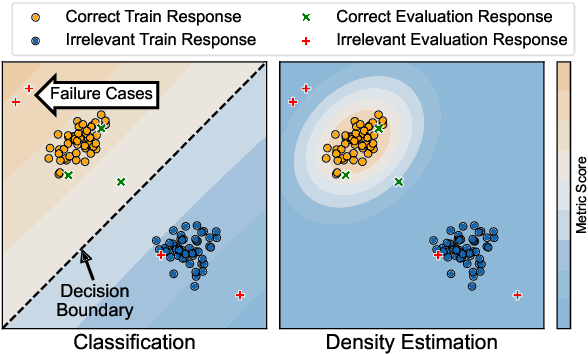



Despite the recent advances in open-domain dialogue systems, building a reliable evaluation metric is still a challenging problem. Recent studies proposed learnable metrics based on classification models trained to distinguish the correct response. However, neural classifiers are known to make overly confident predictions for examples from unseen distributions. We propose DEnsity, which evaluates a response by utilizing density estimation on the feature space derived from a neural classifier. Our metric measures how likely a response would appear in the distribution of human conversations. Moreover, to improve the performance of DEnsity, we utilize contrastive learning to further compress the feature space. Experiments on multiple response evaluation datasets show that DEnsity correlates better with human evaluations than the existing metrics. Our code is available at https://github.com/ddehun/DEnsity.