 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
CushSense: Soft, Stretchable, and Comfortable Tactile-Sensing Skin for Physical Human-Robot Interaction
May 06, 2024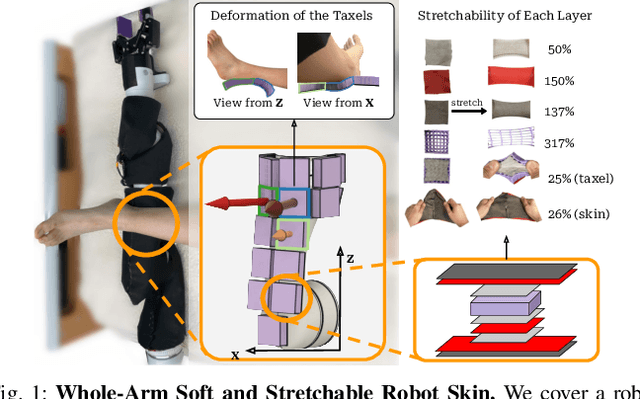
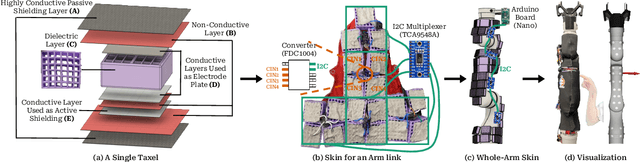
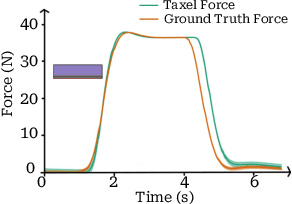
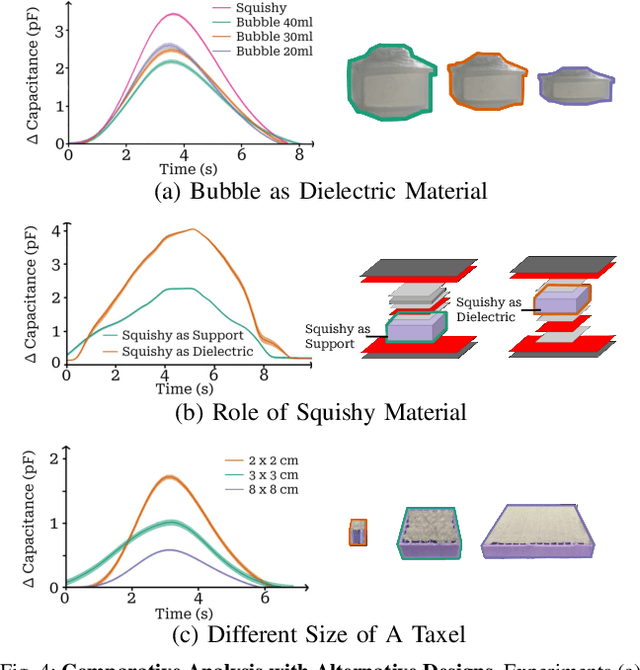
Whole-arm tactile feedback is crucial for robots to ensure safe physical interaction with their surroundings. This paper introduces CushSense, a fabric-based soft and stretchable tactile-sensing skin designed for physical human-robot interaction (pHRI) tasks such as robotic caregiving. Using stretchable fabric and hyper-elastic polymer, CushSense identifies contacts by monitoring capacitive changes due to skin deformation. CushSense is cost-effective ($\sim$US\$7 per taxel) and easy to fabricate. We detail the sensor design and fabrication process and perform characterization, highlighting its high sensing accuracy (relative error of 0.58%) and durability (0.054% accuracy drop after 1000 interactions). We also present a user study underscoring its perceived safety and comfort for the assistive task of limb manipulation. We open source all sensor-related resources on https://emprise.cs.cornell.edu/cushsense.
Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing
Feb 01, 2023The ability to leverage shared behaviors between tasks is critical for sample-efficient multi-task reinforcement learning (MTRL). While prior methods have primarily explored parameter and data sharing, direct behavior-sharing has been limited to task families requiring similar behaviors. Our goal is to extend the efficacy of behavior-sharing to more general task families that could require a mix of shareable and conflicting behaviors. Our key insight is an agent's behavior across tasks can be used for mutually beneficial exploration. To this end, we propose a simple MTRL framework for identifying shareable behaviors over tasks and incorporating them to guide exploration. We empirically demonstrate how behavior sharing improves sample efficiency and final performance on manipulation and navigation MTRL tasks and is even complementary to parameter sharing. Result videos are available at https://sites.google.com/view/qmp-mtrl.
CoMPS: Continual Meta Policy Search
Dec 08, 2021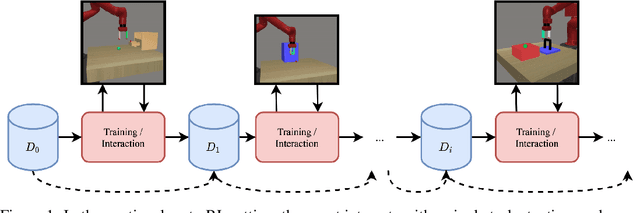
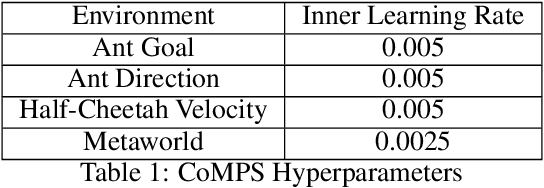

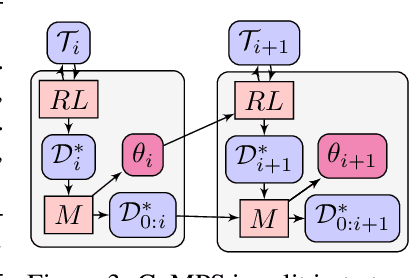
We develop a new continual meta-learning method to address challenges in sequential multi-task learning. In this setting, the agent's goal is to achieve high reward over any sequence of tasks quickly. Prior meta-reinforcement learning algorithms have demonstrated promising results in accelerating the acquisition of new tasks. However, they require access to all tasks during training. Beyond simply transferring past experience to new tasks, our goal is to devise continual reinforcement learning algorithms that learn to learn, using their experience on previous tasks to learn new tasks more quickly. We introduce a new method, continual meta-policy search (CoMPS), that removes this limitation by meta-training in an incremental fashion, over each task in a sequence, without revisiting prior tasks. CoMPS continuously repeats two subroutines: learning a new task using RL and using the experience from RL to perform completely offline meta-learning to prepare for subsequent task learning. We find that CoMPS outperforms prior continual learning and off-policy meta-reinforcement methods on several sequences of challenging continuous control tasks.
Policy Transfer across Visual and Dynamics Domain Gaps via Iterative Grounding
Jul 01, 2021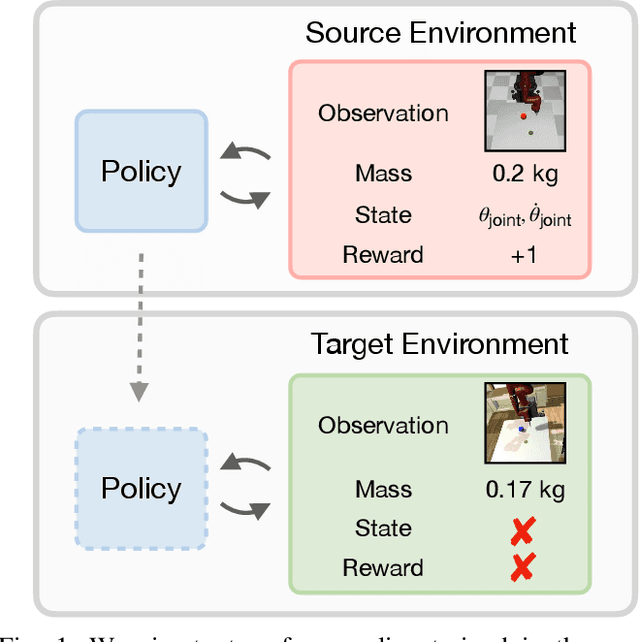
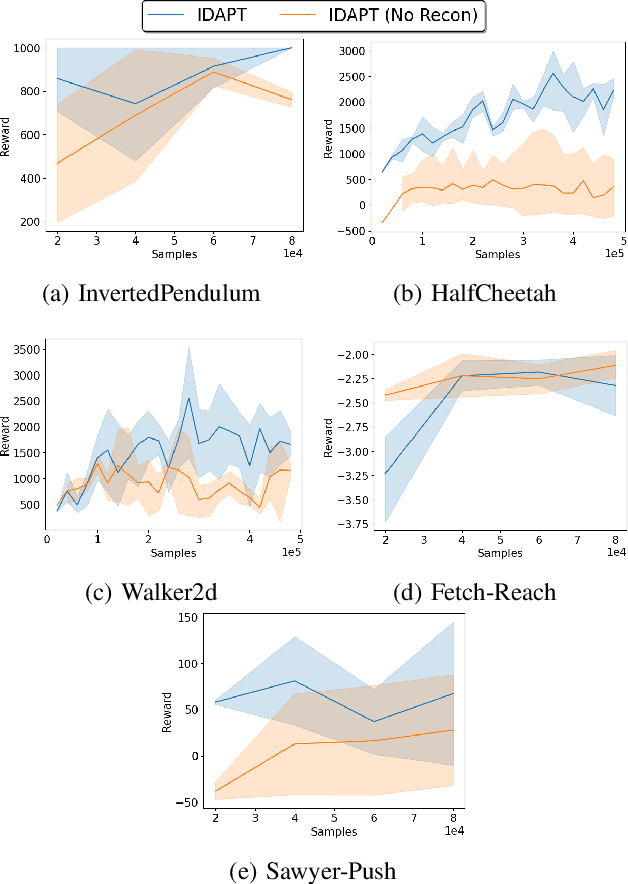
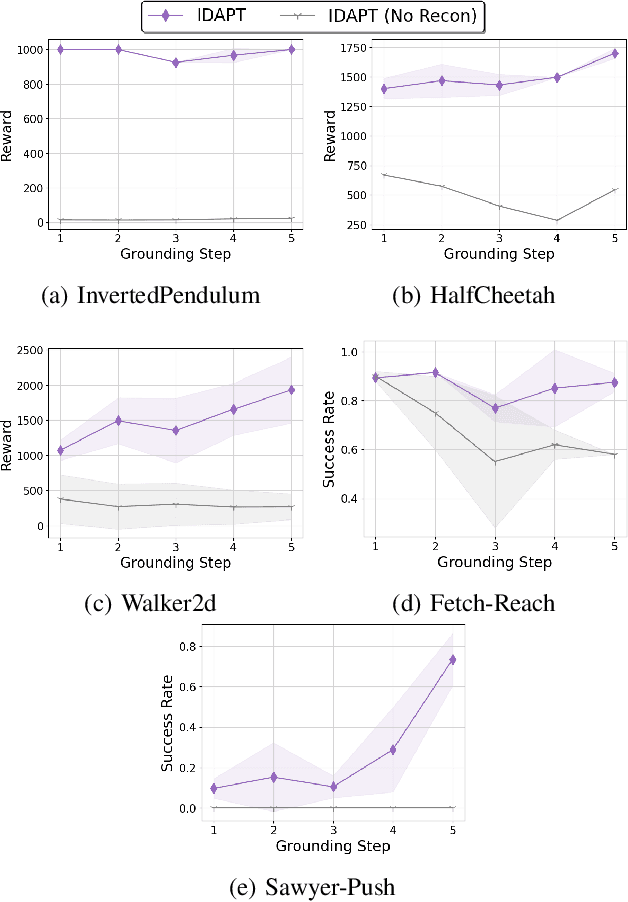
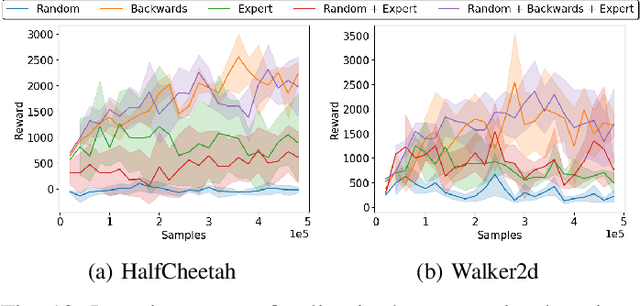
The ability to transfer a policy from one environment to another is a promising avenue for efficient robot learning in realistic settings where task supervision is not available. This can allow us to take advantage of environments well suited for training, such as simulators or laboratories, to learn a policy for a real robot in a home or office. To succeed, such policy transfer must overcome both the visual domain gap (e.g. different illumination or background) and the dynamics domain gap (e.g. different robot calibration or modelling error) between source and target environments. However, prior policy transfer approaches either cannot handle a large domain gap or can only address one type of domain gap at a time. In this paper, we propose a novel policy transfer method with iterative "environment grounding", IDAPT, that alternates between (1) directly minimizing both visual and dynamics domain gaps by grounding the source environment in the target environment domains, and (2) training a policy on the grounded source environment. This iterative training progressively aligns the domains between the two environments and adapts the policy to the target environment. Once trained, the policy can be directly executed on the target environment. The empirical results on locomotion and robotic manipulation tasks demonstrate that our approach can effectively transfer a policy across visual and dynamics domain gaps with minimal supervision and interaction with the target environment. Videos and code are available at https://clvrai.com/idapt .
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Oct 07, 2019


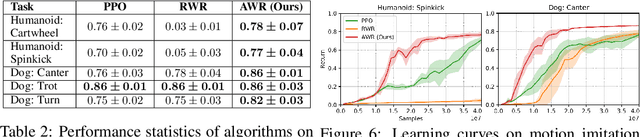
In this paper, we aim to develop a simple and scalable reinforcement learning algorithm that uses standard supervised learning methods as subroutines. Our goal is an algorithm that utilizes only simple and convergent maximum likelihood loss functions, while also being able to leverage off-policy data. Our proposed approach, which we refer to as advantage-weighted regression (AWR), consists of two standard supervised learning steps: one to regress onto target values for a value function, and another to regress onto weighted target actions for the policy. The method is simple and general, can accommodate continuous and discrete actions, and can be implemented in just a few lines of code on top of standard supervised learning methods. We provide a theoretical motivation for AWR and analyze its properties when incorporating off-policy data from experience replay. We evaluate AWR on a suite of standard OpenAI Gym benchmark tasks, and show that it achieves competitive performance compared to a number of well-established state-of-the-art RL algorithms. AWR is also able to acquire more effective policies than most off-policy algorithms when learning from purely static datasets with no additional environmental interactions. Furthermore, we demonstrate our algorithm on challenging continuous control tasks with highly complex simulated characters.
MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies
May 23, 2019

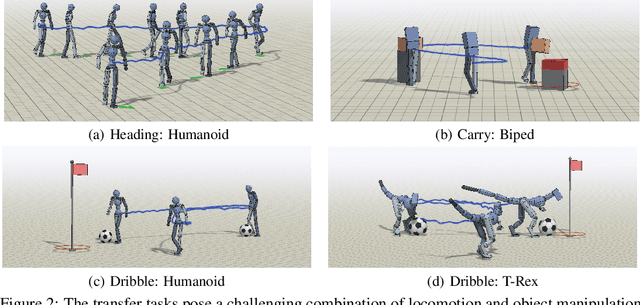
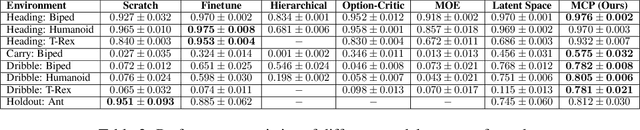
Humans are able to perform a myriad of sophisticated tasks by drawing upon skills acquired through prior experience. For autonomous agents to have this capability, they must be able to extract reusable skills from past experience that can be recombined in new ways for subsequent tasks. Furthermore, when controlling complex high-dimensional morphologies, such as humanoid bodies, tasks often require coordination of multiple skills simultaneously. Learning discrete primitives for every combination of skills quickly becomes prohibitive. Composable primitives that can be recombined to create a large variety of behaviors can be more suitable for modeling this combinatorial explosion. In this work, we propose multiplicative compositional policies (MCP), a method for learning reusable motor skills that can be composed to produce a range of complex behaviors. Our method factorizes an agent's skills into a collection of primitives, where multiple primitives can be activated simultaneously via multiplicative composition. This flexibility allows the primitives to be transferred and recombined to elicit new behaviors as necessary for novel tasks. We demonstrate that MCP is able to extract composable skills for highly complex simulated characters from pre-training tasks, such as motion imitation, and then reuse these skills to solve challenging continuous control tasks, such as dribbling a soccer ball to a goal, and picking up an object and transporting it to a target location.