 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Deserves Better: Analyzing Translation Artifacts in Cross-lingual Visual Question Answering
Paper and Code

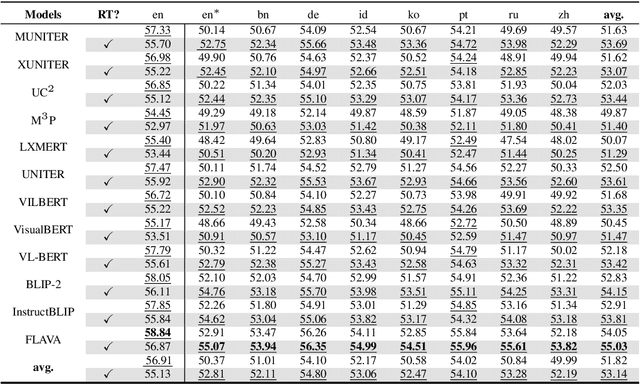


Building a reliable visual question answering~(VQA) system across different languages is a challenging problem, primarily due to the lack of abundant samples for training. To address this challenge, recent studies have employed machine translation systems for the cross-lingual VQA task. This involves translating the evaluation samples into a source language (usually English) and using monolingual models (i.e., translate-test). However, our analysis reveals that translated texts contain unique characteristics distinct from human-written ones, referred to as translation artifacts. We find that these artifacts can significantly affect the models, confirmed by extensive experiments across diverse models, languages, and translation processes. In light of this, we present a simple data augmentation strategy that can alleviate the adverse impacts of translation artifacts.