 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Decomposed Dual-domain Deep Learning for Sparse-View CT Reconstruction
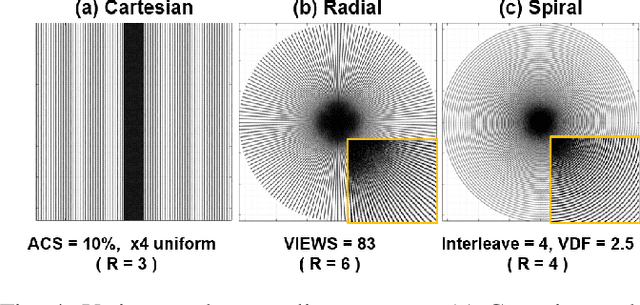
Jan 09, 2025Objective: X-ray computed tomography employing sparse projection views has emerged as a contemporary technique to mitigate radiation dose. However, due to the inadequate number of projection views, an analytic reconstruction method utilizing filtered backprojection results in severe streaking artifacts. Recently, deep learning strategies employing image-domain networks have demonstrated remarkable performance in eliminating the streaking artifact caused by analytic reconstruction methods with sparse projection views. Nevertheless, it is difficult to clarify the theoretical justification for applying deep learning to sparse view CT reconstruction, and it has been understood as restoration by removing image artifacts, not reconstruction. Approach: By leveraging the theory of deep convolutional framelets and the hierarchical decomposition of measurement, this research reveals the constraints of conventional image- and projection-domain deep learning methodologies, subsequently, the research proposes a novel dual-domain deep learning framework utilizing hierarchical decomposed measurements. Specifically, the research elucidates how the performance of the projection-domain network can be enhanced through a low-rank property of deep convolutional framelets and a bowtie support of hierarchical decomposed measurement in the Fourier domain. Main Results: This study demonstrated performance improvement of the proposed framework based on the low-rank property, resulting in superior reconstruction performance compared to conventional analytic and deep learning methods. Significance: By providing a theoretically justified deep learning approach for sparse-view CT reconstruction, this study not only offers a superior alternative to existing methods but also opens new avenues for research in medical imaging.
End-to-End Deep Learning for Interior Tomography with Low-Dose X-ray CT
Jan 09, 2025Objective: There exist several X-ray computed tomography (CT) scanning strategies to reduce a radiation dose, such as (1) sparse-view CT, (2) low-dose CT, and (3) region-of-interest (ROI) CT (called interior tomography). To further reduce the dose, the sparse-view and/or low-dose CT settings can be applied together with interior tomography. Interior tomography has various advantages in terms of reducing the number of detectors and decreasing the X-ray radiation dose. However, a large patient or small field-of-view (FOV) detector can cause truncated projections, and then the reconstructed images suffer from severe cupping artifacts. In addition, although the low-dose CT can reduce the radiation exposure dose, analytic reconstruction algorithms produce image noise. Recently, many researchers have utilized image-domain deep learning (DL) approaches to remove each artifact and demonstrated impressive performances, and the theory of deep convolutional framelets supports the reason for the performance improvement. Approach: In this paper, we found that the image-domain convolutional neural network (CNN) is difficult to solve coupled artifacts, based on deep convolutional framelets. Significance: To address the coupled problem, we decouple it into two sub-problems: (i) image domain noise reduction inside truncated projection to solve low-dose CT problem and (ii) extrapolation of projection outside truncated projection to solve the ROI CT problem. The decoupled sub-problems are solved directly with a novel proposed end-to-end learning using dual-domain CNNs. Main results: We demonstrate that the proposed method outperforms the conventional image-domain deep learning methods, and a projection-domain CNN shows better performance than the image-domain CNNs which are commonly used by many researchers.
Distance Sampling-based Paraphraser Leveraging ChatGPT for Text Data Manipulation
May 01, 2024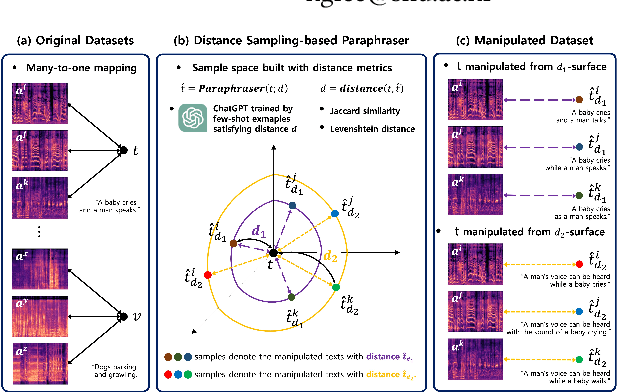
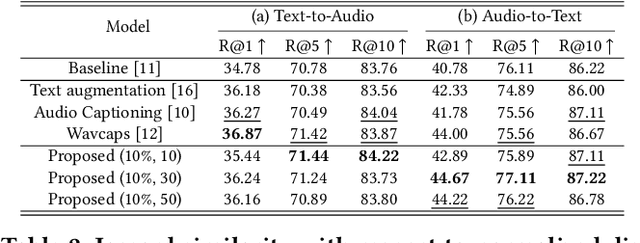
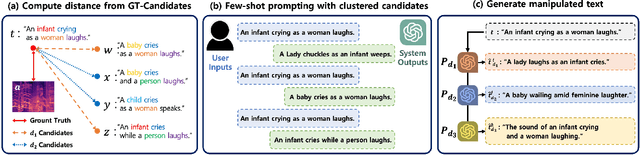
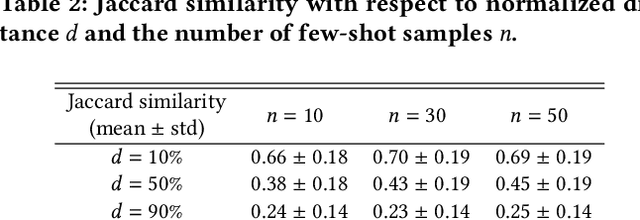
There has been growing interest in audio-language retrieval research, where the objective is to establish the correlation between audio and text modalities. However, most audio-text paired datasets often lack rich expression of the text data compared to the audio samples. One of the significant challenges facing audio-text datasets is the presence of similar or identical captions despite different audio samples. Therefore, under many-to-one mapping conditions, audio-text datasets lead to poor performance of retrieval tasks. In this paper, we propose a novel approach to tackle the data imbalance problem in audio-language retrieval task. To overcome the limitation, we introduce a method that employs a distance sampling-based paraphraser leveraging ChatGPT, utilizing distance function to generate a controllable distribution of manipulated text data. For a set of sentences with the same context, the distance is used to calculate a degree of manipulation for any two sentences, and ChatGPT's few-shot prompting is performed using a text cluster with a similar distance defined by the Jaccard similarity. Therefore, ChatGPT, when applied to few-shot prompting with text clusters, can adjust the diversity of the manipulated text based on the distance. The proposed approach is shown to significantly enhance performance in audio-text retrieval, outperforming conventional text augmentation techniques.
Continuous Emotional Intensity Controllable Speech Synthesis using Semi-supervised Learning
Nov 11, 2022With the rapid development of the speech synthesis system, recent text-to-speech models have reached the level of generating natural speech similar to what humans say. But there still have limitations in terms of expressiveness. In particular, the existing emotional speech synthesis models have shown controllability using interpolated features with scaling parameters in emotional latent space. However, the emotional latent space generated from the existing models is difficult to control the continuous emotional intensity because of the entanglement of features like emotions, speakers, etc. In this paper, we propose a novel method to control the continuous intensity of emotions using semi-supervised learning. The model learns emotions of intermediate intensity using pseudo-labels generated from phoneme-level sequences of speech information. An embedding space built from the proposed model satisfies the uniform grid geometry with an emotional basis. In addition, to improve the naturalness of intermediate emotional speech, a discriminator is applied to the generation of low-level elements like duration, pitch and energy. The experimental results showed that the proposed method was superior in controllability and naturalness. The synthesized speech samples are available at https://tinyurl.com/34zaehh2
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020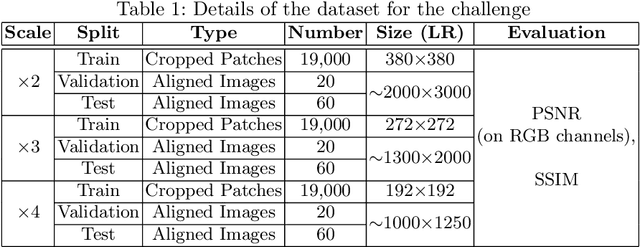
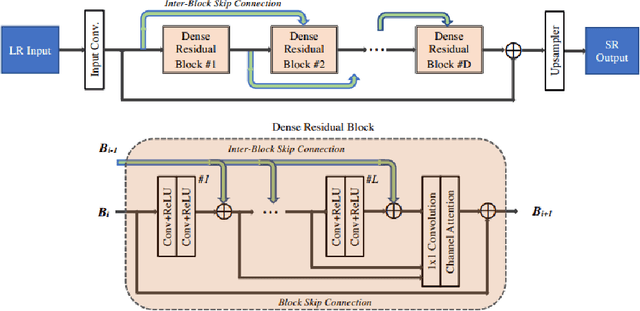
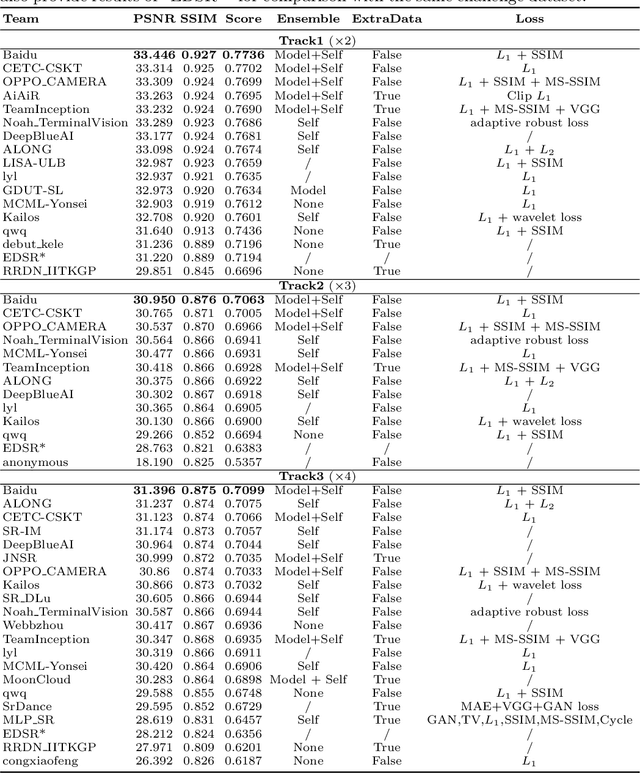
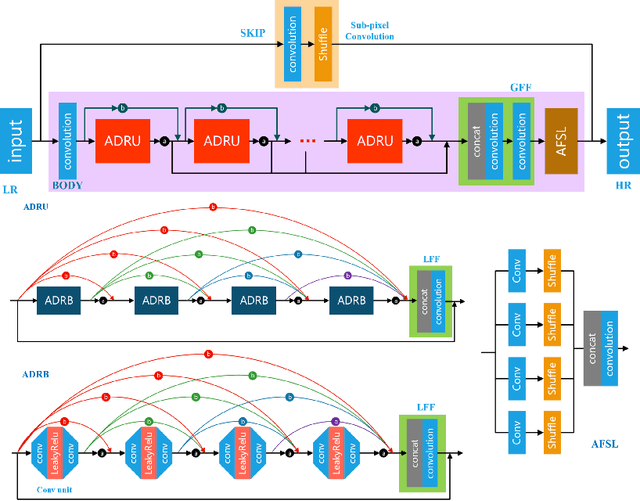
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
Differentiated Backprojection Domain Deep Learning for Conebeam Artifact Removal
Jun 17, 2019
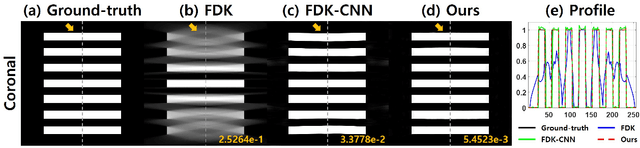
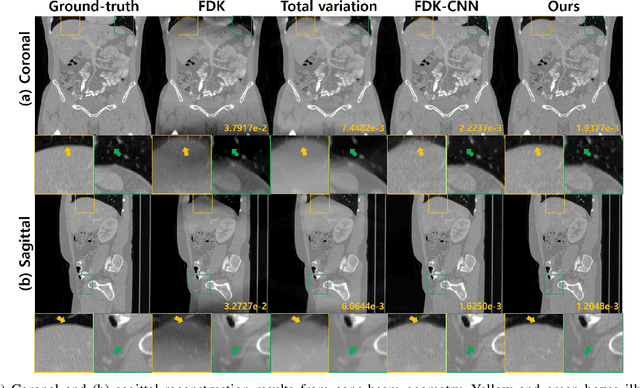
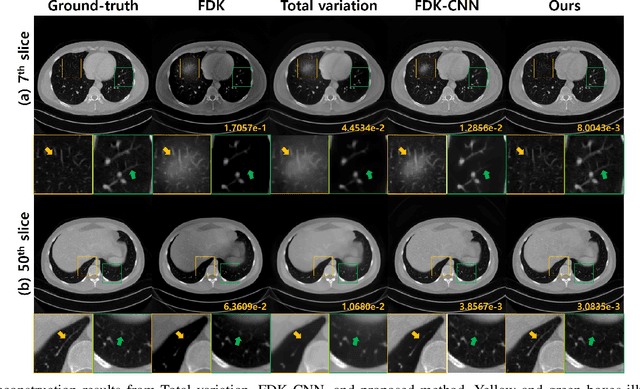
Conebeam CT using a circular trajectory is quite often used for various applications due to its relative simple geometry. For conebeam geometry, Feldkamp, Davis and Kress algorithm is regarded as the standard reconstruction method, but this algorithm suffers from so-called conebeam artifacts as the cone angle increases. Various model-based iterative reconstruction methods have been developed to reduce the cone-beam artifacts, but these algorithms usually require multiple applications of computational expensive forward and backprojections. In this paper, we develop a novel deep learning approach for accurate conebeam artifact removal. In particular, our deep network, designed on the differentiated backprojection domain, performs a data-driven inversion of an ill-posed deconvolution problem associated with the Hilbert transform. The reconstruction results along the coronal and sagittal directions are then combined using a spectral blending technique to minimize the spectral leakage. Experimental results show that our method outperforms the existing iterative methods despite significantly reduced runtime complexity.
One Network to Solve All ROIs: Deep Learning CT for Any ROI using Differentiated Backprojection
Oct 01, 2018
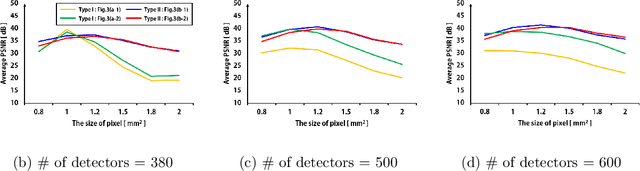

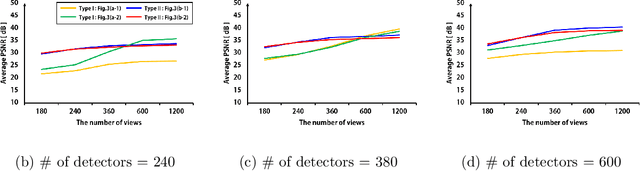
Computed tomography for region-of-interest (ROI) reconstruction has advantages of reducing X-ray radiation dose and using a small detector. However, standard analytic reconstruction methods suffer from severe cupping artifacts, and existing model-based iterative reconstruction methods require extensive computations. Recently, we proposed a deep neural network to learn the cupping artifact, but the network is not well generalized for different ROIs due to the singularities in the corrupted images. Therefore, there is an increasing demand for a neural network that works well for any ROI sizes. In this paper, two types of neural networks are designed. The first type learns ROI size-specific cupping artifacts from the analytic reconstruction images, whereas the second type network is to learn to invert the finite Hilbert transform from the truncated differentiated backprojection (DBP) data. Their generalizability for any ROI sizes is then examined. Experimental results show that the new type of neural network significantly outperforms the existing iterative methods for any ROI size in spite of significantly reduced run-time complexity. Since the proposed method consistently surpasses existing methods for any ROIs, it can be used as a general CT reconstruction engine for many practical applications without compromising possible detector truncation.
k-Space Deep Learning for Reference-free EPI Ghost Correction
Jun 10, 2018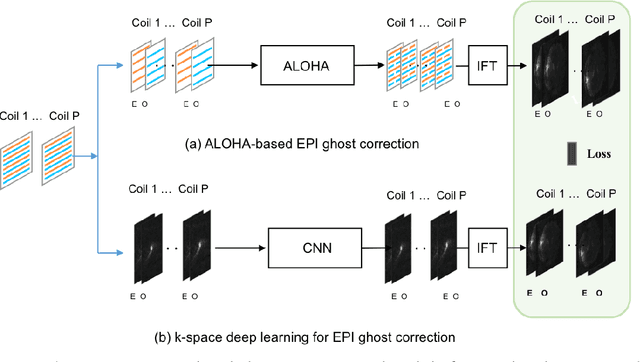
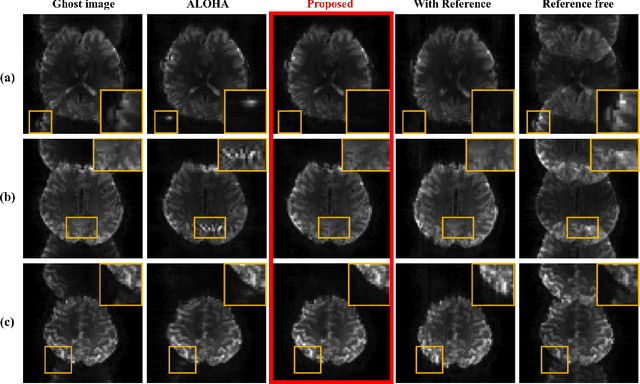
Nyquist ghost artifacts in EPI images are originated from phase mismatch between the even and odd echoes. However, conventional correction methods using reference scans often produce erroneous results especially in high-field MRI due to the non-linear and time-varying local magnetic field changes. Recently, it was shown that the problem of ghost correction can be transformed into k-space data interpolation problem that can be solved using the annihilating filter-based low-rank Hankel structured matrix completion approach (ALOHA). Another recent discovery has shown that the deep convolutional neural network is closely related to the data-driven Hankel matrix decomposition. By synergistically combining these findings, here we propose a k-space deep learning approach that immediately corrects the k-space phase mismatch without a reference scan. Reconstruction results using 7T in vivo data showed that the proposed reference-free k-space deep learning approach for EPI ghost correction significantly improves the image quality compared to the existing methods, and the computing time is several orders of magnitude faster.
k-Space Deep Learning for Accelerated MRI
May 10, 2018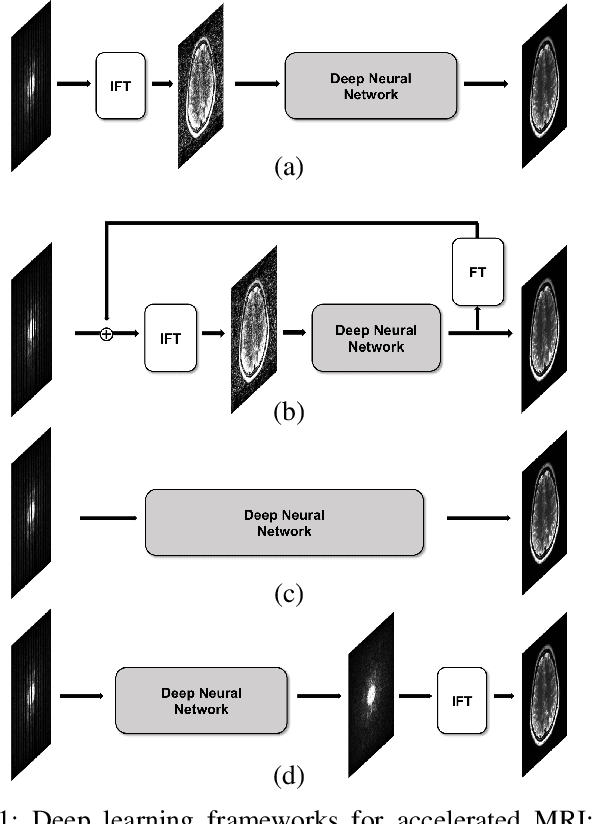
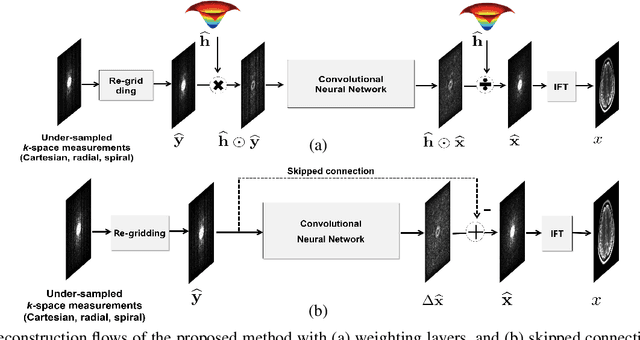
The annihilating filter-based low-rank Hanel matrix approach (ALOHA) is one of the state-of-the-art compressed sensing approaches that directly interpolates the missing k-space data using low-rank Hankel matrix completion. Inspired by the recent mathematical discovery that links deep neural networks to Hankel matrix decomposition using data-driven framelet basis, here we propose a fully data-driven deep learning algorithm for k-space interpolation. Our network can be also easily applied to non-Cartesian k-space trajectories by simply adding an additional re-gridding layer. Extensive numerical experiments show that the proposed deep learning method significantly outperforms the existing image-domain deep learning approaches.
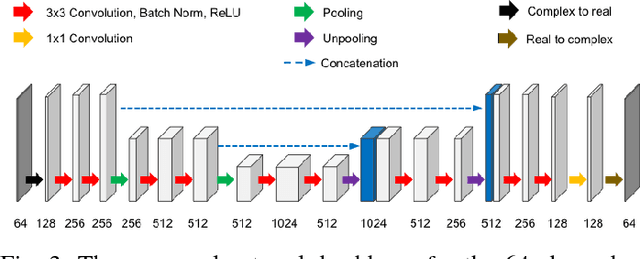
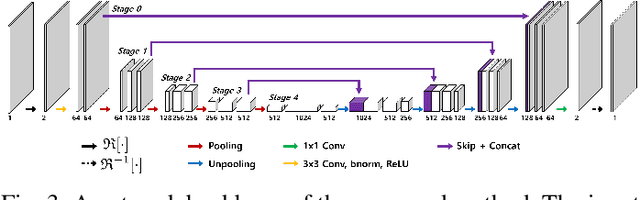
Framing U-Net via Deep Convolutional Framelets: Application to Sparse-view CT
Mar 28, 2018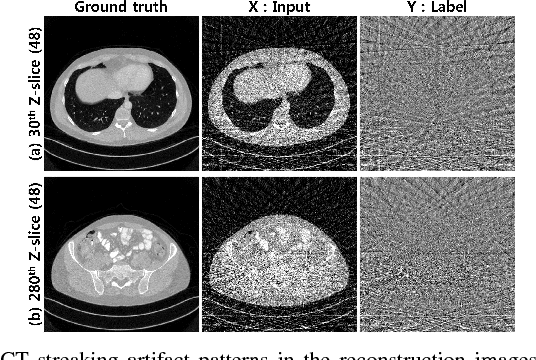
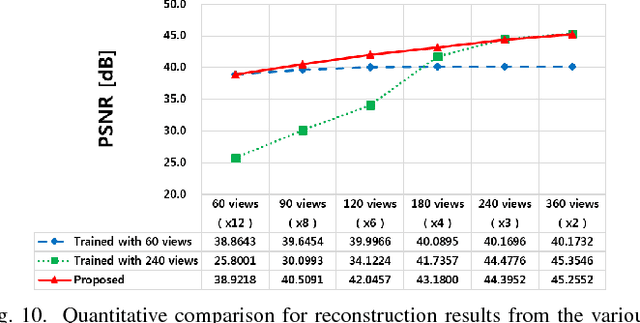
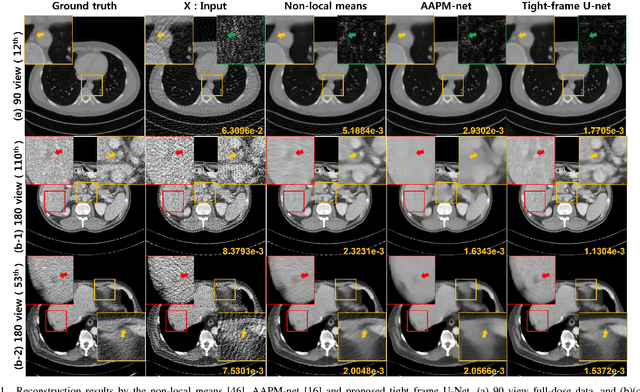
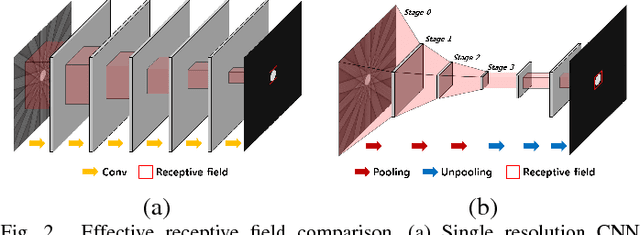
X-ray computed tomography (CT) using sparse projection views is a recent approach to reduce the radiation dose. However, due to the insufficient projection views, an analytic reconstruction approach using the filtered back projection (FBP) produces severe streaking artifacts. Recently, deep learning approaches using large receptive field neural networks such as U-Net have demonstrated impressive performance for sparse- view CT reconstruction. However, theoretical justification is still lacking. Inspired by the recent theory of deep convolutional framelets, the main goal of this paper is, therefore, to reveal the limitation of U-Net and propose new multi-resolution deep learning schemes. In particular, we show that the alternative U- Net variants such as dual frame and the tight frame U-Nets satisfy the so-called frame condition which make them better for effective recovery of high frequency edges in sparse view- CT. Using extensive experiments with real patient data set, we demonstrate that the new network architectures provide better reconstruction performance.