 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHear Your Face: Face-based voice conversion with F0 estimation
Aug 19, 2024



This paper delves into the emerging field of face-based voice conversion, leveraging the unique relationship between an individual's facial features and their vocal characteristics. We present a novel face-based voice conversion framework that particularly utilizes the average fundamental frequency of the target speaker, derived solely from their facial images. Through extensive analysis, our framework demonstrates superior speech generation quality and the ability to align facial features with voice characteristics, including tracking of the target speaker's fundamental frequency.
Representation Learning on Hyper-Relational and Numeric Knowledge Graphs with Transformers
Jun 01, 2023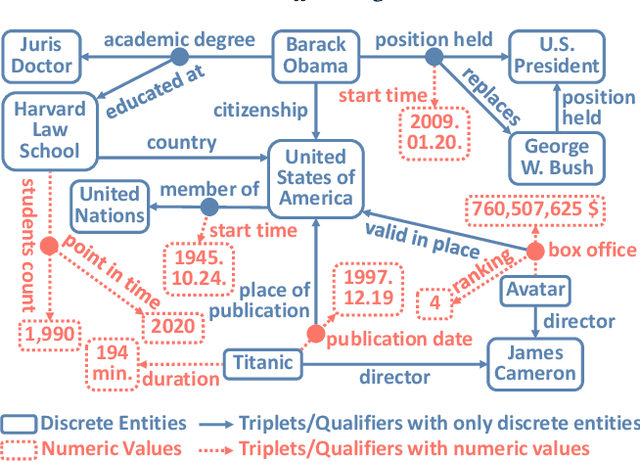
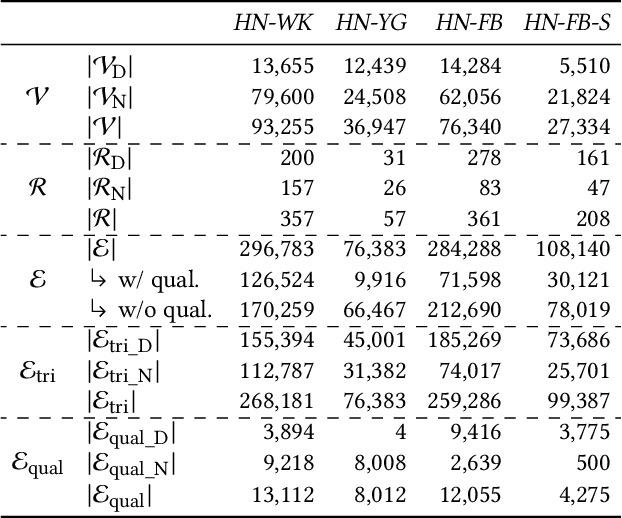
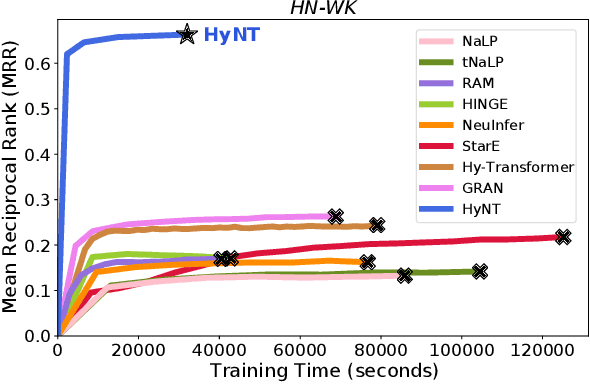
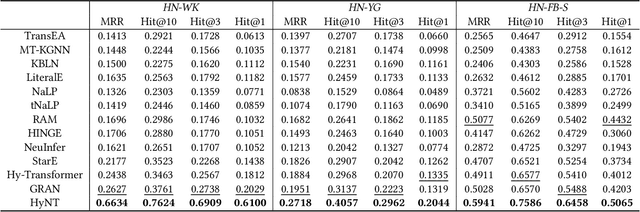
A hyper-relational knowledge graph has been recently studied where a triplet is associated with a set of qualifiers; a qualifier is composed of a relation and an entity, providing auxiliary information for a triplet. While existing hyper-relational knowledge graph embedding methods assume that the entities are discrete objects, some information should be represented using numeric values, e.g., (J.R.R., was born in, 1892). Also, a triplet (J.R.R., educated at, Oxford Univ.) can be associated with a qualifier such as (start time, 1911). In this paper, we propose a unified framework named HyNT that learns representations of a hyper-relational knowledge graph containing numeric literals in either triplets or qualifiers. We define a context transformer and a prediction transformer to learn the representations based not only on the correlations between a triplet and its qualifiers but also on the numeric information. By learning compact representations of triplets and qualifiers and feeding them into the transformers, we reduce the computation cost of using transformers. Using HyNT, we can predict missing numeric values in addition to missing entities or relations in a hyper-relational knowledge graph. Experimental results show that HyNT significantly outperforms state-of-the-art methods on real-world datasets.
InGram: Inductive Knowledge Graph Embedding via Relation Graphs
Jun 01, 2023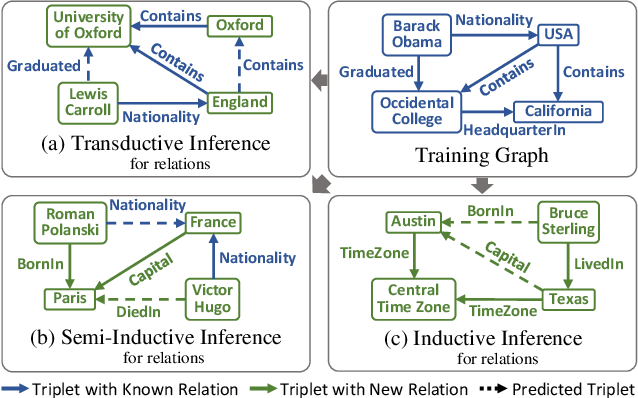
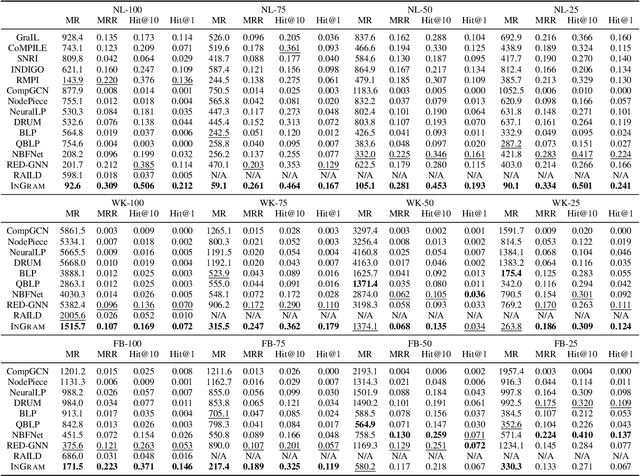
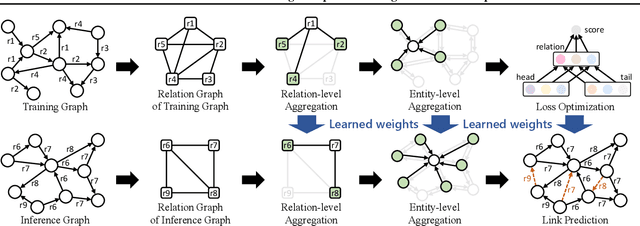
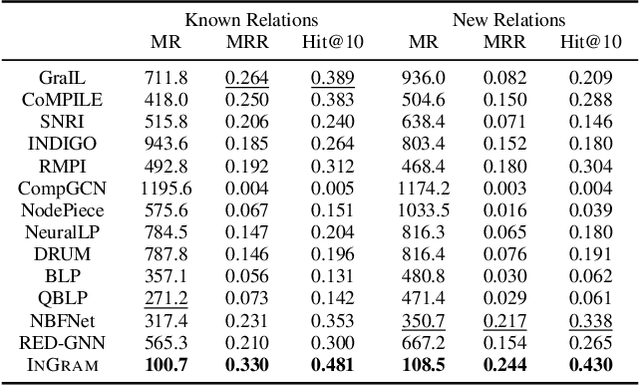
Inductive knowledge graph completion has been considered as the task of predicting missing triplets between new entities that are not observed during training. While most inductive knowledge graph completion methods assume that all entities can be new, they do not allow new relations to appear at inference time. This restriction prohibits the existing methods from appropriately handling real-world knowledge graphs where new entities accompany new relations. In this paper, we propose an INductive knowledge GRAph eMbedding method, InGram, that can generate embeddings of new relations as well as new entities at inference time. Given a knowledge graph, we define a relation graph as a weighted graph consisting of relations and the affinity weights between them. Based on the relation graph and the original knowledge graph, InGram learns how to aggregate neighboring embeddings to generate relation and entity embeddings using an attention mechanism. Experimental results show that InGram outperforms 14 different state-of-the-art methods on varied inductive learning scenarios.
Room adaptive conditioning method for sound event classification in reverberant environments
Apr 21, 2021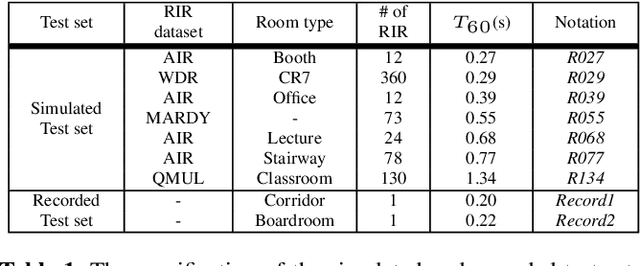
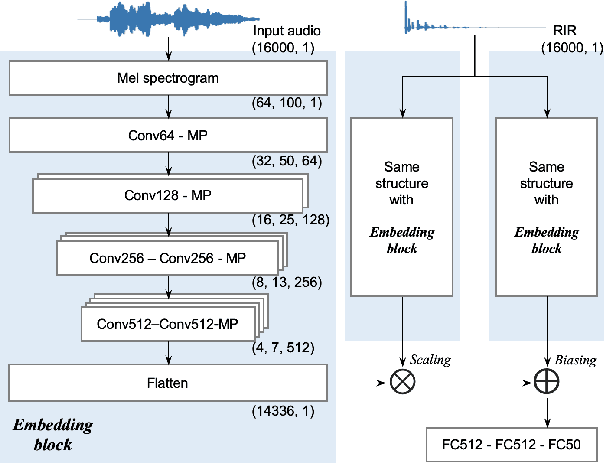
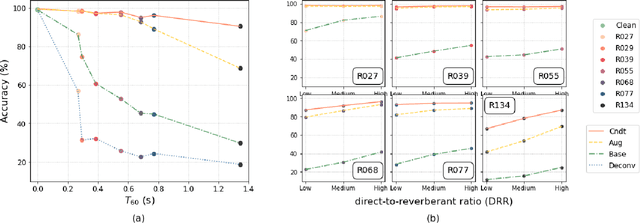
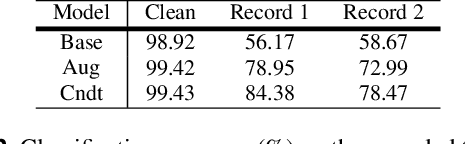
Ensuring performance robustness for a variety of situations that can occur in real-world environments is one of the challenging tasks in sound event classification. One of the unpredictable and detrimental factors in performance, especially in indoor environments, is reverberation. To alleviate this problem, we propose a conditioning method that provides room impulse response (RIR) information to help the network become less sensitive to environmental information and focus on classifying the desired sound. Experimental results show that the proposed method successfully reduced performance degradation caused by the reverberation of the room. In particular, our proposed method works even with similar RIR that can be inferred from the room type rather than the exact one, which has the advantage of potentially being used in real-world applications.
Howl: A Deployed, Open-Source Wake Word Detection System
Aug 21, 2020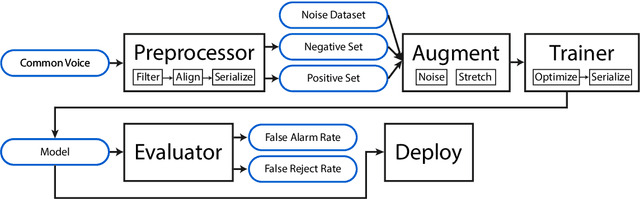
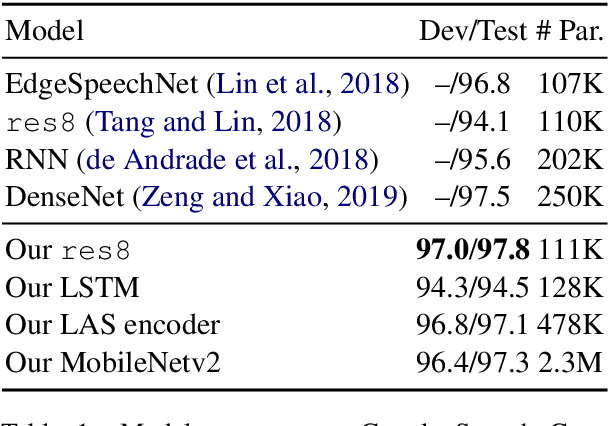
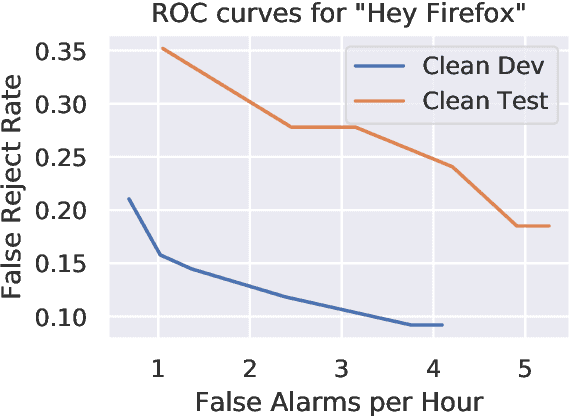
We describe Howl, an open-source wake word detection toolkit with native support for open speech datasets, like Mozilla Common Voice and Google Speech Commands. We report benchmark results on Speech Commands and our own freely available wake word detection dataset, built from MCV. We operationalize our system for Firefox Voice, a plugin enabling speech interactivity for the Firefox web browser. Howl represents, to the best of our knowledge, the first fully productionized yet open-source wake word detection toolkit with a web browser deployment target. Our codebase is at https://github.com/castorini/howl.
Showing Your Work Doesn't Always Work
Apr 28, 2020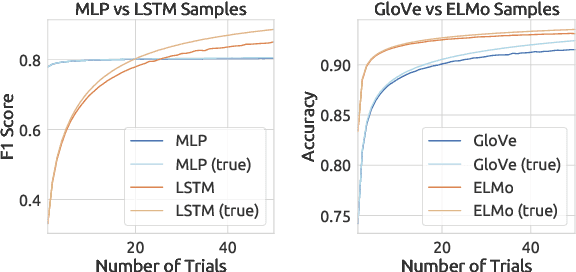

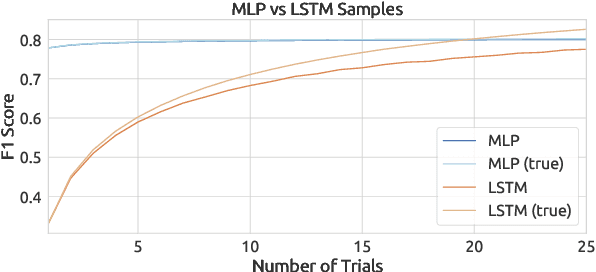
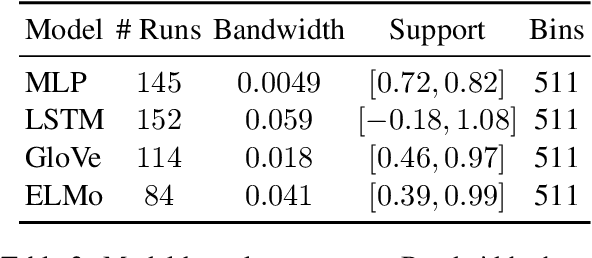
In natural language processing, a recently popular line of work explores how to best report the experimental results of neural networks. One exemplar publication, titled "Show Your Work: Improved Reporting of Experimental Results," advocates for reporting the expected validation effectiveness of the best-tuned model, with respect to the computational budget. In the present work, we critically examine this paper. As far as statistical generalizability is concerned, we find unspoken pitfalls and caveats with this approach. We analytically show that their estimator is biased and uses error-prone assumptions. We find that the estimator favors negative errors and yields poor bootstrapped confidence intervals. We derive an unbiased alternative and bolster our claims with empirical evidence from statistical simulation. Our codebase is at http://github.com/castorini/meanmax.
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
Apr 27, 2020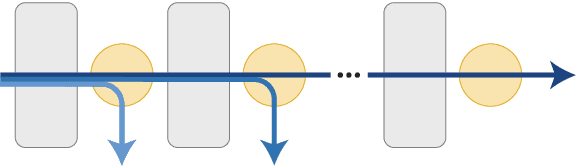
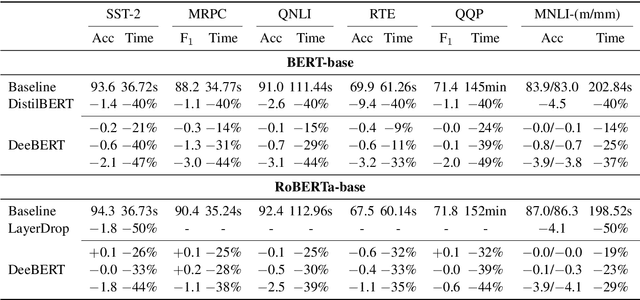
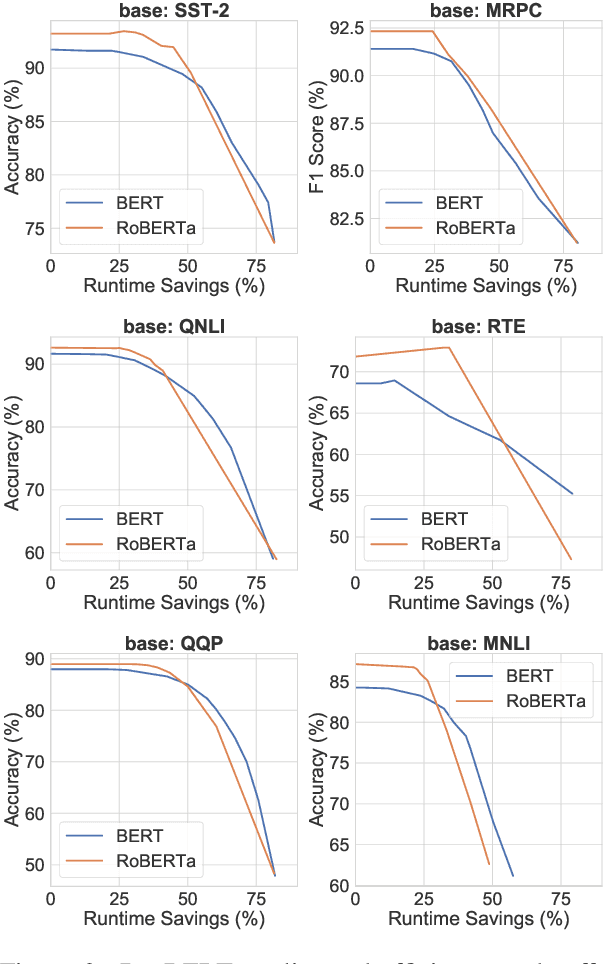
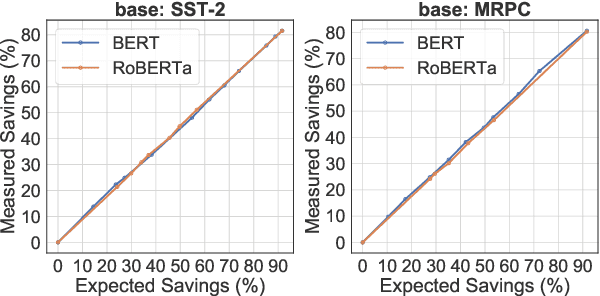
Large-scale pre-trained language models such as BERT have brought significant improvements to NLP applications. However, they are also notorious for being slow in inference, which makes them difficult to deploy in real-time applications. We propose a simple but effective method, DeeBERT, to accelerate BERT inference. Our approach allows samples to exit earlier without passing through the entire model. Experiments show that DeeBERT is able to save up to ~40% inference time with minimal degradation in model quality. Further analyses show different behaviors in the BERT transformer layers and also reveal their redundancy. Our work provides new ideas to efficiently apply deep transformer-based models to downstream tasks. Code is available at https://github.com/castorini/DeeBERT.
What Would Elsa Do? Freezing Layers During Transformer Fine-Tuning
Nov 08, 2019
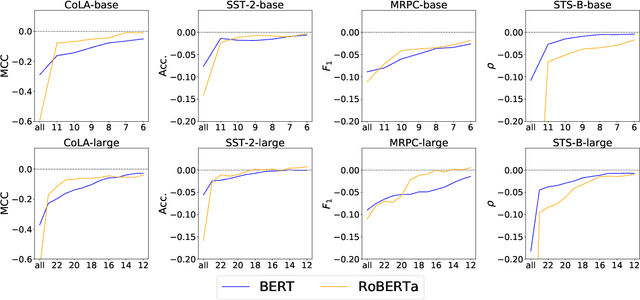
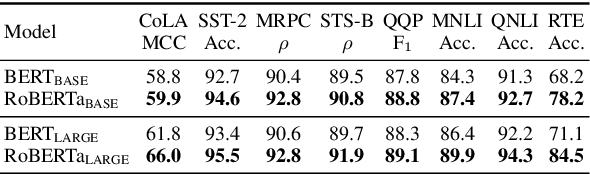

Pretrained transformer-based language models have achieved state of the art across countless tasks in natural language processing. These models are highly expressive, comprising at least a hundred million parameters and a dozen layers. Recent evidence suggests that only a few of the final layers need to be fine-tuned for high quality on downstream tasks. Naturally, a subsequent research question is, "how many of the last layers do we need to fine-tune?" In this paper, we precisely answer this question. We examine two recent pretrained language models, BERT and RoBERTa, across standard tasks in textual entailment, semantic similarity, sentiment analysis, and linguistic acceptability. We vary the number of final layers that are fine-tuned, then study the resulting change in task-specific effectiveness. We show that only a fourth of the final layers need to be fine-tuned to achieve 90% of the original quality. Surprisingly, we also find that fine-tuning all layers does not always help.
JavaScript Convolutional Neural Networks for Keyword Spotting in the Browser: An Experimental Analysis
Oct 30, 2018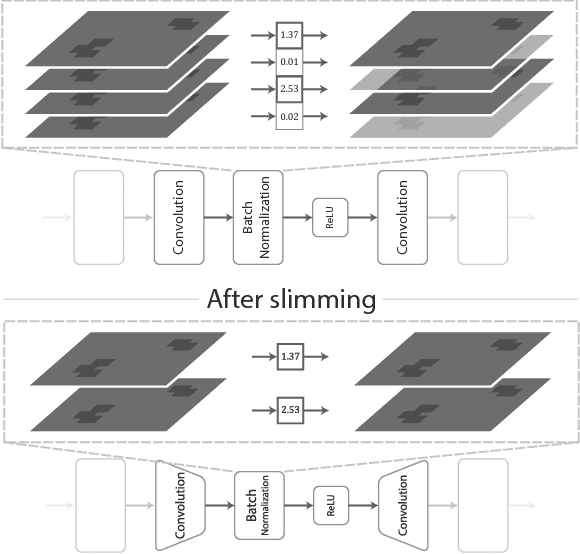
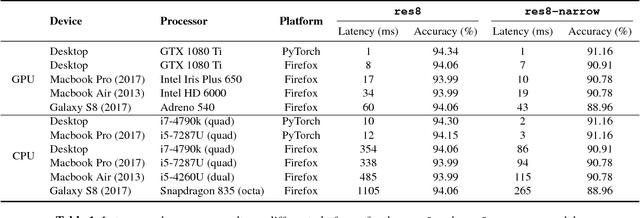
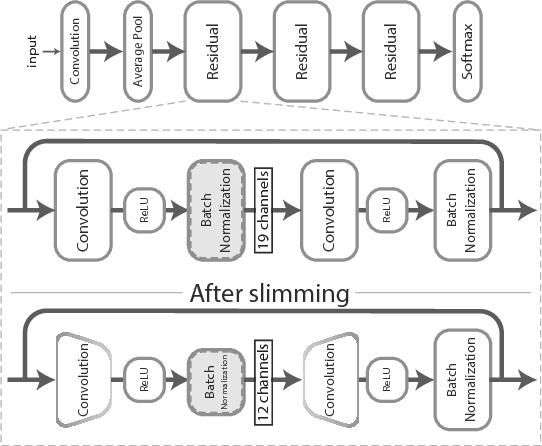
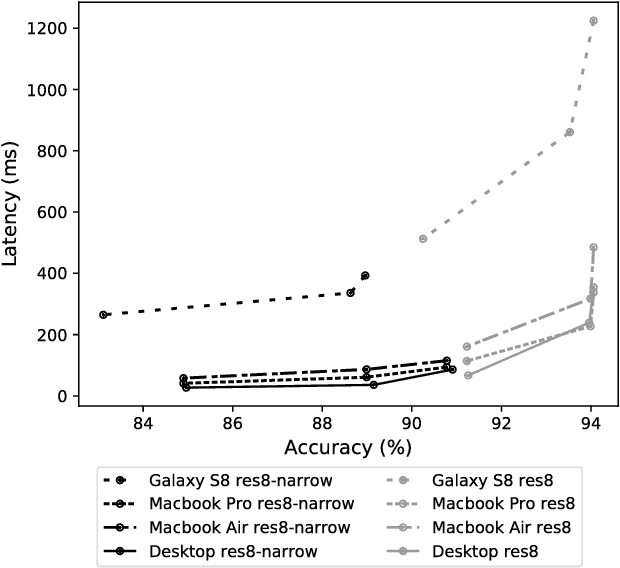
Used for simple commands recognition on devices from smart routers to mobile phones, keyword spotting systems are everywhere. Ubiquitous as well are web applications, which have grown in popularity and complexity over the last decade with significant improvements in usability under cross-platform conditions. However, despite their obvious advantage in natural language interaction, voice-enabled web applications are still far and few between. In this work, we attempt to bridge this gap by bringing keyword spotting capabilities directly into the browser. To our knowledge, we are the first to demonstrate a fully-functional implementation of convolutional neural networks in pure JavaScript that runs in any standards-compliant browser. We also apply network slimming, a model compression technique, to explore the accuracy-efficiency tradeoffs, reporting latency measurements on a range of devices and software. Overall, our robust, cross-device implementation for keyword spotting realizes a new paradigm for serving neural network applications, and one of our slim models reduces latency by 66% with a minimal decrease in accuracy of 4% from 94% to 90%.
Fuzzy and entropy facial recognition
Aug 24, 2014This paper suggests an effective method for facial recognition using fuzzy theory and Shannon entropy. Combination of fuzzy theory and Shannon entropy eliminates the complication of other methods. Shannon entropy calculates the ratio of an element between faces, and fuzzy theory calculates the member ship of the entropy with 1. More details will be mentioned in Section 3. The learning performance is better than others as it is very simple, and only need two data per learning. By using factors that don't usually change during the life, the method will have a high accuracy.