 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF^2-Softmax: Diversifying Neural Text Generation via Frequency Factorized Softmax
Oct 04, 2020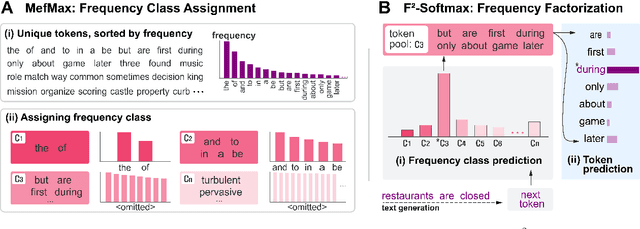

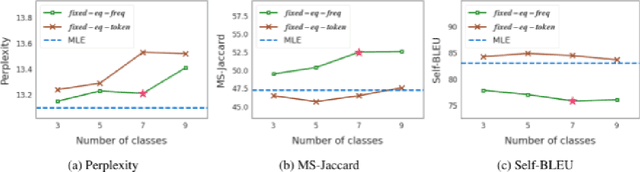

Despite recent advances in neural text generation, encoding the rich diversity in human language remains elusive. We argue that the sub-optimal text generation is mainly attributable to the imbalanced token distribution, which particularly misdirects the learning model when trained with the maximum-likelihood objective. As a simple yet effective remedy, we propose two novel methods, F^2-Softmax and MefMax, for a balanced training even with the skewed frequency distribution. MefMax assigns tokens uniquely to frequency classes, trying to group tokens with similar frequencies and equalize frequency mass between the classes. F^2-Softmax then decomposes a probability distribution of the target token into a product of two conditional probabilities of (i) frequency class, and (ii) token from the target frequency class. Models learn more uniform probability distributions because they are confined to subsets of vocabularies. Significant performance gains on seven relevant metrics suggest the supremacy of our approach in improving not only the diversity but also the quality of generated texts.
Incorporating Word Embeddings into Open Directory Project based Large-scale Classification
Apr 03, 2018



Recently, implicit representation models, such as embedding or deep learning, have been successfully adopted to text classification task due to their outstanding performance. However, these approaches are limited to small- or moderate-scale text classification. Explicit representation models are often used in a large-scale text classification, like the Open Directory Project (ODP)-based text classification. However, the performance of these models is limited to the associated knowledge bases. In this paper, we incorporate word embeddings into the ODP-based large-scale classification. To this end, we first generate category vectors, which represent the semantics of ODP categories by jointly modeling word embeddings and the ODP-based text classification. We then propose a novel semantic similarity measure, which utilizes the category and word vectors obtained from the joint model and word embeddings, respectively. The evaluation results clearly show the efficacy of our methodology in large-scale text classification. The proposed scheme exhibits significant improvements of 10% and 28% in terms of macro-averaging F1-score and precision at k, respectively, over state-of-the-art techniques.