 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Your Intention to Steer Your Attention: An AI Assistant for Intentional Digital Living
Oct 16, 2025When working on digital devices, people often face distractions that can lead to a decline in productivity and efficiency, as well as negative psychological and emotional impacts. To address this challenge, we introduce a novel Artificial Intelligence (AI) assistant that elicits a user's intention, assesses whether ongoing activities are in line with that intention, and provides gentle nudges when deviations occur. The system leverages a large language model to analyze screenshots, application titles, and URLs, issuing notifications when behavior diverges from the stated goal. Its detection accuracy is refined through initial clarification dialogues and continuous user feedback. In a three-week, within-subjects field deployment with 22 participants, we compared our assistant to both a rule-based intent reminder system and a passive baseline that only logged activity. Results indicate that our AI assistant effectively supports users in maintaining focus and aligning their digital behavior with their intentions. Our source code is publicly available at this url https://intentassistant.github.io
Fair Generation without Unfair Distortions: Debiasing Text-to-Image Generation with Entanglement-Free Attention
Jun 16, 2025



Recent advancements in diffusion-based text-to-image (T2I) models have enabled the generation of high-quality and photorealistic images from text descriptions. However, they often exhibit societal biases related to gender, race, and socioeconomic status, thereby reinforcing harmful stereotypes and shaping public perception in unintended ways. While existing bias mitigation methods demonstrate effectiveness, they often encounter attribute entanglement, where adjustments to attributes relevant to the bias (i.e., target attributes) unintentionally alter attributes unassociated with the bias (i.e., non-target attributes), causing undesirable distribution shifts. To address this challenge, we introduce Entanglement-Free Attention (EFA), a method that accurately incorporates target attributes (e.g., White, Black, Asian, and Indian) while preserving non-target attributes (e.g., background details) during bias mitigation. At inference time, EFA randomly samples a target attribute with equal probability and adjusts the cross-attention in selected layers to incorporate the sampled attribute, achieving a fair distribution of target attributes. Extensive experiments demonstrate that EFA outperforms existing methods in mitigating bias while preserving non-target attributes, thereby maintaining the output distribution and generation capability of the original model.
Enhancing Intrinsic Features for Debiasing via Investigating Class-Discerning Common Attributes in Bias-Contrastive Pair
Apr 30, 2024In the image classification task, deep neural networks frequently rely on bias attributes that are spuriously correlated with a target class in the presence of dataset bias, resulting in degraded performance when applied to data without bias attributes. The task of debiasing aims to compel classifiers to learn intrinsic attributes that inherently define a target class rather than focusing on bias attributes. While recent approaches mainly focus on emphasizing the learning of data samples without bias attributes (i.e., bias-conflicting samples) compared to samples with bias attributes (i.e., bias-aligned samples), they fall short of directly guiding models where to focus for learning intrinsic features. To address this limitation, this paper proposes a method that provides the model with explicit spatial guidance that indicates the region of intrinsic features. We first identify the intrinsic features by investigating the class-discerning common features between a bias-aligned (BA) sample and a bias-conflicting (BC) sample (i.e., bias-contrastive pair). Next, we enhance the intrinsic features in the BA sample that are relatively under-exploited for prediction compared to the BC sample. To construct the bias-contrastive pair without using bias information, we introduce a bias-negative score that distinguishes BC samples from BA samples employing a biased model. The experiments demonstrate that our method achieves state-of-the-art performance on synthetic and real-world datasets with various levels of bias severity.
DebiasBench: Benchmark for Fair Comparison of Debiasing in Image Classification
Jun 08, 2022
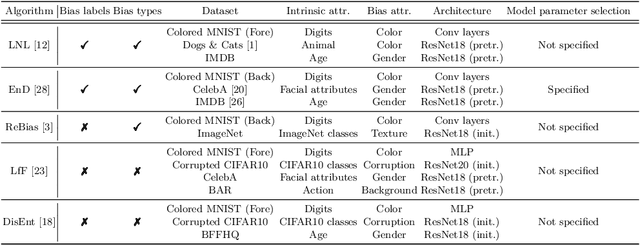
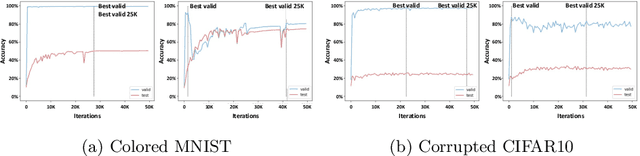
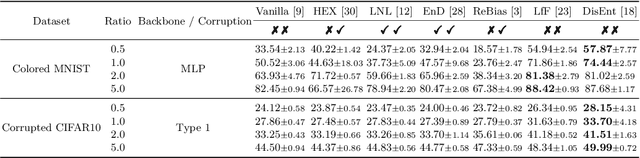
Image classifiers often rely overly on peripheral attributes that have a strong correlation with the target class (i.e., dataset bias) when making predictions. Recently, a myriad of studies focus on mitigating such dataset bias, the task of which is referred to as debiasing. However, these debiasing methods often have inconsistent experimental settings (e.g., datasets and neural network architectures). Additionally, most of the previous studies in debiasing do not specify how they select their model parameters which involve early stopping and hyper-parameter tuning. The goal of this paper is to standardize the inconsistent experimental settings and propose a consistent model parameter selection criterion for debiasing. Based on such unified experimental settings and model parameter selection criterion, we build a benchmark named DebiasBench which includes five datasets and seven debiasing methods. We carefully conduct extensive experiments in various aspects and show that different state-of-the-art methods work best in different datasets, respectively. Even, the vanilla method, the method with no debiasing module, also shows competitive results in datasets with low bias severity. We publicly release the implementation of existing debiasing methods in DebiasBench to encourage future researchers in debiasing to conduct fair comparisons and further push the state-of-the-art performances.
BiasEnsemble: Revisiting the Importance of Amplifying Bias for Debiasing
May 29, 2022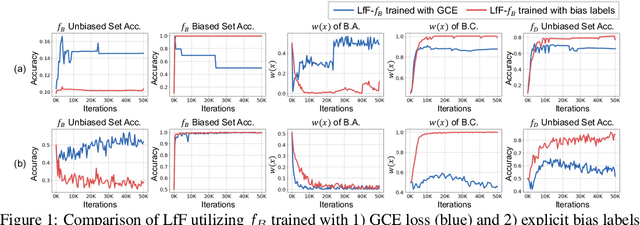
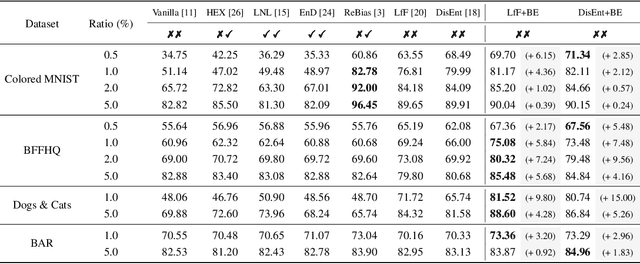
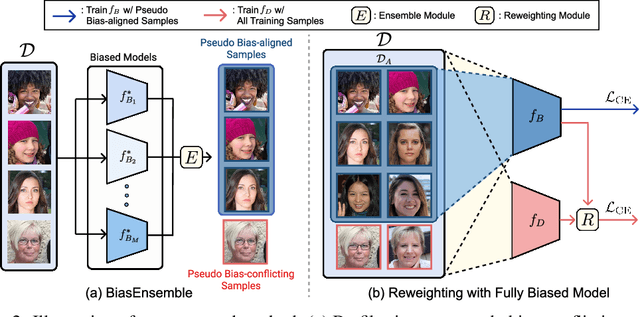

In image classification, "debiasing" aims to train a classifier to be less susceptible to dataset bias, the strong correlation between peripheral attributes of data samples and a target class. For example, even if the frog class in the dataset mainly consists of frog images with a swamp background (i.e., bias-aligned samples), a debiased classifier should be able to correctly classify a frog at a beach (i.e., bias-conflicting samples). Recent debiasing approaches commonly use two components for debiasing, a biased model $f_B$ and a debiased model $f_D$. $f_B$ is trained to focus on bias-aligned samples while $f_D$ is mainly trained with bias-conflicting samples by concentrating on samples which $f_B$ fails to learn, leading $f_D$ to be less susceptible to the dataset bias. While the state-of-the-art debiasing techniques have aimed to better train $f_D$, we focus on training $f_B$, an overlooked component until now. Our empirical analysis reveals that removing the bias-conflicting samples from the training set for $f_B$ is important for improving the debiasing performance of $f_D$. This is due to the fact that the bias-conflicting samples work as noisy samples for amplifying the bias for $f_B$. To this end, we propose a novel biased sample selection method BiasEnsemble which removes the bias-conflicting samples via leveraging additional biased models to construct a bias-amplified dataset for training $f_B$. Our simple yet effective approach can be directly applied to existing reweighting-based debiasing approaches, obtaining consistent performance boost and achieving the state-of-the-art performance on both synthetic and real-world datasets.
Learning Debiased Representation via Disentangled Feature Augmentation
Jul 03, 2021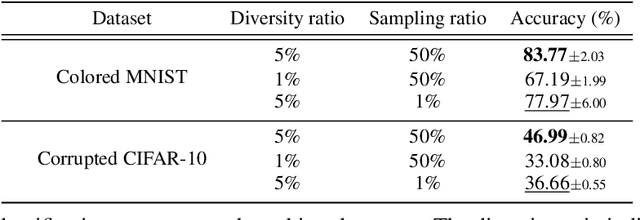
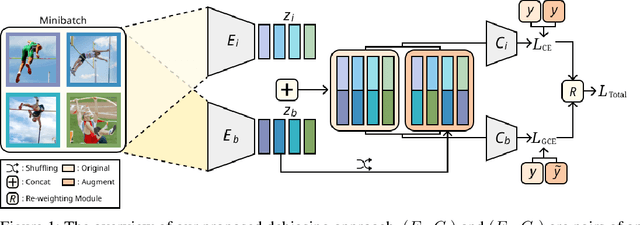

Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as real-world datasets.
k-Space Deep Learning for Reference-free EPI Ghost Correction
Jun 10, 2018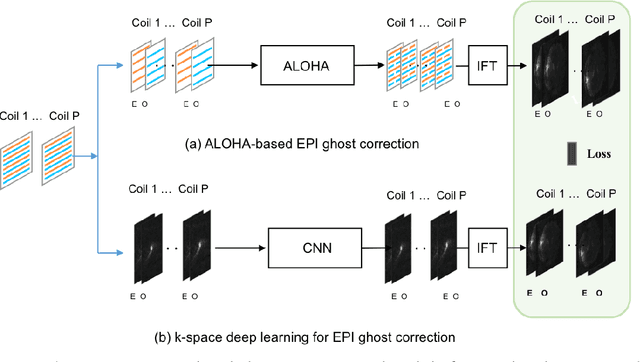
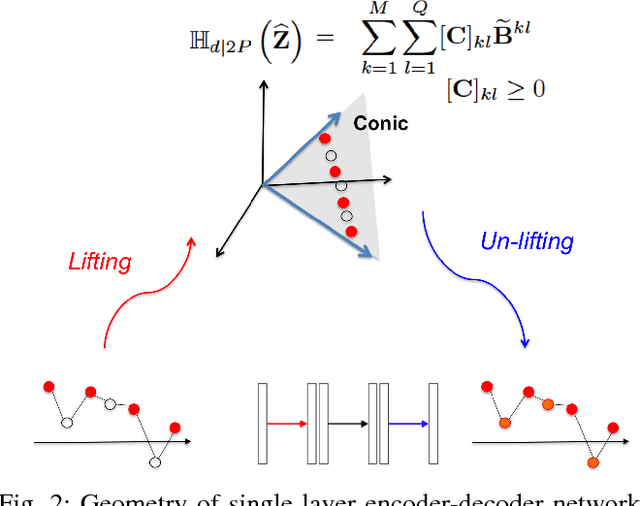
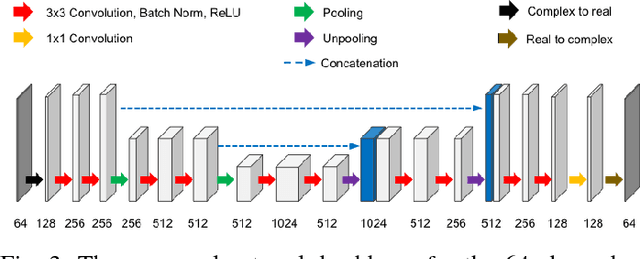
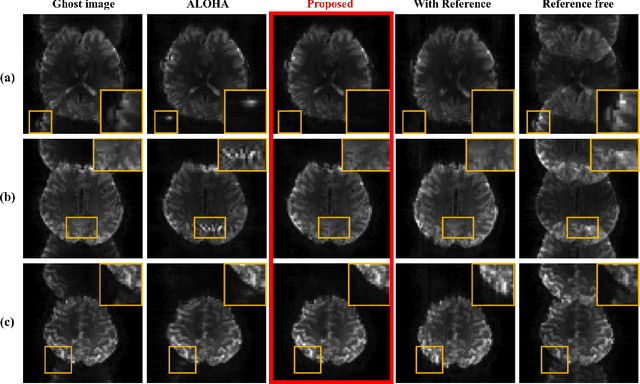
Nyquist ghost artifacts in EPI images are originated from phase mismatch between the even and odd echoes. However, conventional correction methods using reference scans often produce erroneous results especially in high-field MRI due to the non-linear and time-varying local magnetic field changes. Recently, it was shown that the problem of ghost correction can be transformed into k-space data interpolation problem that can be solved using the annihilating filter-based low-rank Hankel structured matrix completion approach (ALOHA). Another recent discovery has shown that the deep convolutional neural network is closely related to the data-driven Hankel matrix decomposition. By synergistically combining these findings, here we propose a k-space deep learning approach that immediately corrects the k-space phase mismatch without a reference scan. Reconstruction results using 7T in vivo data showed that the proposed reference-free k-space deep learning approach for EPI ghost correction significantly improves the image quality compared to the existing methods, and the computing time is several orders of magnitude faster.