 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF3: Compact and Fast 3D Feature Fields
Aug 07, 20253D Gaussian Splatting (3DGS) has begun incorporating rich information from 2D foundation models. However, most approaches rely on a bottom-up optimization process that treats raw 2D features as ground truth, incurring increased computational costs. We propose a top-down pipeline for constructing compact and fast 3D Gaussian feature fields, namely, CF3. We first perform a fast weighted fusion of multi-view 2D features with pre-trained Gaussians. This approach enables training a per-Gaussian autoencoder directly on the lifted features, instead of training autoencoders in the 2D domain. As a result, the autoencoder better aligns with the feature distribution. More importantly, we introduce an adaptive sparsification method that optimizes the Gaussian attributes of the feature field while pruning and merging the redundant Gaussians, constructing an efficient representation with preserved geometric details. Our approach achieves a competitive 3D feature field using as little as 5% of the Gaussians compared to Feature-3DGS.
Boost Your Own Human Image Generation Model via Direct Preference Optimization with AI Feedback
May 30, 2024The generation of high-quality human images through text-to-image (T2I) methods is a significant yet challenging task. Distinct from general image generation, human image synthesis must satisfy stringent criteria related to human pose, anatomy, and alignment with textual prompts, making it particularly difficult to achieve realistic results. Recent advancements in T2I generation based on diffusion models have shown promise, yet challenges remain in meeting human-specific preferences. In this paper, we introduce a novel approach tailored specifically for human image generation utilizing Direct Preference Optimization (DPO). Specifically, we introduce an efficient method for constructing a specialized DPO dataset for training human image generation models without the need for costly human feedback. We also propose a modified loss function that enhances the DPO training process by minimizing artifacts and improving image fidelity. Our method demonstrates its versatility and effectiveness in generating human images, including personalized text-to-image generation. Through comprehensive evaluations, we show that our approach significantly advances the state of human image generation, achieving superior results in terms of natural anatomies, poses, and text-image alignment.
SideGAN: 3D-Aware Generative Model for Improved Side-View Image Synthesis
Sep 19, 2023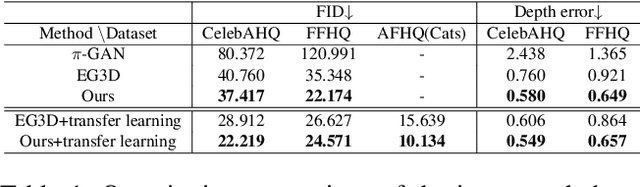
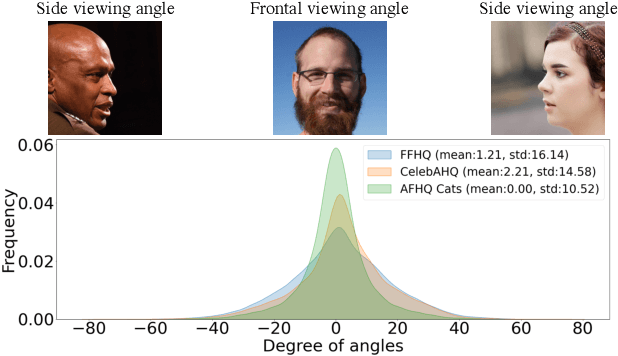

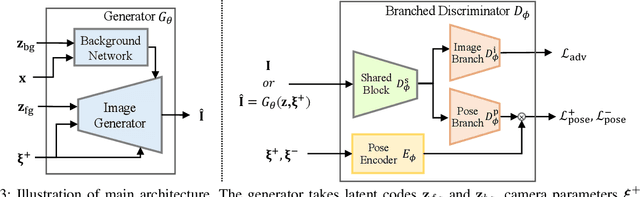
While recent 3D-aware generative models have shown photo-realistic image synthesis with multi-view consistency, the synthesized image quality degrades depending on the camera pose (e.g., a face with a blurry and noisy boundary at a side viewpoint). Such degradation is mainly caused by the difficulty of learning both pose consistency and photo-realism simultaneously from a dataset with heavily imbalanced poses. In this paper, we propose SideGAN, a novel 3D GAN training method to generate photo-realistic images irrespective of the camera pose, especially for faces of side-view angles. To ease the challenging problem of learning photo-realistic and pose-consistent image synthesis, we split the problem into two subproblems, each of which can be solved more easily. Specifically, we formulate the problem as a combination of two simple discrimination problems, one of which learns to discriminate whether a synthesized image looks real or not, and the other learns to discriminate whether a synthesized image agrees with the camera pose. Based on this, we propose a dual-branched discriminator with two discrimination branches. We also propose a pose-matching loss to learn the pose consistency of 3D GANs. In addition, we present a pose sampling strategy to increase learning opportunities for steep angles in a pose-imbalanced dataset. With extensive validation, we demonstrate that our approach enables 3D GANs to generate high-quality geometries and photo-realistic images irrespective of the camera pose.
ContraNeRF: 3D-Aware Generative Model via Contrastive Learning with Unsupervised Implicit Pose Embedding
Apr 27, 2023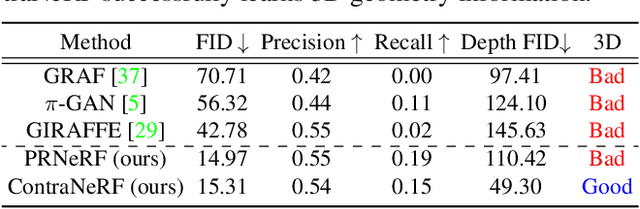
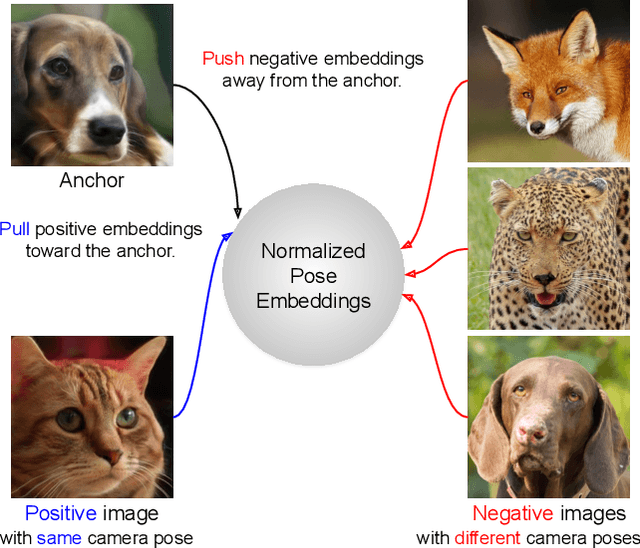
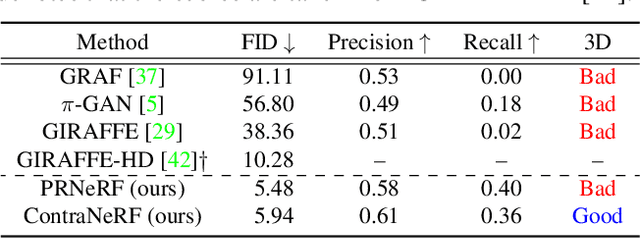
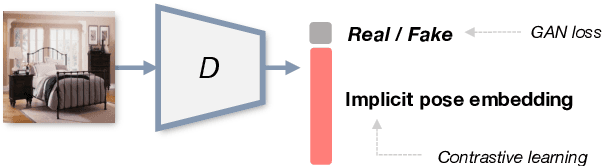
Although 3D-aware GANs based on neural radiance fields have achieved competitive performance, their applicability is still limited to objects or scenes with the ground-truths or prediction models for clearly defined canonical camera poses. To extend the scope of applicable datasets, we propose a novel 3D-aware GAN optimization technique through contrastive learning with implicit pose embeddings. To this end, we first revise the discriminator design and remove dependency on ground-truth camera poses. Then, to capture complex and challenging 3D scene structures more effectively, we make the discriminator estimate a high-dimensional implicit pose embedding from a given image and perform contrastive learning on the pose embedding. The proposed approach can be employed for the dataset, where the canonical camera pose is ill-defined because it does not look up or estimate camera poses. Experimental results show that our algorithm outperforms existing methods by large margins on the datasets with multiple object categories and inconsistent canonical camera poses.
CTRL-C: Camera calibration TRansformer with Line-Classification
Sep 06, 2021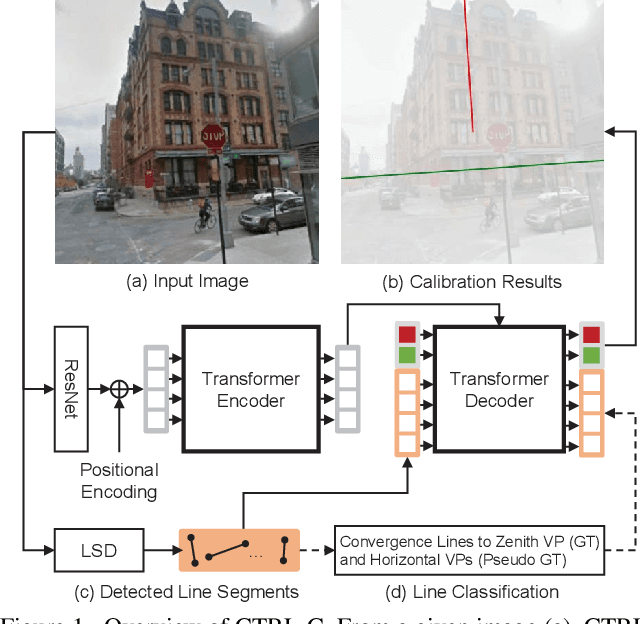
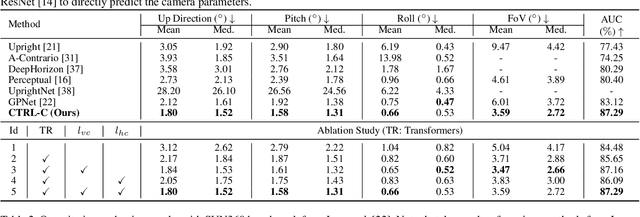
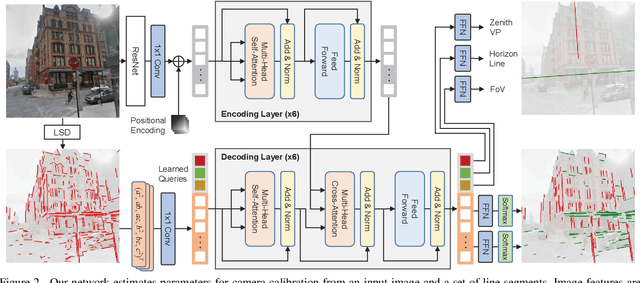
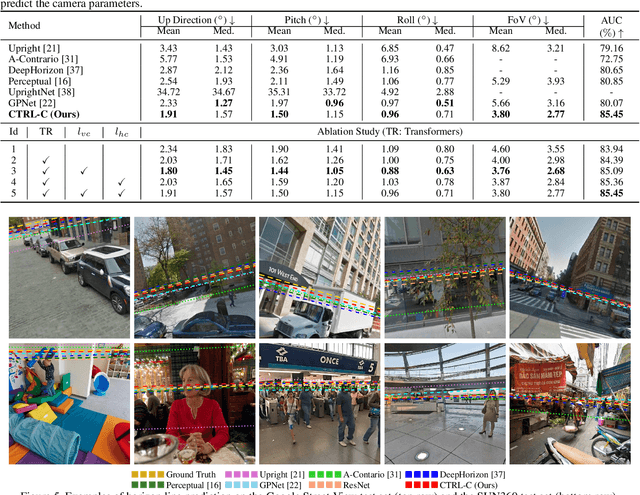
Single image camera calibration is the task of estimating the camera parameters from a single input image, such as the vanishing points, focal length, and horizon line. In this work, we propose Camera calibration TRansformer with Line-Classification (CTRL-C), an end-to-end neural network-based approach to single image camera calibration, which directly estimates the camera parameters from an image and a set of line segments. Our network adopts the transformer architecture to capture the global structure of an image with multi-modal inputs in an end-to-end manner. We also propose an auxiliary task of line classification to train the network to extract the global geometric information from lines effectively. Our experiments demonstrate that CTRL-C outperforms the previous state-of-the-art methods on the Google Street View and SUN360 benchmark datasets.
Neural Geometric Parser for Single Image Camera Calibration
Jul 24, 2020
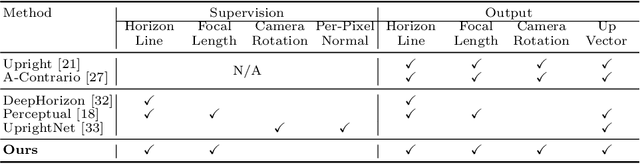
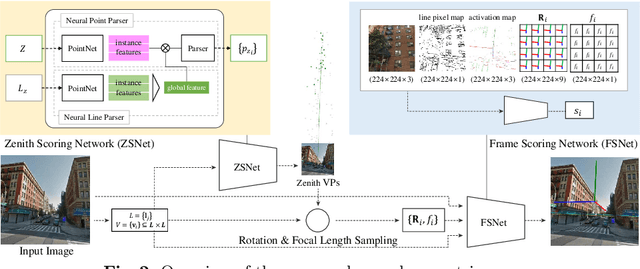
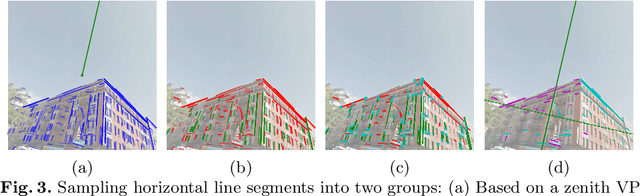
We propose a neural geometric parser learning single image camera calibration for man-made scenes. Unlike previous neural approaches that rely only on semantic cues obtained from neural networks, our approach considers both semantic and geometric cues, resulting in significant accuracy improvement. The proposed framework consists of two networks. Using line segments of an image as geometric cues, the first network estimates the zenith vanishing point and generates several candidates consisting of the camera rotation and focal length. The second network evaluates each candidate based on the given image and the geometric cues, where prior knowledge of man-made scenes is used for the evaluation. With the supervision of datasets consisting of the horizontal line and focal length of the images, our networks can be trained to estimate the same camera parameters. Based on the Manhattan world assumption, we can further estimate the camera rotation and focal length in a weakly supervised manner. The experimental results reveal that the performance of our neural approach is significantly higher than that of existing state-of-the-art camera calibration techniques for single images of indoor and outdoor scenes.