 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-NeRF: Conditional Generative Neural Radiance Fields
Paper and Code

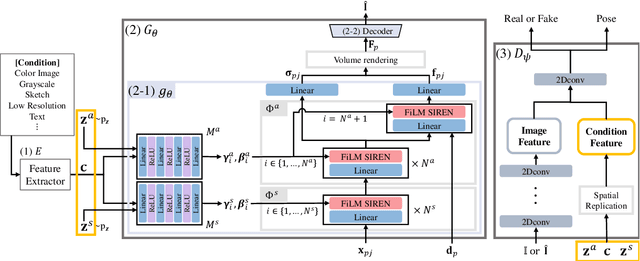


While recent NeRF-based generative models achieve the generation of diverse 3D-aware images, these approaches have limitations when generating images that contain user-specified characteristics. In this paper, we propose a novel model, referred to as the conditional generative neural radiance fields (CG-NeRF), which can generate multi-view images reflecting extra input conditions such as images or texts. While preserving the common characteristics of a given input condition, the proposed model generates diverse images in fine detail. We propose: 1) a novel unified architecture which disentangles the shape and appearance from a condition given in various forms and 2) the pose-consistent diversity loss for generating multimodal outputs while maintaining consistency of the view. Experimental results show that the proposed method maintains consistent image quality on various condition types and achieves superior fidelity and diversity compared to existing NeRF-based generative models.