 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Improving Automatic Speech Recognition Systems for Korean Meteorological Experts
Paper and Code
Oct 24, 2024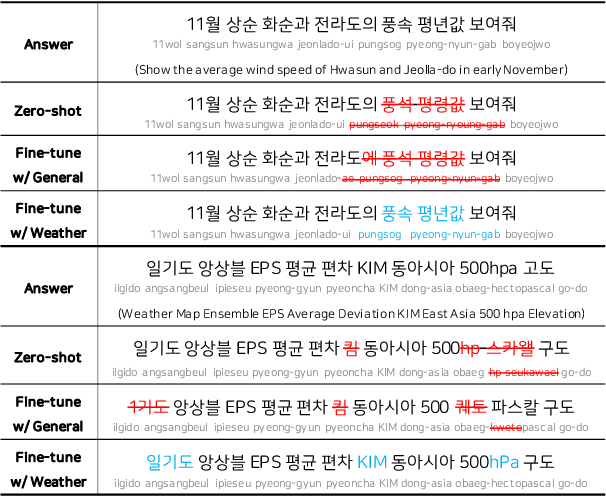



This paper explores integrating Automatic Speech Recognition (ASR) into natural language query systems to improve weather forecasting efficiency for Korean meteorologists. We address challenges in developing ASR systems for the Korean weather domain, specifically specialized vocabulary and Korean linguistic intricacies. To tackle these issues, we constructed an evaluation dataset of spoken queries recorded by native Korean speakers. Using this dataset, we assessed various configurations of a multilingual ASR model family, identifying performance limitations related to domain-specific terminology. We then implemented a simple text-to-speech-based data augmentation method, which improved the recognition of specialized terms while maintaining general-domain performance. Our contributions include creating a domain-specific dataset, comprehensive ASR model evaluations, and an effective augmentation technique. We believe our work provides a foundation for future advancements in ASR for the Korean weather forecasting domain.