 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptScope: Characterizing Dataset Bias via Disentangled Visual Concepts
Oct 30, 2025Dataset bias, where data points are skewed to certain concepts, is ubiquitous in machine learning datasets. Yet, systematically identifying these biases is challenging without costly, fine-grained attribute annotations. We present ConceptScope, a scalable and automated framework for analyzing visual datasets by discovering and quantifying human-interpretable concepts using Sparse Autoencoders trained on representations from vision foundation models. ConceptScope categorizes concepts into target, context, and bias types based on their semantic relevance and statistical correlation to class labels, enabling class-level dataset characterization, bias identification, and robustness evaluation through concept-based subgrouping. We validate that ConceptScope captures a wide range of visual concepts, including objects, textures, backgrounds, facial attributes, emotions, and actions, through comparisons with annotated datasets. Furthermore, we show that concept activations produce spatial attributions that align with semantically meaningful image regions. ConceptScope reliably detects known biases (e.g., background bias in Waterbirds) and uncovers previously unannotated ones (e.g, co-occurring objects in ImageNet), offering a practical tool for dataset auditing and model diagnostics.
CytoSAE: Interpretable Cell Embeddings for Hematology
Jul 16, 2025



Sparse autoencoders (SAEs) emerged as a promising tool for mechanistic interpretability of transformer-based foundation models. Very recently, SAEs were also adopted for the visual domain, enabling the discovery of visual concepts and their patch-wise attribution to tokens in the transformer model. While a growing number of foundation models emerged for medical imaging, tools for explaining their inferences are still lacking. In this work, we show the applicability of SAEs for hematology. We propose CytoSAE, a sparse autoencoder which is trained on over 40,000 peripheral blood single-cell images. CytoSAE generalizes to diverse and out-of-domain datasets, including bone marrow cytology, where it identifies morphologically relevant concepts which we validated with medical experts. Furthermore, we demonstrate scenarios in which CytoSAE can generate patient-specific and disease-specific concepts, enabling the detection of pathognomonic cells and localized cellular abnormalities at the patch level. We quantified the effect of concepts on a patient-level AML subtype classification task and show that CytoSAE concepts reach performance comparable to the state-of-the-art, while offering explainability on the sub-cellular level. Source code and model weights are available at https://github.com/dynamical-inference/cytosae.
Sparse autoencoders reveal selective remapping of visual concepts during adaptation
Dec 06, 2024



Adapting foundation models for specific purposes has become a standard approach to build machine learning systems for downstream applications. Yet, it is an open question which mechanisms take place during adaptation. Here we develop a new Sparse Autoencoder (SAE) for the CLIP vision transformer, named PatchSAE, to extract interpretable concepts at granular levels (e.g. shape, color, or semantics of an object) and their patch-wise spatial attributions. We explore how these concepts influence the model output in downstream image classification tasks and investigate how recent state-of-the-art prompt-based adaptation techniques change the association of model inputs to these concepts. While activations of concepts slightly change between adapted and non-adapted models, we find that the majority of gains on common adaptation tasks can be explained with the existing concepts already present in the non-adapted foundation model. This work provides a concrete framework to train and use SAEs for Vision Transformers and provides insights into explaining adaptation mechanisms.
Translation Deserves Better: Analyzing Translation Artifacts in Cross-lingual Visual Question Answering
Jun 04, 2024


Building a reliable visual question answering~(VQA) system across different languages is a challenging problem, primarily due to the lack of abundant samples for training. To address this challenge, recent studies have employed machine translation systems for the cross-lingual VQA task. This involves translating the evaluation samples into a source language (usually English) and using monolingual models (i.e., translate-test). However, our analysis reveals that translated texts contain unique characteristics distinct from human-written ones, referred to as translation artifacts. We find that these artifacts can significantly affect the models, confirmed by extensive experiments across diverse models, languages, and translation processes. In light of this, we present a simple data augmentation strategy that can alleviate the adverse impacts of translation artifacts.
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Nov 06, 2023



While fine-tuning unlocks the potential of a pre-trained model for a specific task, it compromises the model's ability to generalize to out-of-distribution (OOD) datasets. To mitigate this, robust fine-tuning aims to ensure performance on OOD datasets as well as on an in-distribution (ID) dataset for which the model is being tuned. However, another criterion for reliable machine learning (ML), confidence calibration, has been overlooked despite its increasing demand for real-world high-stakes ML applications (e.g., autonomous driving and medical diagnosis). For the first time, we raise concerns about the calibration of fine-tuned vision-language models (VLMs) under distribution shift by showing that naive fine-tuning and even state-of-the-art robust fine-tuning methods hurt the calibration of pre-trained VLMs, especially on OOD datasets. To address this issue, we provide a simple approach, called calibrated robust fine-tuning (CaRot), that incentivizes calibration and robustness on both ID and OOD datasets. Empirical results on ImageNet-1K distribution shift evaluation verify the effectiveness of our method.
PRiSM: Enhancing Low-Resource Document-Level Relation Extraction with Relation-Aware Score Calibration
Sep 25, 2023



Document-level relation extraction (DocRE) aims to extract relations of all entity pairs in a document. A key challenge in DocRE is the cost of annotating such data which requires intensive human effort. Thus, we investigate the case of DocRE in a low-resource setting, and we find that existing models trained on low data overestimate the NA ("no relation") label, causing limited performance. In this work, we approach the problem from a calibration perspective and propose PRiSM, which learns to adapt logits based on relation semantic information. We evaluate our method on three DocRE datasets and demonstrate that integrating existing models with PRiSM improves performance by as much as 26.38 F1 score, while the calibration error drops as much as 36 times when trained with about 3% of data. The code is publicly available at https://github.com/brightjade/PRiSM.
TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Feb 18, 2023This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
AVocaDo: Strategy for Adapting Vocabulary to Downstream Domain
Oct 26, 2021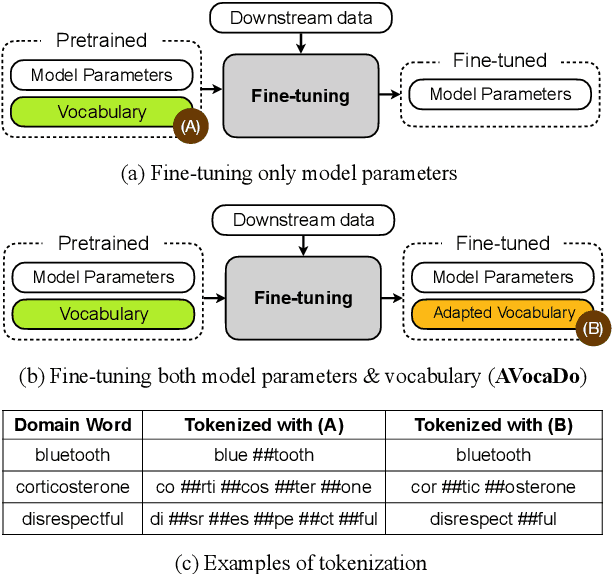

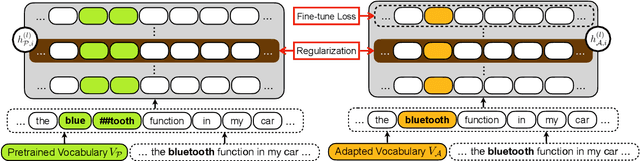
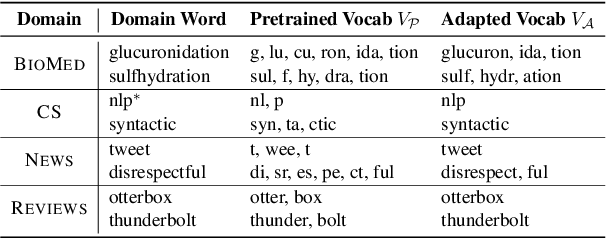
During the fine-tuning phase of transfer learning, the pretrained vocabulary remains unchanged, while model parameters are updated. The vocabulary generated based on the pretrained data is suboptimal for downstream data when domain discrepancy exists. We propose to consider the vocabulary as an optimizable parameter, allowing us to update the vocabulary by expanding it with domain-specific vocabulary based on a tokenization statistic. Furthermore, we preserve the embeddings of the added words from overfitting to downstream data by utilizing knowledge learned from a pretrained language model with a regularization term. Our method achieved consistent performance improvements on diverse domains (i.e., biomedical, computer science, news, and reviews).