 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectCount: Spectrotemporal Counting via Synthetic Signals Improves Large Audio Language Models
Jun 05, 2026Large audio language models (LALMs) extend large language models with an audio encoder and large-scale audio data. However, the scarcity of high-quality annotated audio data remains a fundamental bottleneck for scaling. Through probing signal detectability analysis, we identify fine-grained spectrotemporal perceptual weaknesses in a foundation LALM. To address these challenges, we propose Spectrotemporal Counting (SpectCount), a data-efficient fine-tuning approach based on fully synthetic audio signals generated on-the-fly, without relying on real-world audio, annotations, or pretrained generative models. SpectCount not only resolves the observed weaknesses but also improves performance on diverse auditory benchmarks spanning sound, music, and speech, unseen during fine-tuning. These results suggest that weakness-targeted synthetic signals provide a data-efficient path toward enhanced auditory understanding capabilities in LALMs.
TheraAgent: Multi-Agent Framework with Self-Evolving Memory and Evidence-Calibrated Reasoning for PET Theranostics
Mar 14, 2026PET theranostics is transforming precision oncology, yet treatment response varies substantially; many patients receiving 177Lu-PSMA radioligand therapy (RLT) for metastatic castration-resistant prostate cancer (mCRPC) fail to respond, demanding reliable pre-therapy prediction. While LLM-based agents have shown remarkable potential in complex medical diagnosis, their application to PET theranostic outcome prediction remains unexplored, which faces three key challenges: (1) data and knowledge scarcity: RLT was only FDA-approved in 2022, yielding few training cases and insufficient domain knowledge in general LLMs; (2) heterogeneous information integration: robust prediction hinges on structured knowledge extraction from PET/CT, laboratory tests, and free-text clinical documentation; (3) evidence-grounded reasoning: clinical decisions must be anchored in trial evidence rather than LLM hallucinations. In this paper, we present TheraAgent, to our knowledge, the first agentic framework for PET theranostics, with three core innovations: (1) Multi-Expert Feature Extraction with Confidence-Weighted Consensus, where three specialized experts process heterogeneous inputs with uncertainty quantification; (2) Self-Evolving Agentic Memory (SEA-Mem), which learns prognostic patterns from accumulated cases, enabling case-based reasoning from limited data; (3) Evidence-Calibrated Reasoning, integrating a curated theranostics knowledge base to ground predictions in VISION/TheraP trial evidence. Evaluated on 35 real patients and 400 synthetic cases, TheraAgent achieves 75.7% overall accuracy on real patients and 87.0% on synthetic cases, outperforming MDAgents and MedAgent-Pro by over 20%. These results highlight a promising blueprint for trustworthy AI agents in PET theranostics, enabling trial-calibrated, multi-source decision support. Code will be released upon acceptance.
PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments
Jun 18, 2024


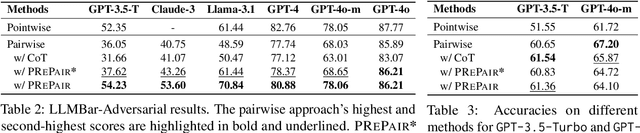
Pairwise evaluation using large language models (LLMs) is widely used for evaluating natural language generation (NLG) tasks. However, the reliability of LLMs is often compromised by biases, such as favoring verbosity and authoritative tone. In the study, we focus on the comparison of two LLM-based evaluation approaches, pointwise and pairwise. Our findings demonstrate that pointwise evaluators exhibit more robustness against undesirable preferences. Further analysis reveals that pairwise evaluators can accurately identify the shortcomings of low-quality outputs even when their judgment is incorrect. These results indicate that LLMs are more severely influenced by their bias in a pairwise evaluation setup. To mitigate this, we propose a hybrid method that integrates pointwise reasoning into pairwise evaluation. Experimental results show that our method enhances the robustness of pairwise evaluators against adversarial samples while preserving accuracy on normal samples.
A Simple Framework to Accelerate Multilingual Language Model for Monolingual Text Generation
Jan 19, 2024



Recent advancements in large language models have facilitated the execution of complex language tasks, not only in English but also in non-English languages. However, the tokenizers of most language models, such as Llama, trained on English-centric corpora, tend to excessively fragment tokens in non-English languages. This issue is especially pronounced in non-roman alphabetic languages, which are often divided at a character or even Unicode level, leading to slower text generation. To address this, our study introduces a novel framework designed to expedite text generation in these languages. This framework predicts larger linguistic units than those of conventional multilingual tokenizers and is specifically tailored to the target language, thereby reducing the number of decoding steps required. Our empirical results demonstrate that the proposed framework increases the generation speed by a factor of 1.9 compared to standard decoding while maintaining the performance of a pre-trained multilingual model on monolingual tasks.
Learning to Diversify Neural Text Generation via Degenerative Model
Sep 22, 2023



Neural language models often fail to generate diverse and informative texts, limiting their applicability in real-world problems. While previous approaches have proposed to address these issues by identifying and penalizing undesirable behaviors (e.g., repetition, overuse of frequent words) from language models, we propose an alternative approach based on an observation: models primarily learn attributes within examples that are likely to cause degeneration problems. Based on this observation, we propose a new approach to prevent degeneration problems by training two models. Specifically, we first train a model that is designed to amplify undesirable patterns. We then enhance the diversity of the second model by focusing on patterns that the first model fails to learn. Extensive experiments on two tasks, namely language modeling and dialogue generation, demonstrate the effectiveness of our approach.
TeSS: Zero-Shot Classification via Textual Similarity Comparison with Prompting using Sentence Encoder
Dec 20, 2022
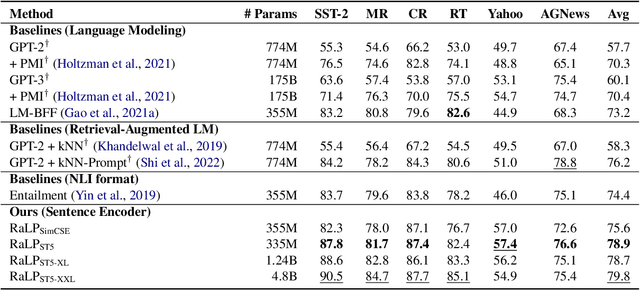
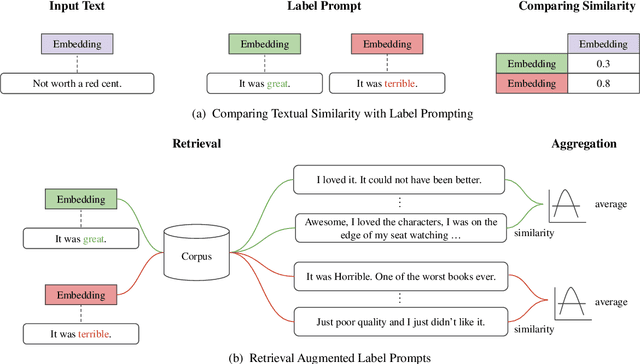

We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
Reweighting Strategy based on Synthetic Data Identification for Sentence Similarity
Aug 30, 2022
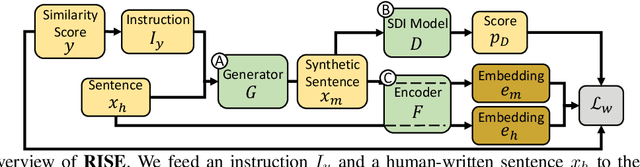

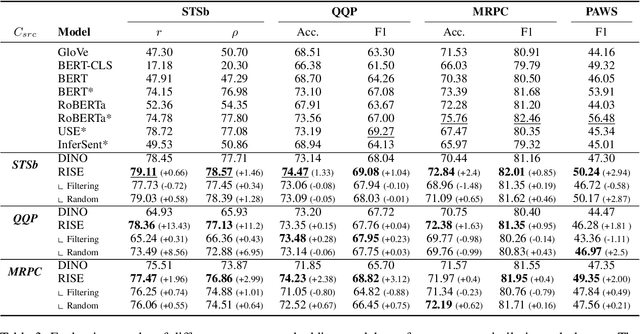
Semantically meaningful sentence embeddings are important for numerous tasks in natural language processing. To obtain such embeddings, recent studies explored the idea of utilizing synthetically generated data from pretrained language models (PLMs) as a training corpus. However, PLMs often generate sentences much different from the ones written by human. We hypothesize that treating all these synthetic examples equally for training deep neural networks can have an adverse effect on learning semantically meaningful embeddings. To analyze this, we first train a classifier that identifies machine-written sentences, and observe that the linguistic features of the sentences identified as written by a machine are significantly different from those of human-written sentences. Based on this, we propose a novel approach that first trains the classifier to measure the importance of each sentence. The distilled information from the classifier is then used to train a reliable sentence embedding model. Through extensive evaluation on four real-world datasets, we demonstrate that our model trained on synthetic data generalizes well and outperforms the existing baselines. Our implementation is publicly available at https://github.com/ddehun/coling2022_reweighting_sts.
AVocaDo: Strategy for Adapting Vocabulary to Downstream Domain
Oct 26, 2021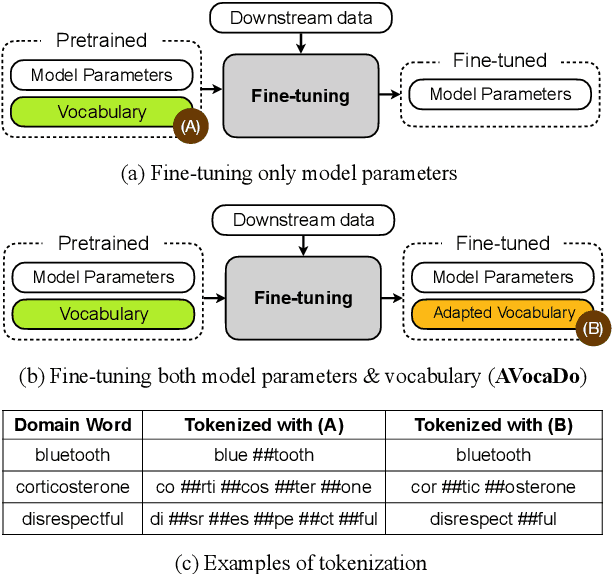

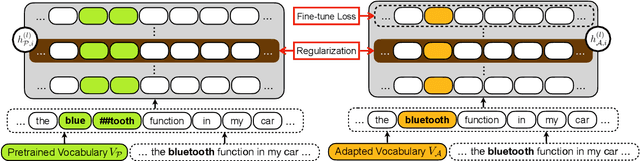
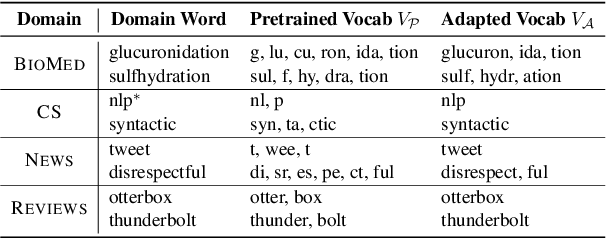
During the fine-tuning phase of transfer learning, the pretrained vocabulary remains unchanged, while model parameters are updated. The vocabulary generated based on the pretrained data is suboptimal for downstream data when domain discrepancy exists. We propose to consider the vocabulary as an optimizable parameter, allowing us to update the vocabulary by expanding it with domain-specific vocabulary based on a tokenization statistic. Furthermore, we preserve the embeddings of the added words from overfitting to downstream data by utilizing knowledge learned from a pretrained language model with a regularization term. Our method achieved consistent performance improvements on diverse domains (i.e., biomedical, computer science, news, and reviews).
Natural Attribute-based Shift Detection
Oct 18, 2021

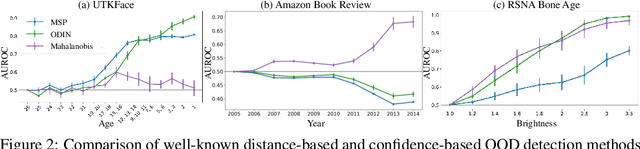

Despite the impressive performance of deep networks in vision, language, and healthcare, unpredictable behaviors on samples from the distribution different than the training distribution cause severe problems in deployment. For better reliability of neural-network-based classifiers, we define a new task, natural attribute-based shift (NAS) detection, to detect the samples shifted from the training distribution by some natural attribute such as age of subjects or brightness of images. Using the natural attributes present in existing datasets, we introduce benchmark datasets in vision, language, and medical for NAS detection. Further, we conduct an extensive evaluation of prior representative out-of-distribution (OOD) detection methods on NAS datasets and observe an inconsistency in their performance. To understand this, we provide an analysis on the relationship between the location of NAS samples in the feature space and the performance of distance- and confidence-based OOD detection methods. Based on the analysis, we split NAS samples into three categories and further suggest a simple modification to the training objective to obtain an improved OOD detection method that is capable of detecting samples from all NAS categories.
Evaluation of Out-of-Distribution Detection Performance of Self-Supervised Learning in a Controllable Environment
Nov 26, 2020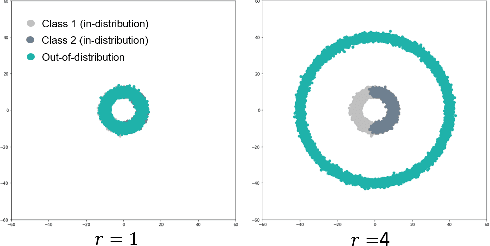

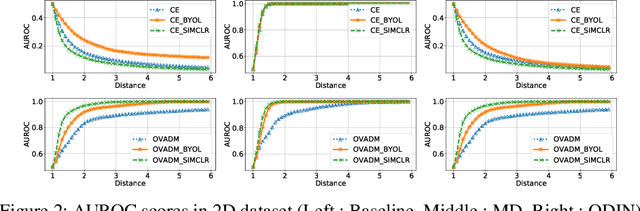
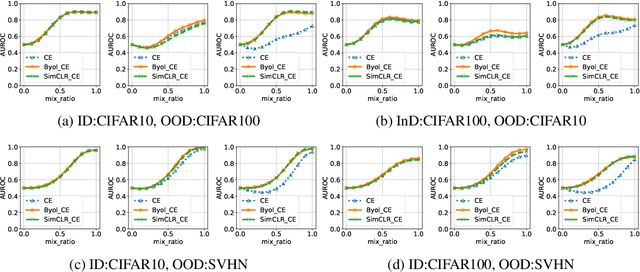
We evaluate the out-of-distribution (OOD) detection performance of self-supervised learning (SSL) techniques with a new evaluation framework. Unlike the previous evaluation methods, the proposed framework adjusts the distance of OOD samples from the in-distribution samples. We evaluate an extensive combination of OOD detection algorithms on three different implementations of the proposed framework using simulated samples, images, and text. SSL methods consistently demonstrated the improved OOD detection performance in all evaluation settings.