 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleSumm: Adaptive Triple-Modality Fusion for Video Summarization
Mar 01, 2026The exponential growth of video content necessitates effective video summarization to efficiently extract key information from long videos. However, current approaches struggle to fully comprehend complex videos, primarily because they employ static or modality-agnostic fusion strategies. These methods fail to account for the dynamic, frame-dependent variations in modality saliency inherent in video data. To overcome these limitations, we propose TripleSumm, a novel architecture that adaptively weights and fuses the contributions of visual, text, and audio modalities at the frame level. Furthermore, a significant bottleneck for research into multimodal video summarization has been the lack of comprehensive benchmarks. Addressing this bottleneck, we introduce MoSu (Most Replayed Multimodal Video Summarization), the first large-scale benchmark that provides all three modalities. Extensive experiments demonstrate that TripleSumm achieves state-of-the-art performance, outperforming existing methods by a significant margin on four benchmarks, including MoSu. Our code and dataset are available at https://github.com/smkim37/TripleSumm.
Sounding Highlights: Dual-Pathway Audio Encoders for Audio-Visual Video Highlight Detection
Feb 05, 2026Audio-visual video highlight detection aims to automatically identify the most salient moments in videos by leveraging both visual and auditory cues. However, existing models often underutilize the audio modality, focusing on high-level semantic features while failing to fully leverage the rich, dynamic characteristics of sound. To address this limitation, we propose a novel framework, Dual-Pathway Audio Encoders for Video Highlight Detection (DAViHD). The dual-pathway audio encoder is composed of a semantic pathway for content understanding and a dynamic pathway that captures spectro-temporal dynamics. The semantic pathway extracts high-level information by identifying the content within the audio, such as speech, music, or specific sound events. The dynamic pathway employs a frequency-adaptive mechanism as time evolves to jointly model these dynamics, enabling it to identify transient acoustic events via salient spectral bands and rapid energy changes. We integrate the novel audio encoder into a full audio-visual framework and achieve new state-of-the-art performance on the large-scale MrHiSum benchmark. Our results demonstrate that a sophisticated, dual-faceted audio representation is key to advancing the field of highlight detection.
Hear Your Face: Face-based voice conversion with F0 estimation
Aug 19, 2024



This paper delves into the emerging field of face-based voice conversion, leveraging the unique relationship between an individual's facial features and their vocal characteristics. We present a novel face-based voice conversion framework that particularly utilizes the average fundamental frequency of the target speaker, derived solely from their facial images. Through extensive analysis, our framework demonstrates superior speech generation quality and the ability to align facial features with voice characteristics, including tracking of the target speaker's fundamental frequency.
Distance Sampling-based Paraphraser Leveraging ChatGPT for Text Data Manipulation
May 01, 2024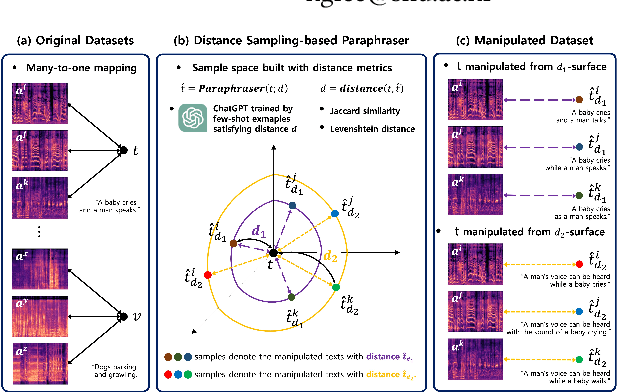
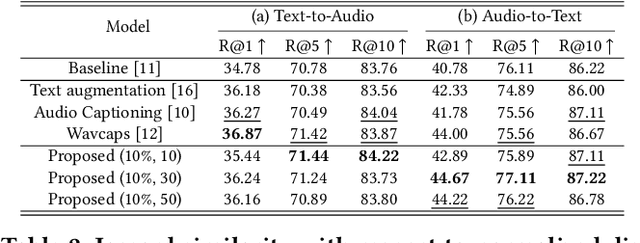
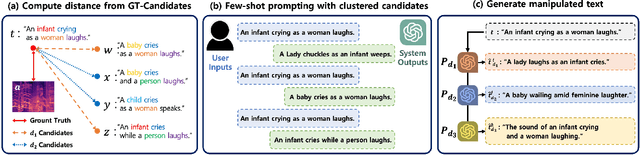
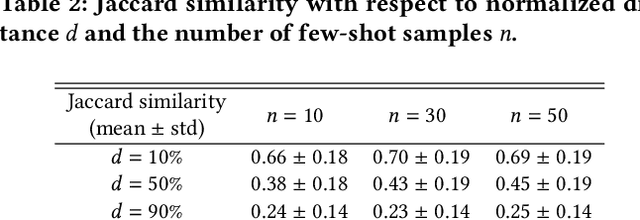
There has been growing interest in audio-language retrieval research, where the objective is to establish the correlation between audio and text modalities. However, most audio-text paired datasets often lack rich expression of the text data compared to the audio samples. One of the significant challenges facing audio-text datasets is the presence of similar or identical captions despite different audio samples. Therefore, under many-to-one mapping conditions, audio-text datasets lead to poor performance of retrieval tasks. In this paper, we propose a novel approach to tackle the data imbalance problem in audio-language retrieval task. To overcome the limitation, we introduce a method that employs a distance sampling-based paraphraser leveraging ChatGPT, utilizing distance function to generate a controllable distribution of manipulated text data. For a set of sentences with the same context, the distance is used to calculate a degree of manipulation for any two sentences, and ChatGPT's few-shot prompting is performed using a text cluster with a similar distance defined by the Jaccard similarity. Therefore, ChatGPT, when applied to few-shot prompting with text clusters, can adjust the diversity of the manipulated text based on the distance. The proposed approach is shown to significantly enhance performance in audio-text retrieval, outperforming conventional text augmentation techniques.
Continuous Emotional Intensity Controllable Speech Synthesis using Semi-supervised Learning
Nov 11, 2022With the rapid development of the speech synthesis system, recent text-to-speech models have reached the level of generating natural speech similar to what humans say. But there still have limitations in terms of expressiveness. In particular, the existing emotional speech synthesis models have shown controllability using interpolated features with scaling parameters in emotional latent space. However, the emotional latent space generated from the existing models is difficult to control the continuous emotional intensity because of the entanglement of features like emotions, speakers, etc. In this paper, we propose a novel method to control the continuous intensity of emotions using semi-supervised learning. The model learns emotions of intermediate intensity using pseudo-labels generated from phoneme-level sequences of speech information. An embedding space built from the proposed model satisfies the uniform grid geometry with an emotional basis. In addition, to improve the naturalness of intermediate emotional speech, a discriminator is applied to the generation of low-level elements like duration, pitch and energy. The experimental results showed that the proposed method was superior in controllability and naturalness. The synthesized speech samples are available at https://tinyurl.com/34zaehh2
Improving Audio-Language Learning with MixGen and Multi-Level Test-Time Augmentation
Oct 31, 2022



In this paper, we propose two novel augmentation methods 1) audio-language MixGen (AL-MixGen) and 2) multi-level test-time augmentation (Multi-TTA) for audio-language learning. Inspired by MixGen, which is originally applied to vision-language learning, we introduce an augmentation method for the audio-language domain. We also explore the impact of test-time augmentations and present Multi-TTA which generalizes test-time augmentation over multiple layers of a deep learning model. Incorporating AL-MixGen and Multi-TTA into the baseline achieves 47.5 SPIDEr on audio captioning, which is an +18.2% over the baseline and outperforms the state-of-the-art approach with a 5x smaller model. In audio-text retrieval, the proposed methods surpass the baseline performance as well.