 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDG-PPU: Dynamical Graphs based Post-processing of Point Clouds extracted from Knee Ultrasounds
Nov 12, 2024Patients undergoing total knee arthroplasty (TKA) often experience non-specific anterior knee pain, arising from abnormal patellofemoral joint (PFJ) instability. Tracking PFJ motion is challenging since static imaging modalities like CT and MRI are limited by field of view and metal artefact interference. Ultrasounds offer an alternative modality for dynamic musculoskeletal imaging. We aim to achieve accurate visualisation of patellar tracking and PFJ motion, using 3D registration of point clouds extracted from ultrasound scans across different angles of joint flexion. Ultrasound images containing soft tissue are often mislabeled as bone during segmentation, resulting in noisy 3D point clouds that hinder accurate registration of the bony joint anatomy. Machine learning the intrinsic geometry of the knee bone may help us eliminate these false positives. As the intrinsic geometry of the knee does not change during PFJ motion, one may expect this to be robust across multiple angles of joint flexion. Our dynamical graphs-based post-processing algorithm (DG-PPU) is able to achieve this, creating smoother point clouds that accurately represent bony knee anatomy across different angles. After inverting these point clouds back to their original ultrasound images, we evaluated that DG-PPU outperformed manual data cleaning done by our lab technician, deleting false positives and noise with 98.2% precision across three different angles of joint flexion. DG-PPU is the first algorithm to automate the post-processing of 3D point clouds extracted from ultrasound scans. With DG-PPU, we contribute towards the development of a novel patellar mal-tracking assessment system with ultrasound, which currently does not exist.
Hear Your Face: Face-based voice conversion with F0 estimation
Aug 19, 2024



This paper delves into the emerging field of face-based voice conversion, leveraging the unique relationship between an individual's facial features and their vocal characteristics. We present a novel face-based voice conversion framework that particularly utilizes the average fundamental frequency of the target speaker, derived solely from their facial images. Through extensive analysis, our framework demonstrates superior speech generation quality and the ability to align facial features with voice characteristics, including tracking of the target speaker's fundamental frequency.
Removing Speaker Information from Speech Representation using Variable-Length Soft Pooling
Apr 01, 2024Recently, there have been efforts to encode the linguistic information of speech using a self-supervised framework for speech synthesis. However, predicting representations from surrounding representations can inadvertently entangle speaker information in the speech representation. This paper aims to remove speaker information by exploiting the structured nature of speech, composed of discrete units like phonemes with clear boundaries. A neural network predicts these boundaries, enabling variable-length pooling for event-based representation extraction instead of fixed-rate methods. The boundary predictor outputs a probability for the boundary between 0 and 1, making pooling soft. The model is trained to minimize the difference with the pooled representation of the data augmented by time-stretch and pitch-shift. To confirm that the learned representation includes contents information but is independent of speaker information, the model was evaluated with libri-light's phonetic ABX task and SUPERB's speaker identification task.
Learning Semantic Information from Raw Audio Signal Using Both Contextual and Phonetic Representations
Feb 02, 2024



We propose a framework to learn semantics from raw audio signals using two types of representations, encoding contextual and phonetic information respectively. Specifically, we introduce a speech-to-unit processing pipeline that captures two types of representations with different time resolutions. For the language model, we adopt a dual-channel architecture to incorporate both types of representation. We also present new training objectives, masked context reconstruction and masked context prediction, that push models to learn semantics effectively. Experiments on the sSIMI metric of Zero Resource Speech Benchmark 2021 and Fluent Speech Command dataset show our framework learns semantics better than models trained with only one type of representation.
Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing
Feb 01, 2023The ability to leverage shared behaviors between tasks is critical for sample-efficient multi-task reinforcement learning (MTRL). While prior methods have primarily explored parameter and data sharing, direct behavior-sharing has been limited to task families requiring similar behaviors. Our goal is to extend the efficacy of behavior-sharing to more general task families that could require a mix of shareable and conflicting behaviors. Our key insight is an agent's behavior across tasks can be used for mutually beneficial exploration. To this end, we propose a simple MTRL framework for identifying shareable behaviors over tasks and incorporating them to guide exploration. We empirically demonstrate how behavior sharing improves sample efficiency and final performance on manipulation and navigation MTRL tasks and is even complementary to parameter sharing. Result videos are available at https://sites.google.com/view/qmp-mtrl.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020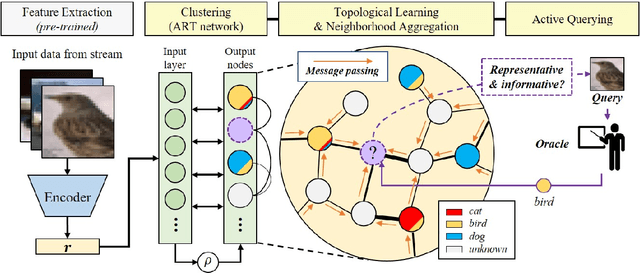
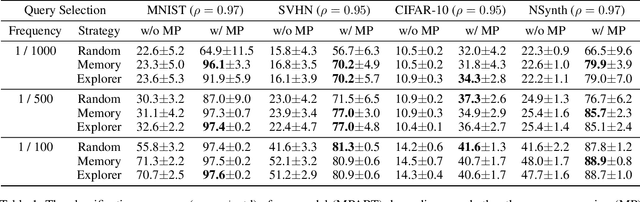

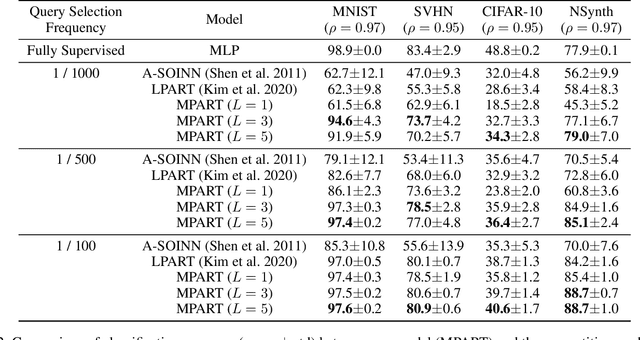
Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.
Label Propagation Adaptive Resonance Theory for Semi-supervised Continuous Learning
Apr 16, 2020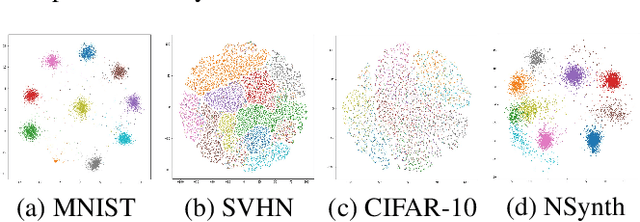
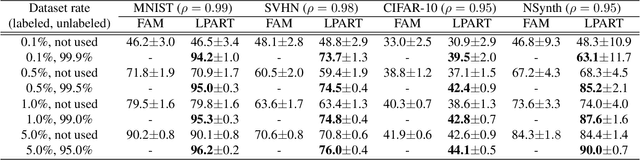
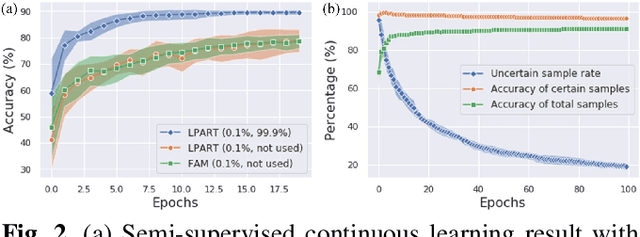
Semi-supervised learning and continuous learning are fundamental paradigms for human-level intelligence. To deal with real-world problems where labels are rarely given and the opportunity to access the same data is limited, it is necessary to apply these two paradigms in a joined fashion. In this paper, we propose Label Propagation Adaptive Resonance Theory (LPART) for semi-supervised continuous learning. LPART uses an online label propagation mechanism to perform classification and gradually improves its accuracy as the observed data accumulates. We evaluated the proposed model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets by adjusting the ratio of the labeled and unlabeled data. The accuracies are much higher when both labeled and unlabeled data are used, demonstrating the significant advantage of LPART in environments where the data labels are scarce.