 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Generation without Unfair Distortions: Debiasing Text-to-Image Generation with Entanglement-Free Attention
Jun 16, 2025



Recent advancements in diffusion-based text-to-image (T2I) models have enabled the generation of high-quality and photorealistic images from text descriptions. However, they often exhibit societal biases related to gender, race, and socioeconomic status, thereby reinforcing harmful stereotypes and shaping public perception in unintended ways. While existing bias mitigation methods demonstrate effectiveness, they often encounter attribute entanglement, where adjustments to attributes relevant to the bias (i.e., target attributes) unintentionally alter attributes unassociated with the bias (i.e., non-target attributes), causing undesirable distribution shifts. To address this challenge, we introduce Entanglement-Free Attention (EFA), a method that accurately incorporates target attributes (e.g., White, Black, Asian, and Indian) while preserving non-target attributes (e.g., background details) during bias mitigation. At inference time, EFA randomly samples a target attribute with equal probability and adjusts the cross-attention in selected layers to incorporate the sampled attribute, achieving a fair distribution of target attributes. Extensive experiments demonstrate that EFA outperforms existing methods in mitigating bias while preserving non-target attributes, thereby maintaining the output distribution and generation capability of the original model.
Enhancing Intrinsic Features for Debiasing via Investigating Class-Discerning Common Attributes in Bias-Contrastive Pair
Apr 30, 2024In the image classification task, deep neural networks frequently rely on bias attributes that are spuriously correlated with a target class in the presence of dataset bias, resulting in degraded performance when applied to data without bias attributes. The task of debiasing aims to compel classifiers to learn intrinsic attributes that inherently define a target class rather than focusing on bias attributes. While recent approaches mainly focus on emphasizing the learning of data samples without bias attributes (i.e., bias-conflicting samples) compared to samples with bias attributes (i.e., bias-aligned samples), they fall short of directly guiding models where to focus for learning intrinsic features. To address this limitation, this paper proposes a method that provides the model with explicit spatial guidance that indicates the region of intrinsic features. We first identify the intrinsic features by investigating the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., bias-contrastive pair). Next, we enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample. To construct the bias-contrastive pair without using bias information, we introduce a bias-negative score that distinguishes BC samples from BA samples employing a biased model. The experiments demonstrate that our method achieves state-of-the-art performance on synthetic and real-world datasets with various levels of bias severity.
BiasEnsemble: Revisiting the Importance of Amplifying Bias for Debiasing
May 29, 2022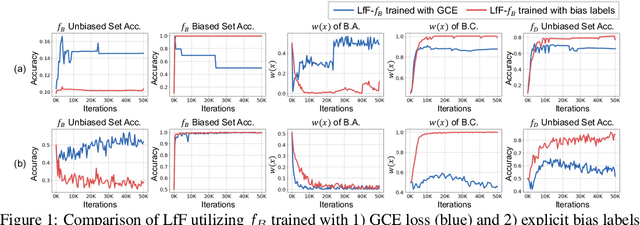
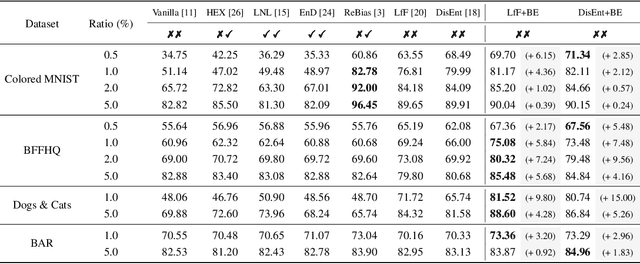
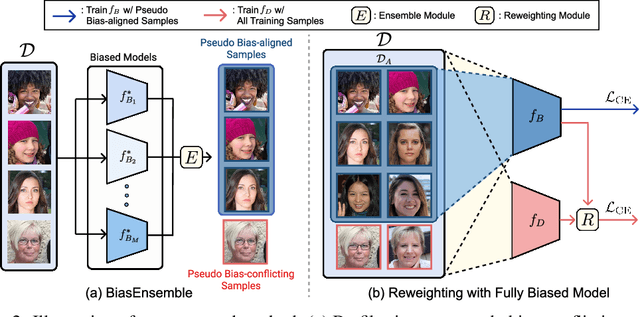

In image classification, "debiasing" aims to train a classifier to be less susceptible to dataset bias, the strong correlation between peripheral attributes of data samples and a target class. For example, even if the frog class in the dataset mainly consists of frog images with a swamp background (i.e., bias-aligned samples), a debiased classifier should be able to correctly classify a frog at a beach (i.e., bias-conflicting samples). Recent debiasing approaches commonly use two components for debiasing, a biased model $f_B$ and a debiased model $f_D$. $f_B$ is trained to focus on bias-aligned samples while $f_D$ is mainly trained with bias-conflicting samples by concentrating on samples which $f_B$ fails to learn, leading $f_D$ to be less susceptible to the dataset bias. While the state-of-the-art debiasing techniques have aimed to better train $f_D$, we focus on training $f_B$, an overlooked component until now. Our empirical analysis reveals that removing the bias-conflicting samples from the training set for $f_B$ is important for improving the debiasing performance of $f_D$. This is due to the fact that the bias-conflicting samples work as noisy samples for amplifying the bias for $f_B$. To this end, we propose a novel biased sample selection method BiasEnsemble which removes the bias-conflicting samples via leveraging additional biased models to construct a bias-amplified dataset for training $f_B$. Our simple yet effective approach can be directly applied to existing reweighting-based debiasing approaches, obtaining consistent performance boost and achieving the state-of-the-art performance on both synthetic and real-world datasets.
Natural Attribute-based Shift Detection
Oct 18, 2021

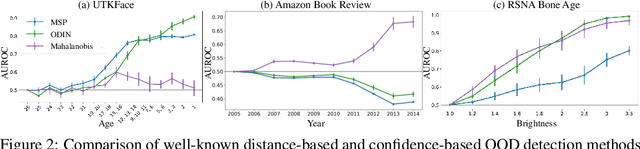

Despite the impressive performance of deep networks in vision, language, and healthcare, unpredictable behaviors on samples from the distribution different than the training distribution cause severe problems in deployment. For better reliability of neural-network-based classifiers, we define a new task, natural attribute-based shift (NAS) detection, to detect the samples shifted from the training distribution by some natural attribute such as age of subjects or brightness of images. Using the natural attributes present in existing datasets, we introduce benchmark datasets in vision, language, and medical for NAS detection. Further, we conduct an extensive evaluation of prior representative out-of-distribution (OOD) detection methods on NAS datasets and observe an inconsistency in their performance. To understand this, we provide an analysis on the relationship between the location of NAS samples in the feature space and the performance of distance- and confidence-based OOD detection methods. Based on the analysis, we split NAS samples into three categories and further suggest a simple modification to the training objective to obtain an improved OOD detection method that is capable of detecting samples from all NAS categories.
Deep Edge-Aware Interactive Colorization against Color-Bleeding Effects
Jul 04, 2021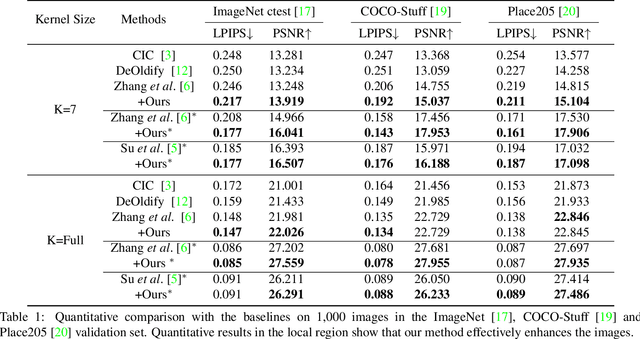
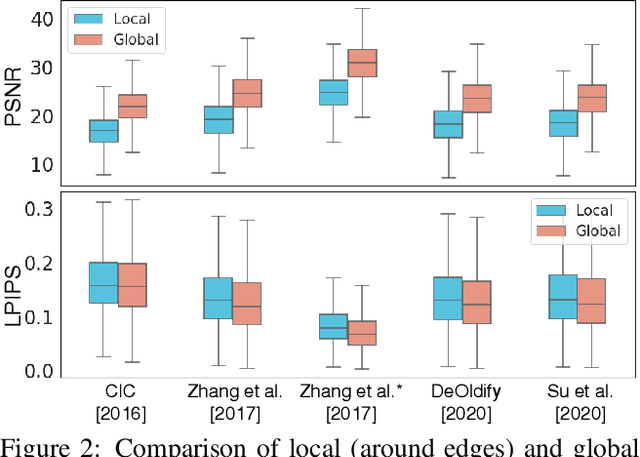
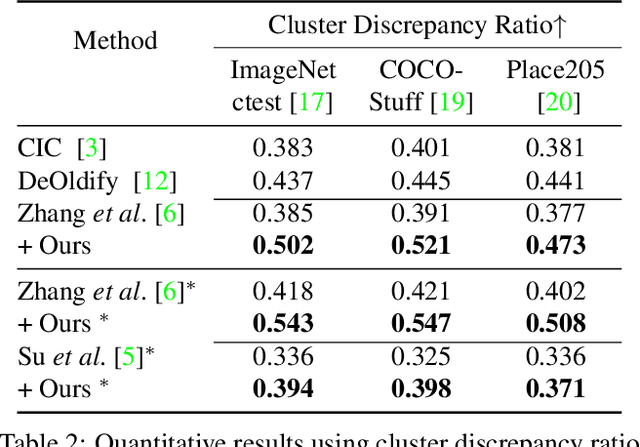
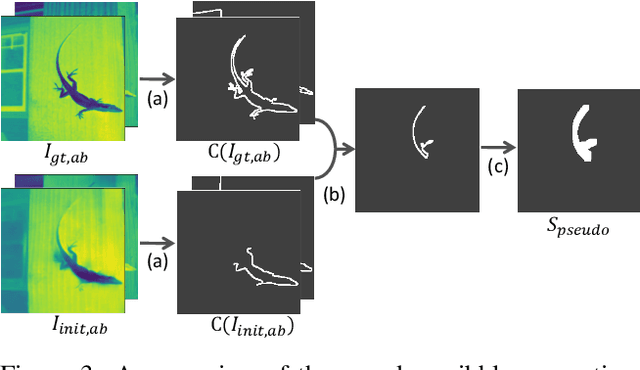
Deep image colorization networks often suffer from the color-bleeding artifact, a problematic color spreading near the boundaries between adjacent objects. The color-bleeding artifacts debase the reality of generated outputs, limiting the applicability of colorization models on a practical application. Although previous approaches have tackled this problem in an automatic manner, they often generate imperfect outputs because their enhancements are available only in limited cases, such as having a high contrast of gray-scale value in an input image. Instead, leveraging user interactions would be a promising approach, since it can help the edge correction in the desired regions. In this paper, we propose a novel edge-enhancing framework for the regions of interest, by utilizing user scribbles that indicate where to enhance. Our method requires minimal user effort to obtain satisfactory enhancements. Experimental results on various datasets demonstrate that our interactive approach has outstanding performance in improving color-bleeding artifacts against the existing baselines.
Evaluation of Out-of-Distribution Detection Performance of Self-Supervised Learning in a Controllable Environment
Nov 26, 2020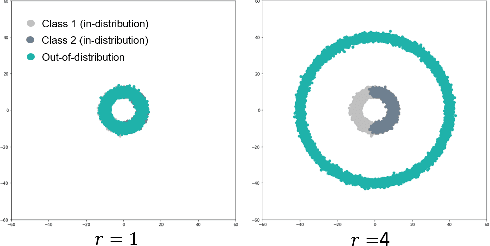

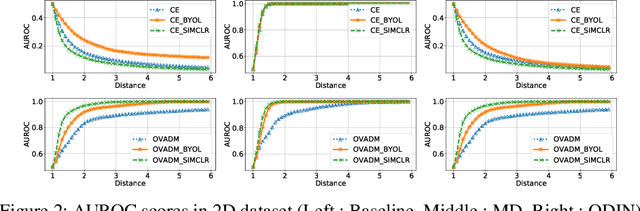
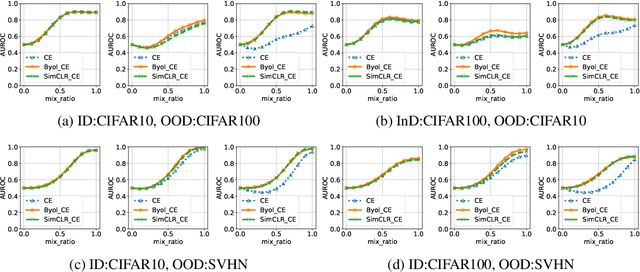
We evaluate the out-of-distribution (OOD) detection performance of self-supervised learning (SSL) techniques with a new evaluation framework. Unlike the previous evaluation methods, the proposed framework adjusts the distance of OOD samples from the in-distribution samples. We evaluate an extensive combination of OOD detection algorithms on three different implementations of the proposed framework using simulated samples, images, and text. SSL methods consistently demonstrated the improved OOD detection performance in all evaluation settings.