 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Logic Errors: A Comparative Study on Bug Detection by Students and Large Language Models
Nov 27, 2023Identifying and resolving logic errors can be one of the most frustrating challenges for novices programmers. Unlike syntax errors, for which a compiler or interpreter can issue a message, logic errors can be subtle. In certain conditions, buggy code may even exhibit correct behavior -- in other cases, the issue might be about how a problem statement has been interpreted. Such errors can be hard to spot when reading the code, and they can also at times be missed by automated tests. There is great educational potential in automatically detecting logic errors, especially when paired with suitable feedback for novices. Large language models (LLMs) have recently demonstrated surprising performance for a range of computing tasks, including generating and explaining code. These capabilities are closely linked to code syntax, which aligns with the next token prediction behavior of LLMs. On the other hand, logic errors relate to the runtime performance of code and thus may not be as well suited to analysis by LLMs. To explore this, we investigate the performance of two popular LLMs, GPT-3 and GPT-4, for detecting and providing a novice-friendly explanation of logic errors. We compare LLM performance with a large cohort of introductory computing students $(n=964)$ solving the same error detection task. Through a mixed-methods analysis of student and model responses, we observe significant improvement in logic error identification between the previous and current generation of LLMs, and find that both LLM generations significantly outperform students. We outline how such models could be integrated into computing education tools, and discuss their potential for supporting students when learning programming.
Comparing Code Explanations Created by Students and Large Language Models
Apr 08, 2023Reasoning about code and explaining its purpose are fundamental skills for computer scientists. There has been extensive research in the field of computing education on the relationship between a student's ability to explain code and other skills such as writing and tracing code. In particular, the ability to describe at a high-level of abstraction how code will behave over all possible inputs correlates strongly with code writing skills. However, developing the expertise to comprehend and explain code accurately and succinctly is a challenge for many students. Existing pedagogical approaches that scaffold the ability to explain code, such as producing exemplar code explanations on demand, do not currently scale well to large classrooms. The recent emergence of powerful large language models (LLMs) may offer a solution. In this paper, we explore the potential of LLMs in generating explanations that can serve as examples to scaffold students' ability to understand and explain code. To evaluate LLM-created explanations, we compare them with explanations created by students in a large course ($n \approx 1000$) with respect to accuracy, understandability and length. We find that LLM-created explanations, which can be produced automatically on demand, are rated as being significantly easier to understand and more accurate summaries of code than student-created explanations. We discuss the significance of this finding, and suggest how such models can be incorporated into introductory programming education.
RobustNet: Improving Domain Generalization in Urban-Scene Segmentation via Instance Selective Whitening
Mar 31, 2021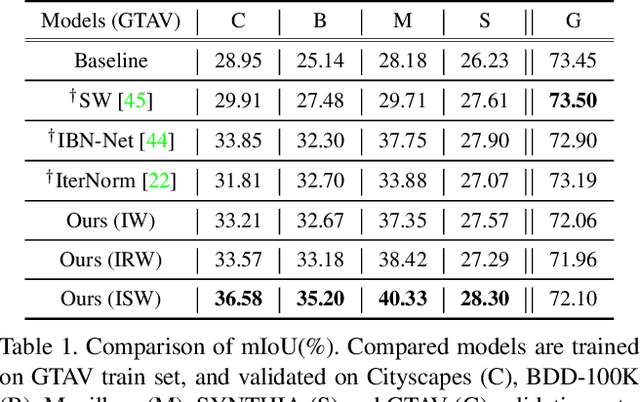


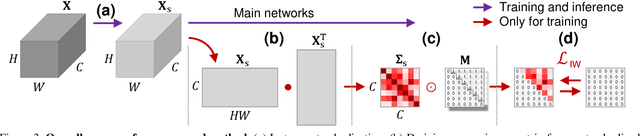
Enhancing the generalization capability of deep neural networks to unseen domains is crucial for safety-critical applications in the real world such as autonomous driving. To address this issue, this paper proposes a novel instance selective whitening loss to improve the robustness of the segmentation networks for unseen domains. Our approach disentangles the domain-specific style and domain-invariant content encoded in higher-order statistics (i.e., feature covariance) of the feature representations and selectively removes only the style information causing domain shift. As shown in Fig. 1, our method provides reasonable predictions for (a) low-illuminated, (b) rainy, and (c) unseen structures. These types of images are not included in the training dataset, where the baseline shows a significant performance drop, contrary to ours. Being simple yet effective, our approach improves the robustness of various backbone networks without additional computational cost. We conduct extensive experiments in urban-scene segmentation and show the superiority of our approach to existing work. Our code is available at https://github.com/shachoi/RobustNet.