 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip-and-Play: Depth-Driven Pose-Preserved Image Generation for Any Objects
Sep 04, 2024



The emergence of diffusion models has enabled the generation of diverse high-quality images solely from text, prompting subsequent efforts to enhance the controllability of these models. Despite the improvement in controllability, pose control remains limited to specific objects (e.g., humans) or poses (e.g., frontal view) due to the fact that pose is generally controlled via camera parameters (e.g., rotation angle) or keypoints (e.g., eyes, nose). Specifically, camera parameters-conditional pose control models generate unrealistic images depending on the object, owing to the small size of 3D datasets for training. Also, keypoint-based approaches encounter challenges in acquiring reliable keypoints for various objects (e.g., church) or poses (e.g., back view). To address these limitations, we propose depth-based pose control, as depth maps are easily obtainable from a single depth estimation model regardless of objects and poses, unlike camera parameters and keypoints. However, depth-based pose control confronts issues of shape dependency, as depth maps influence not only the pose but also the shape of the generated images. To tackle this issue, we propose Skip-and-Play (SnP), designed via analysis of the impact of three components of depth-conditional ControlNet on the pose and the shape of the generated images. To be specific, based on the analysis, we selectively skip parts of the components to mitigate shape dependency on the depth map while preserving the pose. Through various experiments, we demonstrate the superiority of SnP over baselines and showcase the ability of SnP to generate images of diverse objects and poses. Remarkably, SnP exhibits the ability to generate images even when the objects in the condition (e.g., a horse) and the prompt (e.g., a hedgehog) differ from each other.
SideGAN: 3D-Aware Generative Model for Improved Side-View Image Synthesis
Sep 19, 2023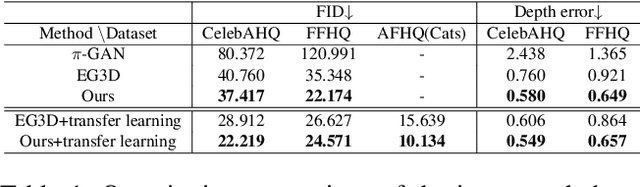
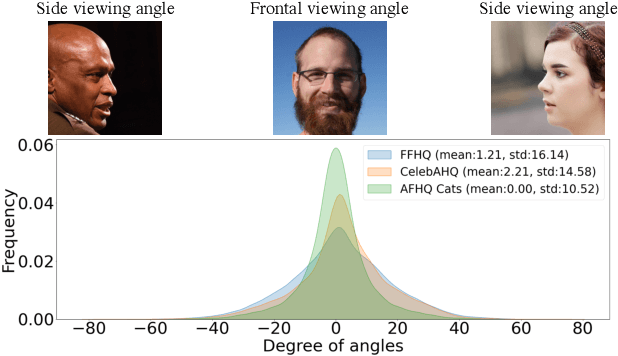

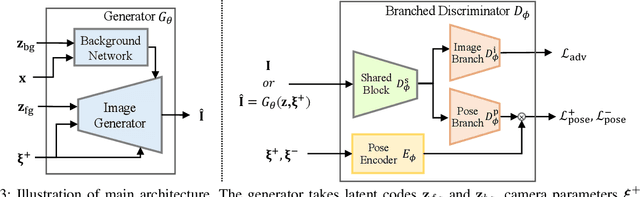
While recent 3D-aware generative models have shown photo-realistic image synthesis with multi-view consistency, the synthesized image quality degrades depending on the camera pose (e.g., a face with a blurry and noisy boundary at a side viewpoint). Such degradation is mainly caused by the difficulty of learning both pose consistency and photo-realism simultaneously from a dataset with heavily imbalanced poses. In this paper, we propose SideGAN, a novel 3D GAN training method to generate photo-realistic images irrespective of the camera pose, especially for faces of side-view angles. To ease the challenging problem of learning photo-realistic and pose-consistent image synthesis, we split the problem into two subproblems, each of which can be solved more easily. Specifically, we formulate the problem as a combination of two simple discrimination problems, one of which learns to discriminate whether a synthesized image looks real or not, and the other learns to discriminate whether a synthesized image agrees with the camera pose. Based on this, we propose a dual-branched discriminator with two discrimination branches. We also propose a pose-matching loss to learn the pose consistency of 3D GANs. In addition, we present a pose sampling strategy to increase learning opportunities for steep angles in a pose-imbalanced dataset. With extensive validation, we demonstrate that our approach enables 3D GANs to generate high-quality geometries and photo-realistic images irrespective of the camera pose.
Perspective Projection-Based 3D CT Reconstruction from Biplanar X-rays
Mar 09, 2023



X-ray computed tomography (CT) is one of the most common imaging techniques used to diagnose various diseases in the medical field. Its high contrast sensitivity and spatial resolution allow the physician to observe details of body parts such as bones, soft tissue, blood vessels, etc. As it involves potentially harmful radiation exposure to patients and surgeons, however, reconstructing 3D CT volume from perpendicular 2D X-ray images is considered a promising alternative, thanks to its lower radiation risk and better accessibility. This is highly challenging though, since it requires reconstruction of 3D anatomical information from 2D images with limited views, where all the information is overlapped. In this paper, we propose PerX2CT, a novel CT reconstruction framework from X-ray that reflects the perspective projection scheme. Our proposed method provides a different combination of features for each coordinate which implicitly allows the model to obtain information about the 3D location. We reveal the potential to reconstruct the selected part of CT with high resolution by properly using the coordinate-wise local and global features. Our approach shows potential for use in clinical applications with low computational complexity and fast inference time, demonstrating superior performance than baselines in multiple evaluation metrics.
CG-NeRF: Conditional Generative Neural Radiance Fields
Dec 07, 2021
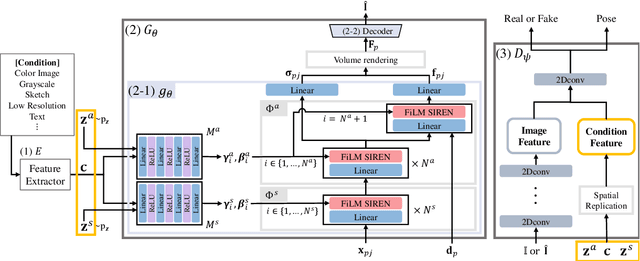


While recent NeRF-based generative models achieve the generation of diverse 3D-aware images, these approaches have limitations when generating images that contain user-specified characteristics. In this paper, we propose a novel model, referred to as the conditional generative neural radiance fields (CG-NeRF), which can generate multi-view images reflecting extra input conditions such as images or texts. While preserving the common characteristics of a given input condition, the proposed model generates diverse images in fine detail. We propose: 1) a novel unified architecture which disentangles the shape and appearance from a condition given in various forms and 2) the pose-consistent diversity loss for generating multimodal outputs while maintaining consistency of the view. Experimental results show that the proposed method maintains consistent image quality on various condition types and achieves superior fidelity and diversity compared to existing NeRF-based generative models.
Evaluation of Out-of-Distribution Detection Performance of Self-Supervised Learning in a Controllable Environment
Nov 26, 2020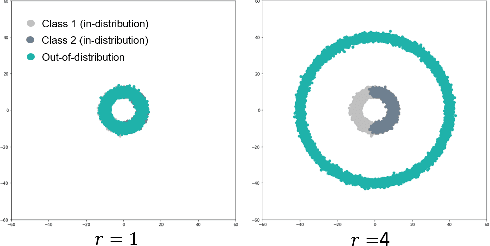

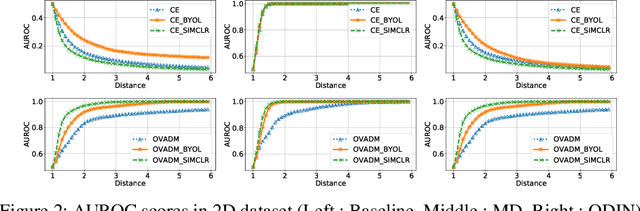
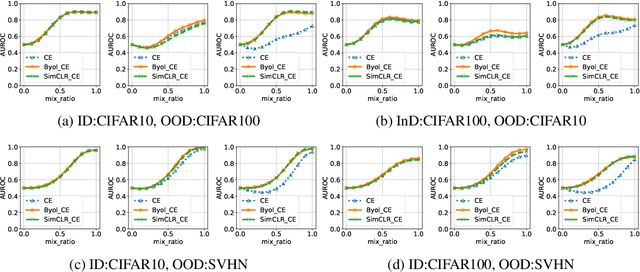
We evaluate the out-of-distribution (OOD) detection performance of self-supervised learning (SSL) techniques with a new evaluation framework. Unlike the previous evaluation methods, the proposed framework adjusts the distance of OOD samples from the in-distribution samples. We evaluate an extensive combination of OOD detection algorithms on three different implementations of the proposed framework using simulated samples, images, and text. SSL methods consistently demonstrated the improved OOD detection performance in all evaluation settings.