 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning from Observation and Interaction
Feb 27, 2026Observational learning requires an agent to learn to perform a task by referencing only observations of the performed task. This work investigates the equivalent setting in real-world robot learning where access to hand-designed rewards and demonstrator actions are not assumed. To address this data-constrained setting, this work presents a planning-based Inverse Reinforcement Learning (IRL) algorithm for world modeling from observation and interaction alone. Experiments conducted entirely in the real-world demonstrate that this paradigm is effective for learning image-based manipulation tasks from scratch in under an hour, without assuming prior knowledge, pre-training, or data of any kind beyond task observations. Moreover, this work demonstrates that the learned world model representation is capable of online transfer learning in the real-world from scratch. In comparison to existing approaches, including IRL, RL, and Behavior Cloning (BC), which have more restrictive assumptions, the proposed approach demonstrates significantly greater sample efficiency and success rates, enabling a practical path forward for online world modeling and planning from observation and interaction. Videos and more at: https://uwrobotlearning.github.io/mpail2/.
Uncertainty-aware Accurate Elevation Modeling for Off-road Navigation via Neural Processes
Aug 05, 2025Terrain elevation modeling for off-road navigation aims to accurately estimate changes in terrain geometry in real-time and quantify the corresponding uncertainties. Having precise estimations and uncertainties plays a crucial role in planning and control algorithms to explore safe and reliable maneuver strategies. However, existing approaches, such as Gaussian Processes (GPs) and neural network-based methods, often fail to meet these needs. They are either unable to perform in real-time due to high computational demands, underestimating sharp geometry changes, or harming elevation accuracy when learned with uncertainties. Recently, Neural Processes (NPs) have emerged as a promising approach that integrates the Bayesian uncertainty estimation of GPs with the efficiency and flexibility of neural networks. Inspired by NPs, we propose an effective NP-based method that precisely estimates sharp elevation changes and quantifies the corresponding predictive uncertainty without losing elevation accuracy. Our method leverages semantic features from LiDAR and camera sensors to improve interpolation and extrapolation accuracy in unobserved regions. Also, we introduce a local ball-query attention mechanism to effectively reduce the computational complexity of global attention by 17\% while preserving crucial local and spatial information. We evaluate our method on off-road datasets having interesting geometric features, collected from trails, deserts, and hills. Our results demonstrate superior performance over baselines and showcase the potential of neural processes for effective and expressive terrain modeling in complex off-road environments.
Demonstrating Wheeled Lab: Modern Sim2Real for Low-cost, Open-source Wheeled Robotics
Feb 11, 2025
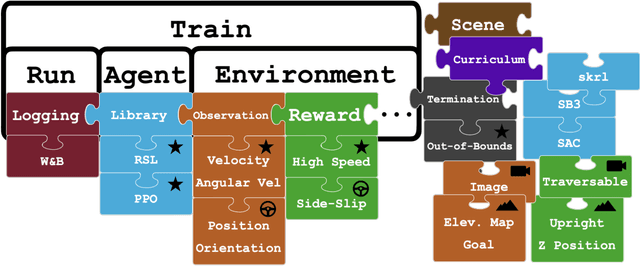

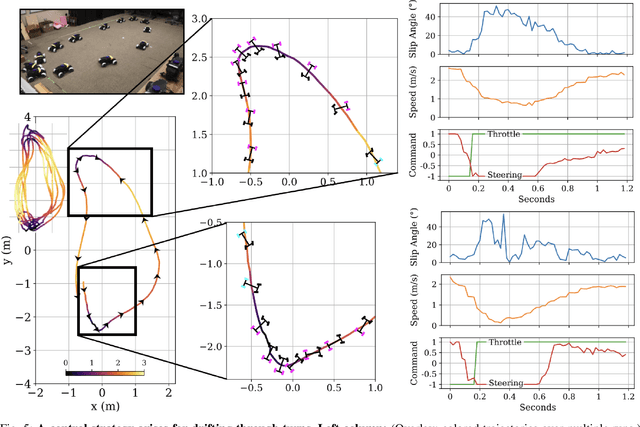
Simulation has been pivotal in recent robotics milestones and is poised to play a prominent role in the field's future. However, recent robotic advances often rely on expensive and high-maintenance platforms, limiting access to broader robotics audiences. This work introduces Wheeled Lab, a framework for the low-cost, open-source wheeled platforms that are already widely established in education and research. Through integration with Isaac Lab, Wheeled Lab introduces modern techniques in Sim2Real, such as domain randomization, sensor simulation, and end-to-end learning, to new user communities. To kickstart education and demonstrate the framework's capabilities, we develop three state-of-the-art policies for small-scale RC cars: controlled drifting, elevation traversal, and visual navigation, each trained in simulation and deployed in the real world. By bridging the gap between advanced Sim2Real methods and affordable, available robotics, Wheeled Lab aims to democratize access to cutting-edge tools, fostering innovation and education in a broader robotics context. The full stack, from hardware to software, is low cost and open-source.
Aim My Robot: Precision Local Navigation to Any Object
Nov 22, 2024Existing navigation systems mostly consider "success" when the robot reaches within 1m radius to a goal. This precision is insufficient for emerging applications where the robot needs to be positioned precisely relative to an object for downstream tasks, such as docking, inspection, and manipulation. To this end, we design and implement Aim-My-Robot (AMR), a local navigation system that enables a robot to reach any object in its vicinity at the desired relative pose, with centimeter-level precision. AMR achieves high precision and robustness by leveraging multi-modal perception, precise action prediction, and is trained on large-scale photorealistic data generated in simulation. AMR shows strong sim2real transfer and can adapt to different robot kinematics and unseen objects with little to no fine-tuning.
V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Navigation
Dec 26, 2023



Reliable estimation of terrain traversability is critical for the successful deployment of autonomous systems in wild, outdoor environments. Given the lack of large-scale annotated datasets for off-road navigation, strictly-supervised learning approaches remain limited in their generalization ability. To this end, we introduce a novel, image-based self-supervised learning method for traversability prediction, leveraging a state-of-the-art vision foundation model for improved out-of-distribution performance. Our method employs contrastive representation learning using both human driving data and instance-based segmentation masks during training. We show that this simple, yet effective, technique drastically outperforms recent methods in predicting traversability for both on- and off-trail driving scenarios. We compare our method with recent baselines on both a common benchmark as well as our own datasets, covering a diverse range of outdoor environments and varied terrain types. We also demonstrate the compatibility of resulting costmap predictions with a model-predictive controller. Finally, we evaluate our approach on zero- and few-shot tasks, demonstrating unprecedented performance for generalization to new environments. Videos and additional material can be found here: \url{https://sites.google.com/view/visual-traversability-learning}.
LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation
Sep 24, 2023We introduce LiDAR-UDA, a novel two-stage self-training-based Unsupervised Domain Adaptation (UDA) method for LiDAR segmentation. Existing self-training methods use a model trained on labeled source data to generate pseudo labels for target data and refine the predictions via fine-tuning the network on the pseudo labels. These methods suffer from domain shifts caused by different LiDAR sensor configurations in the source and target domains. We propose two techniques to reduce sensor discrepancy and improve pseudo label quality: 1) LiDAR beam subsampling, which simulates different LiDAR scanning patterns by randomly dropping beams; 2) cross-frame ensembling, which exploits temporal consistency of consecutive frames to generate more reliable pseudo labels. Our method is simple, generalizable, and does not incur any extra inference cost. We evaluate our method on several public LiDAR datasets and show that it outperforms the state-of-the-art methods by more than $3.9\%$ mIoU on average for all scenarios. Code will be available at https://github.com/JHLee0513/LiDARUDA.
DebiasBench: Benchmark for Fair Comparison of Debiasing in Image Classification
Jun 08, 2022
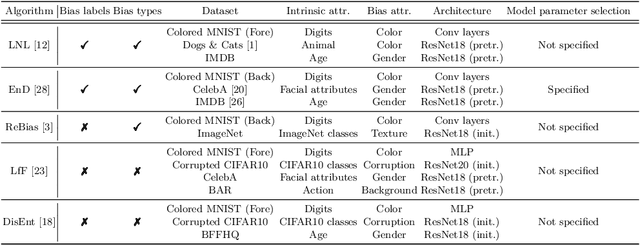
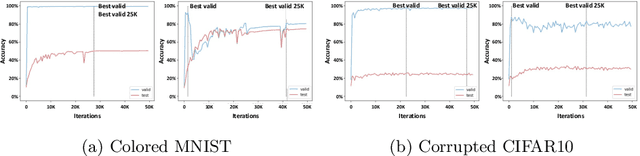
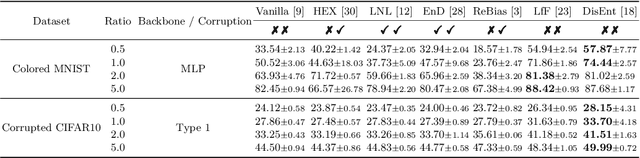
Image classifiers often rely overly on peripheral attributes that have a strong correlation with the target class (i.e., dataset bias) when making predictions. Recently, a myriad of studies focus on mitigating such dataset bias, the task of which is referred to as debiasing. However, these debiasing methods often have inconsistent experimental settings (e.g., datasets and neural network architectures). Additionally, most of the previous studies in debiasing do not specify how they select their model parameters which involve early stopping and hyper-parameter tuning. The goal of this paper is to standardize the inconsistent experimental settings and propose a consistent model parameter selection criterion for debiasing. Based on such unified experimental settings and model parameter selection criterion, we build a benchmark named DebiasBench which includes five datasets and seven debiasing methods. We carefully conduct extensive experiments in various aspects and show that different state-of-the-art methods work best in different datasets, respectively. Even, the vanilla method, the method with no debiasing module, also shows competitive results in datasets with low bias severity. We publicly release the implementation of existing debiasing methods in DebiasBench to encourage future researchers in debiasing to conduct fair comparisons and further push the state-of-the-art performances.
CAFA: Class-Aware Feature Alignment for Test-Time Adaptation
Jun 01, 2022

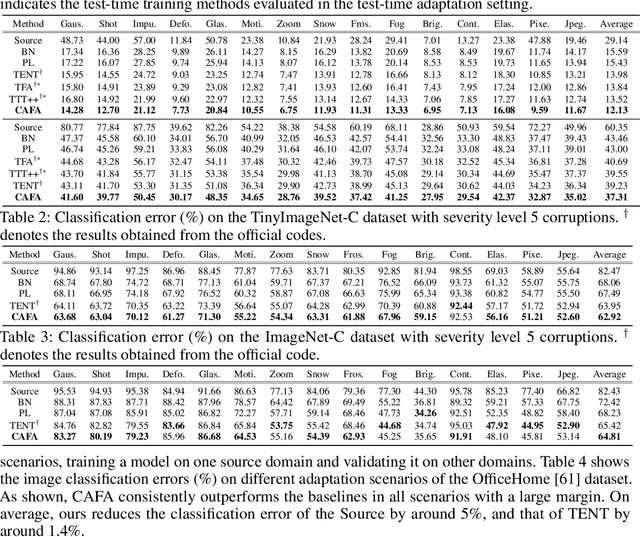

Despite recent advancements in deep learning, deep networks still suffer from performance degradation when they face new and different data from their training distributions. Addressing such a problem, test-time adaptation (TTA) aims to adapt a model to unlabeled test data on test time while making predictions simultaneously. TTA applies to pretrained networks without modifying their training procedures, which enables to utilize the already well-formed source distribution for adaptation. One possible approach is to align the representation space of test samples to the source distribution (\textit{i.e.,} feature alignment). However, performing feature alignments in TTA is especially challenging in that the access to labeled source data is restricted during adaptation. That is, a model does not have a chance to learn test data in a class-discriminative manner, which was feasible in other adaptation tasks (\textit{e.g.,} unsupervised domain adaptation) via supervised loss on the source data. Based on such an observation, this paper proposes \emph{a simple yet effective} feature alignment loss, termed as Class-Aware Feature Alignment (CAFA), which 1) encourages a model to learn target representations in a class-discriminative manner and 2) effectively mitigates the distribution shifts in test time, simultaneously. Our method does not require any hyper-parameters or additional losses, which are required in the previous approaches. We conduct extensive experiments and show our proposed method consistently outperforms existing baselines.
3D-GIF: 3D-Controllable Object Generation via Implicit Factorized Representations
Mar 12, 2022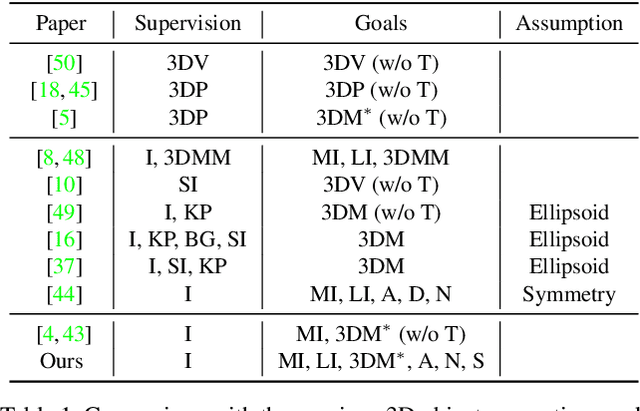
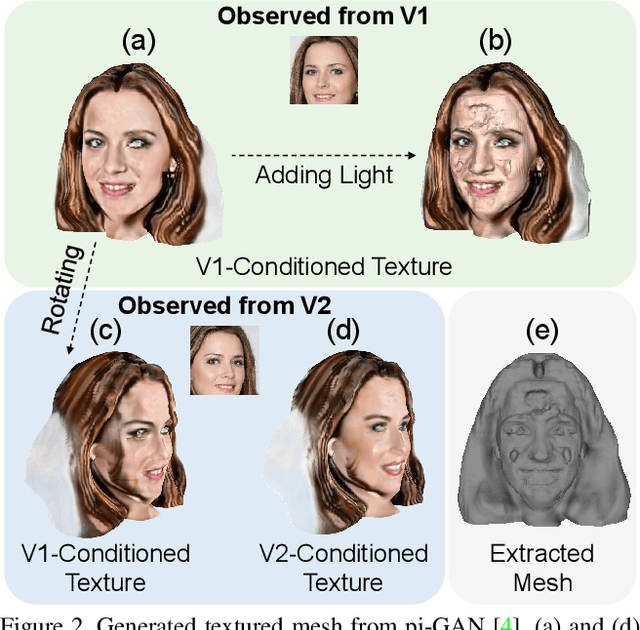

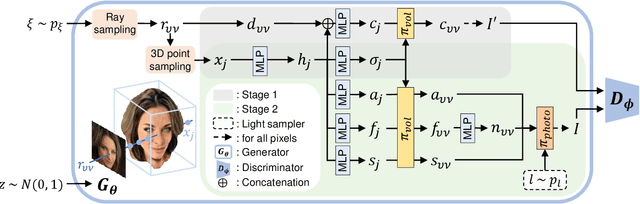
While NeRF-based 3D-aware image generation methods enable viewpoint control, limitations still remain to be adopted to various 3D applications. Due to their view-dependent and light-entangled volume representation, the 3D geometry presents unrealistic quality and the color should be re-rendered for every desired viewpoint. To broaden the 3D applicability from 3D-aware image generation to 3D-controllable object generation, we propose the factorized representations which are view-independent and light-disentangled, and training schemes with randomly sampled light conditions. We demonstrate the superiority of our method by visualizing factorized representations, re-lighted images, and albedo-textured meshes. In addition, we show that our approach improves the quality of the generated geometry via visualization and quantitative comparison. To the best of our knowledge, this is the first work that extracts albedo-textured meshes with unposed 2D images without any additional labels or assumptions.
CG-NeRF: Conditional Generative Neural Radiance Fields
Dec 07, 2021
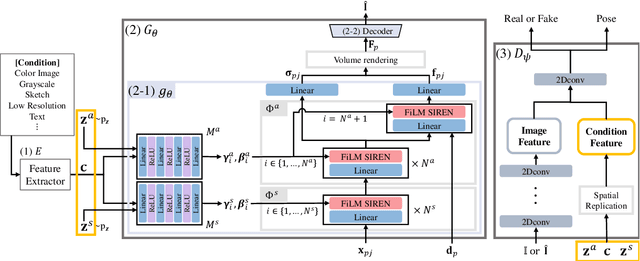


While recent NeRF-based generative models achieve the generation of diverse 3D-aware images, these approaches have limitations when generating images that contain user-specified characteristics. In this paper, we propose a novel model, referred to as the conditional generative neural radiance fields (CG-NeRF), which can generate multi-view images reflecting extra input conditions such as images or texts. While preserving the common characteristics of a given input condition, the proposed model generates diverse images in fine detail. We propose: 1) a novel unified architecture which disentangles the shape and appearance from a condition given in various forms and 2) the pose-consistent diversity loss for generating multimodal outputs while maintaining consistency of the view. Experimental results show that the proposed method maintains consistent image quality on various condition types and achieves superior fidelity and diversity compared to existing NeRF-based generative models.