 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComPose: When to Trust Hands for Object Pose Tracking
May 22, 2026Reconstructing the motion of objects from videos is a key component for embodied AI and robot manipulation. While diverse approaches to object pose tracking have been studied, they rely heavily on strong external priors, such as depth data or 3D templates, and remain highly vulnerable to severe occlusions by hand grasps despite the use of explicit masks. In this work, we present ComPose, a 6DoF object tracking framework designed for hand-aware object pose estimation from RGB video. Rather than treating the hand purely as an occluder, our method harmonizes hand motions as a \textit{complementary cue} for object tracking. In detail, we recover a variety of object motions over time by combining object and hand cues from foundation models within a unified tracking pipeline. Here, ComPose adaptively selects informative hand joints, combines object- and hand-derived cues for motion estimation, and refines the resulting object motion using visible geometric evidence and a learned correction. We further enforce the temporal consistency over both rotation and translation, yielding stable 3D object trajectories over time without any external smoothing. Extensive experiments show that our method is accurate, efficient, and robust under severe hand occlusion and geometric ambiguity. In addition, the resulting trajectories can also effectively transfer to downstream robot manipulation by enabling robots to reconstruct human actions from online videos.
Chunk-Guided Q-Learning
Mar 14, 2026In offline reinforcement learning (RL), single-step temporal-difference (TD) learning can suffer from bootstrapping error accumulation over long horizons. Action-chunked TD methods mitigate this by backing up over multiple steps, but can introduce suboptimality by restricting the policy class to open-loop action sequences. To resolve this trade-off, we present Chunk-Guided Q-Learning (CGQ), a single-step TD algorithm that guides a fine-grained single-step critic by regularizing it toward a chunk-based critic trained using temporally extended backups. This reduces compounding error while preserving fine-grained value propagation. We theoretically show that CGQ attains tighter critic optimality bounds than either single-step or action-chunked TD learning alone. Empirically, CGQ achieves strong performance on challenging long-horizon OGBench tasks, often outperforming both single-step and action-chunked methods.
Latent Policy Steering through One-Step Flow Policies
Mar 05, 2026Offline reinforcement learning (RL) allows robots to learn from offline datasets without risky exploration. Yet, offline RL's performance often hinges on a brittle trade-off between (1) return maximization, which can push policies outside the dataset support, and (2) behavioral constraints, which typically require sensitive hyperparameter tuning. Latent steering offers a structural way to stay within the dataset support during RL, but existing offline adaptations commonly approximate action values using latent-space critics learned via indirect distillation, which can lose information and hinder convergence. We propose Latent Policy Steering (LPS), which enables high-fidelity latent policy improvement by backpropagating original-action-space Q-gradients through a differentiable one-step MeanFlow policy to update a latent-action-space actor. By eliminating proxy latent critics, LPS allows an original-action-space critic to guide end-to-end latent-space optimization, while the one-step MeanFlow policy serves as a behavior-constrained generative prior. This decoupling yields a robust method that works out-of-the-box with minimal tuning. Across OGBench and real-world robotic tasks, LPS achieves state-of-the-art performance and consistently outperforms behavioral cloning and strong latent steering baselines.
Scalable Offline Model-Based RL with Action Chunks
Dec 08, 2025In this paper, we study whether model-based reinforcement learning (RL), in particular model-based value expansion, can provide a scalable recipe for tackling complex, long-horizon tasks in offline RL. Model-based value expansion fits an on-policy value function using length-n imaginary rollouts generated by the current policy and a learned dynamics model. While larger n reduces bias in value bootstrapping, it amplifies accumulated model errors over long horizons, degrading future predictions. We address this trade-off with an \emph{action-chunk} model that predicts a future state from a sequence of actions (an "action chunk") instead of a single action, which reduces compounding errors. In addition, instead of directly training a policy to maximize rewards, we employ rejection sampling from an expressive behavioral action-chunk policy, which prevents model exploitation from out-of-distribution actions. We call this recipe \textbf{Model-Based RL with Action Chunks (MAC)}. Through experiments on highly challenging tasks with large-scale datasets of up to 100M transitions, we show that MAC achieves the best performance among offline model-based RL algorithms, especially on challenging long-horizon tasks.
TwinVLA: Data-Efficient Bimanual Manipulation with Twin Single-Arm Vision-Language-Action Models
Nov 07, 2025Vision-language-action models (VLAs) trained on large-scale robotic datasets have demonstrated strong performance on manipulation tasks, including bimanual tasks. However, because most public datasets focus on single-arm demonstrations, adapting VLAs for bimanual tasks typically requires substantial additional bimanual data and fine-tuning. To address this challenge, we introduce TwinVLA, a modular framework that composes two copies of a pretrained single-arm VLA into a coordinated bimanual VLA. Unlike monolithic cross-embodiment models trained on mixtures of single-arm and bimanual data, TwinVLA improves both data efficiency and performance by composing pretrained single-arm policies. Across diverse bimanual tasks in real-world and simulation settings, TwinVLA outperforms a comparably-sized monolithic RDT-1B model without requiring any bimanual pretraining. Furthermore, it narrows the gap to state-of-the-art model, $π_0$ which rely on extensive proprietary bimanual data and compute cost. These results establish our modular composition approach as a data-efficient and scalable path toward high-performance bimanual manipulation, leveraging public single-arm data.
UniSkill: Imitating Human Videos via Cross-Embodiment Skill Representations
May 15, 2025Mimicry is a fundamental learning mechanism in humans, enabling individuals to learn new tasks by observing and imitating experts. However, applying this ability to robots presents significant challenges due to the inherent differences between human and robot embodiments in both their visual appearance and physical capabilities. While previous methods bridge this gap using cross-embodiment datasets with shared scenes and tasks, collecting such aligned data between humans and robots at scale is not trivial. In this paper, we propose UniSkill, a novel framework that learns embodiment-agnostic skill representations from large-scale cross-embodiment video data without any labels, enabling skills extracted from human video prompts to effectively transfer to robot policies trained only on robot data. Our experiments in both simulation and real-world environments show that our cross-embodiment skills successfully guide robots in selecting appropriate actions, even with unseen video prompts. The project website can be found at: https://kimhanjung.github.io/UniSkill.
TLDR: Unsupervised Goal-Conditioned RL via Temporal Distance-Aware Representations
Jul 11, 2024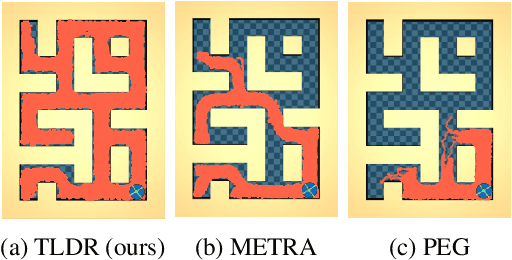
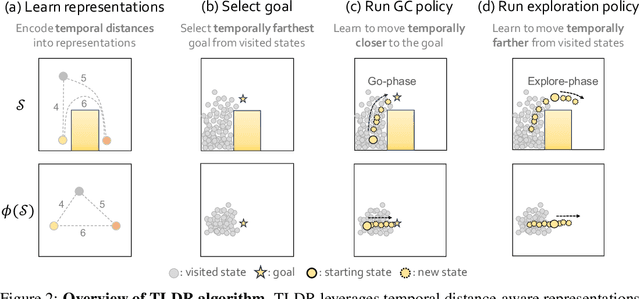

Unsupervised goal-conditioned reinforcement learning (GCRL) is a promising paradigm for developing diverse robotic skills without external supervision. However, existing unsupervised GCRL methods often struggle to cover a wide range of states in complex environments due to their limited exploration and sparse or noisy rewards for GCRL. To overcome these challenges, we propose a novel unsupervised GCRL method that leverages TemporaL Distance-aware Representations (TLDR). TLDR selects faraway goals to initiate exploration and computes intrinsic exploration rewards and goal-reaching rewards, based on temporal distance. Specifically, our exploration policy seeks states with large temporal distances (i.e. covering a large state space), while the goal-conditioned policy learns to minimize the temporal distance to the goal (i.e. reaching the goal). Our experimental results in six simulated robotic locomotion environments demonstrate that our method significantly outperforms previous unsupervised GCRL methods in achieving a wide variety of states.
Tackling Long-Horizon Tasks with Model-based Offline Reinforcement Learning
Jun 30, 2024Model-based offline reinforcement learning (RL) is a compelling approach that addresses the challenge of learning from limited, static data by generating imaginary trajectories using learned models. However, it falls short in solving long-horizon tasks due to high bias in value estimation from model rollouts. In this paper, we introduce a novel model-based offline RL method, Lower Expectile Q-learning (LEQ), which enhances long-horizon task performance by mitigating the high bias in model-based value estimation via expectile regression of $\lambda$-returns. Our empirical results show that LEQ significantly outperforms previous model-based offline RL methods on long-horizon tasks, such as the D4RL AntMaze tasks, matching or surpassing the performance of model-free approaches. Our experiments demonstrate that expectile regression, $\lambda$-returns, and critic training on offline data are all crucial for addressing long-horizon tasks. Additionally, LEQ achieves performance comparable to the state-of-the-art model-based and model-free offline RL methods on the NeoRL benchmark and the D4RL MuJoCo Gym tasks.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Mar 15, 2024

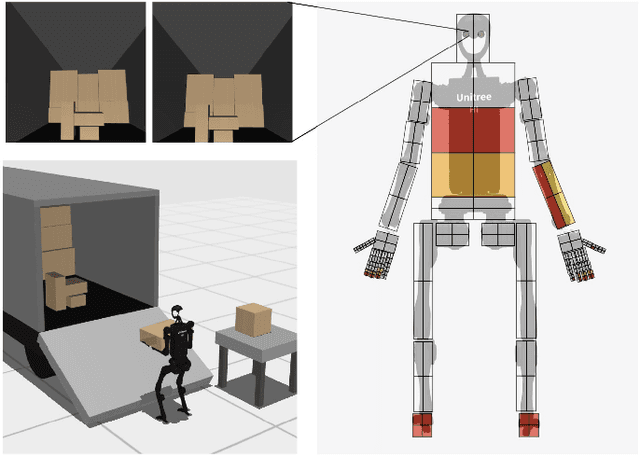

Humanoid robots hold great promise in assisting humans in diverse environments and tasks, due to their flexibility and adaptability leveraging human-like morphology. However, research in humanoid robots is often bottlenecked by the costly and fragile hardware setups. To accelerate algorithmic research in humanoid robots, we present a high-dimensional, simulated robot learning benchmark, HumanoidBench, featuring a humanoid robot equipped with dexterous hands and a variety of challenging whole-body manipulation and locomotion tasks. Our findings reveal that state-of-the-art reinforcement learning algorithms struggle with most tasks, whereas a hierarchical learning baseline achieves superior performance when supported by robust low-level policies, such as walking or reaching. With HumanoidBench, we provide the robotics community with a platform to identify the challenges arising when solving diverse tasks with humanoid robots, facilitating prompt verification of algorithms and ideas. The open-source code is available at https://sferrazza.cc/humanoidbench_site.