 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Accurate Elevation Modeling for Off-road Navigation via Neural Processes
Aug 05, 2025Terrain elevation modeling for off-road navigation aims to accurately estimate changes in terrain geometry in real-time and quantify the corresponding uncertainties. Having precise estimations and uncertainties plays a crucial role in planning and control algorithms to explore safe and reliable maneuver strategies. However, existing approaches, such as Gaussian Processes (GPs) and neural network-based methods, often fail to meet these needs. They are either unable to perform in real-time due to high computational demands, underestimating sharp geometry changes, or harming elevation accuracy when learned with uncertainties. Recently, Neural Processes (NPs) have emerged as a promising approach that integrates the Bayesian uncertainty estimation of GPs with the efficiency and flexibility of neural networks. Inspired by NPs, we propose an effective NP-based method that precisely estimates sharp elevation changes and quantifies the corresponding predictive uncertainty without losing elevation accuracy. Our method leverages semantic features from LiDAR and camera sensors to improve interpolation and extrapolation accuracy in unobserved regions. Also, we introduce a local ball-query attention mechanism to effectively reduce the computational complexity of global attention by 17\% while preserving crucial local and spatial information. We evaluate our method on off-road datasets having interesting geometric features, collected from trails, deserts, and hills. Our results demonstrate superior performance over baselines and showcase the potential of neural processes for effective and expressive terrain modeling in complex off-road environments.
Forecasting Future International Events: A Reliable Dataset for Text-Based Event Modeling
Nov 21, 2024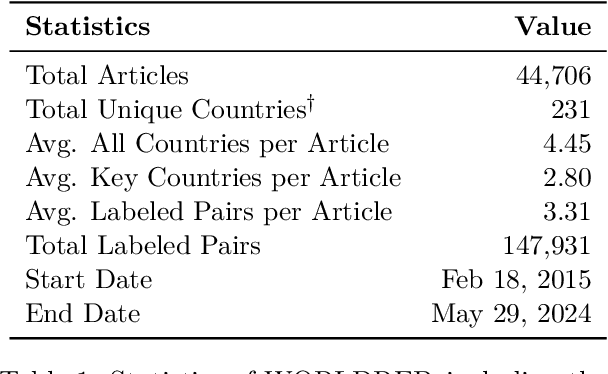
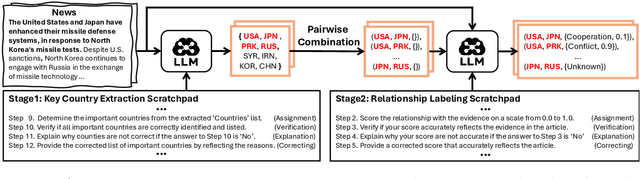

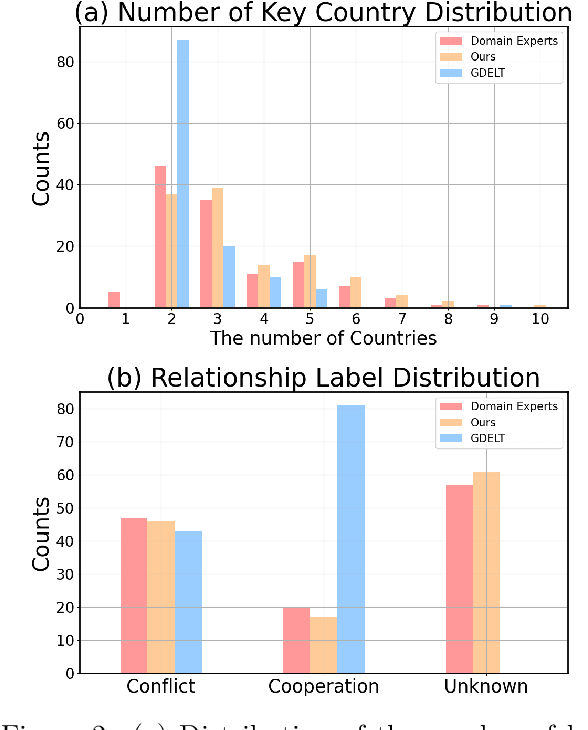
Predicting future international events from textual information, such as news articles, has tremendous potential for applications in global policy, strategic decision-making, and geopolitics. However, existing datasets available for this task are often limited in quality, hindering the progress of related research. In this paper, we introduce WORLDREP (WORLD Relationship and Event Prediction), a novel dataset designed to address these limitations by leveraging the advanced reasoning capabilities of large-language models (LLMs). Our dataset features high-quality scoring labels generated through advanced prompt modeling and rigorously validated by domain experts in political science. We showcase the quality and utility of WORLDREP for real-world event prediction tasks, demonstrating its effectiveness through extensive experiments and analysis. Furthermore, we publicly release our dataset along with the full automation source code for data collection, labeling, and benchmarking, aiming to support and advance research in text-based event prediction.
Self-Supervised Contrastive Forecasting
Feb 03, 2024
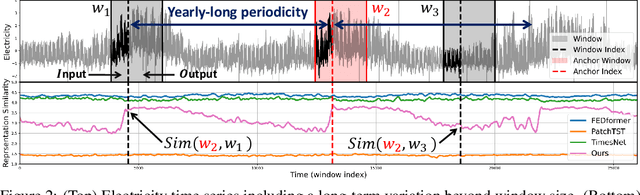
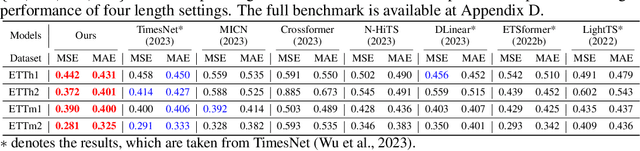

Long-term forecasting presents unique challenges due to the time and memory complexity of handling long sequences. Existing methods, which rely on sliding windows to process long sequences, struggle to effectively capture long-term variations that are partially caught within the short window (i.e., outer-window variations). In this paper, we introduce a novel approach that overcomes this limitation by employing contrastive learning and enhanced decomposition architecture, specifically designed to focus on long-term variations. To this end, our contrastive loss incorporates global autocorrelation held in the whole time series, which facilitates the construction of positive and negative pairs in a self-supervised manner. When combined with our decomposition networks, our contrastive learning significantly improves long-term forecasting performance. Extensive experiments demonstrate that our approach outperforms 14 baseline models in multiple experiments over nine long-term benchmarks, especially in challenging scenarios that require a significantly long output for forecasting. Source code is available at https://github.com/junwoopark92/Self-Supervised-Contrastive-Forecsating.
Enhancing Generalization and Plasticity for Sample Efficient Reinforcement Learning
Jun 19, 2023



In Reinforcement Learning (RL), enhancing sample efficiency is crucial, particularly in scenarios when data acquisition is costly and risky. In principle, off-policy RL algorithms can improve sample efficiency by allowing multiple updates per environment interaction. However, these multiple updates often lead to overfitting, which decreases the network's ability to adapt to new data. We conduct an empirical analysis of this challenge and find that generalizability and plasticity constitute different roles in improving the model's adaptability. In response, we propose a combined usage of Sharpness-Aware Minimization (SAM) and a reset mechanism. SAM seeks wide, smooth minima, improving generalization, while the reset mechanism, through periodic reinitialization of the last few layers, consistently injects plasticity into the model. Through extensive empirical studies, we demonstrate that this combined usage improves sample efficiency and computational cost on the Atari-100k and DeepMind Control Suite benchmarks.
Conditional Generation of Periodic Signals with Fourier-Based Decoder
Oct 24, 2021

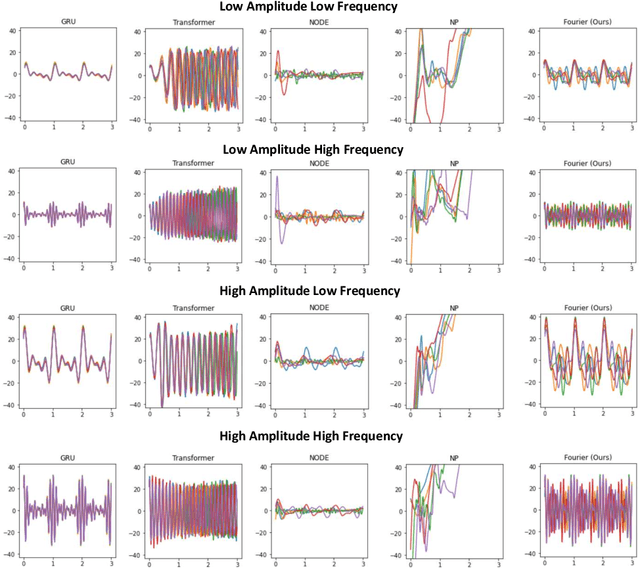
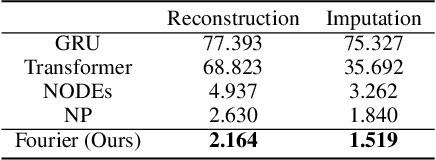
Periodic signals play an important role in daily lives. Although conventional sequential models have shown remarkable success in various fields, they still come short in modeling periodicity; they either collapse, diverge or ignore details. In this paper, we introduce a novel framework inspired by Fourier series to generate periodic signals. We first decompose the given signals into multiple sines and cosines and then conditionally generate periodic signals with the output components. We have shown our model efficacy on three tasks: reconstruction, imputation and conditional generation. Our model outperforms baselines in all tasks and shows more stable and refined results.
Natural Attribute-based Shift Detection
Oct 18, 2021

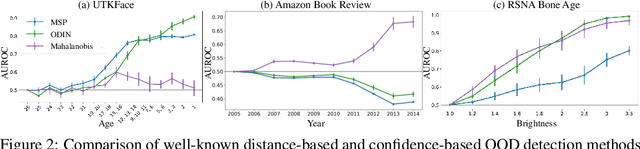

Despite the impressive performance of deep networks in vision, language, and healthcare, unpredictable behaviors on samples from the distribution different than the training distribution cause severe problems in deployment. For better reliability of neural-network-based classifiers, we define a new task, natural attribute-based shift (NAS) detection, to detect the samples shifted from the training distribution by some natural attribute such as age of subjects or brightness of images. Using the natural attributes present in existing datasets, we introduce benchmark datasets in vision, language, and medical for NAS detection. Further, we conduct an extensive evaluation of prior representative out-of-distribution (OOD) detection methods on NAS datasets and observe an inconsistency in their performance. To understand this, we provide an analysis on the relationship between the location of NAS samples in the feature space and the performance of distance- and confidence-based OOD detection methods. Based on the analysis, we split NAS samples into three categories and further suggest a simple modification to the training objective to obtain an improved OOD detection method that is capable of detecting samples from all NAS categories.
Standardized Max Logits: A Simple yet Effective Approach for Identifying Unexpected Road Obstacles in Urban-Scene Segmentation
Aug 19, 2021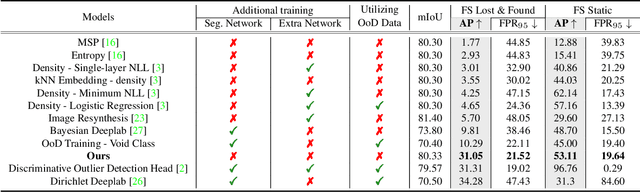
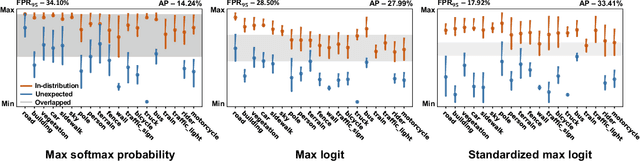


Identifying unexpected objects on roads in semantic segmentation (e.g., identifying dogs on roads) is crucial in safety-critical applications. Existing approaches use images of unexpected objects from external datasets or require additional training (e.g., retraining segmentation networks or training an extra network), which necessitate a non-trivial amount of labor intensity or lengthy inference time. One possible alternative is to use prediction scores of a pre-trained network such as the max logits (i.e., maximum values among classes before the final softmax layer) for detecting such objects. However, the distribution of max logits of each predicted class is significantly different from each other, which degrades the performance of identifying unexpected objects in urban-scene segmentation. To address this issue, we propose a simple yet effective approach that standardizes the max logits in order to align the different distributions and reflect the relative meanings of max logits within each predicted class. Moreover, we consider the local regions from two different perspectives based on the intuition that neighboring pixels share similar semantic information. In contrast to previous approaches, our method does not utilize any external datasets or require additional training, which makes our method widely applicable to existing pre-trained segmentation models. Such a straightforward approach achieves a new state-of-the-art performance on the publicly available Fishyscapes Lost & Found leaderboard with a large margin. Our code is publicly available at this $\href{https://github.com/shjung13/Standardized-max-logits}{link}$.
Evaluation of Out-of-Distribution Detection Performance of Self-Supervised Learning in a Controllable Environment
Nov 26, 2020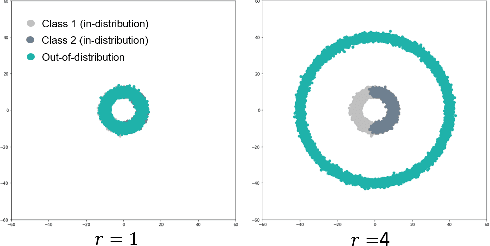

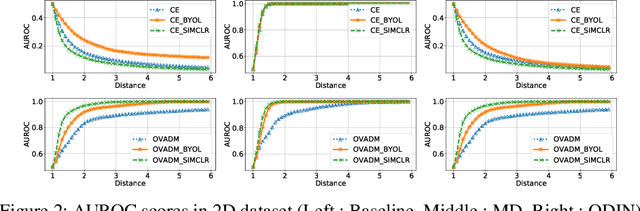
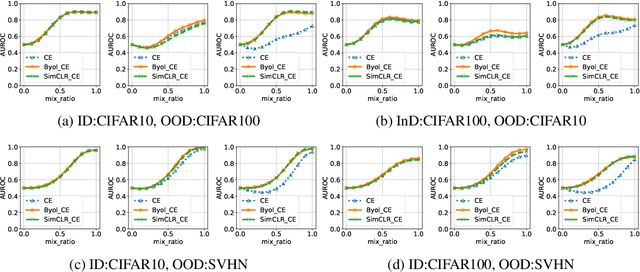
We evaluate the out-of-distribution (OOD) detection performance of self-supervised learning (SSL) techniques with a new evaluation framework. Unlike the previous evaluation methods, the proposed framework adjusts the distance of OOD samples from the in-distribution samples. We evaluate an extensive combination of OOD detection algorithms on three different implementations of the proposed framework using simulated samples, images, and text. SSL methods consistently demonstrated the improved OOD detection performance in all evaluation settings.
Neural Ordinary Differential Equations for Intervention Modeling
Oct 16, 2020
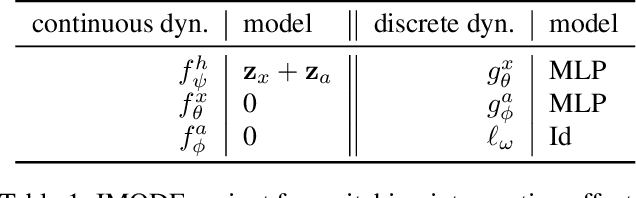
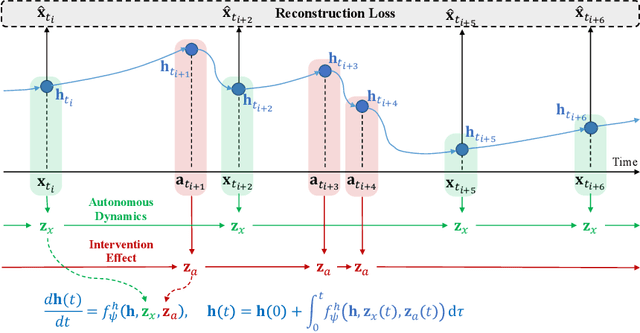
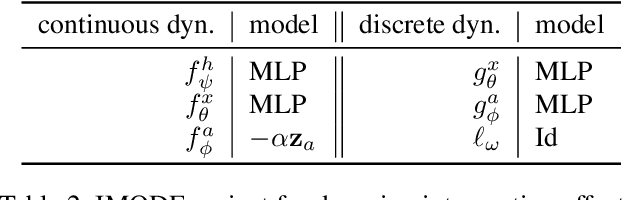
By interpreting the forward dynamics of the latent representation of neural networks as an ordinary differential equation, Neural Ordinary Differential Equation (Neural ODE) emerged as an effective framework for modeling a system dynamics in the continuous time domain. However, real-world systems often involves external interventions that cause changes in the system dynamics such as a moving ball coming in contact with another ball, or such as a patient being administered with particular drug. Neural ODE and a number of its recent variants, however, are not suitable for modeling such interventions as they do not properly model the observations and the interventions separately. In this paper, we propose a novel neural ODE-based approach (IMODE) that properly model the effect of external interventions by employing two ODE functions to separately handle the observations and the interventions. Using both synthetic and real-world time-series datasets involving interventions, our experimental results consistently demonstrate the superiority of IMODE compared to existing approaches.