 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk-Guided Q-Learning
Mar 14, 2026In offline reinforcement learning (RL), single-step temporal-difference (TD) learning can suffer from bootstrapping error accumulation over long horizons. Action-chunked TD methods mitigate this by backing up over multiple steps, but can introduce suboptimality by restricting the policy class to open-loop action sequences. To resolve this trade-off, we present Chunk-Guided Q-Learning (CGQ), a single-step TD algorithm that guides a fine-grained single-step critic by regularizing it toward a chunk-based critic trained using temporally extended backups. This reduces compounding error while preserving fine-grained value propagation. We theoretically show that CGQ attains tighter critic optimality bounds than either single-step or action-chunked TD learning alone. Empirically, CGQ achieves strong performance on challenging long-horizon OGBench tasks, often outperforming both single-step and action-chunked methods.
Scalable Offline Model-Based RL with Action Chunks
Dec 08, 2025In this paper, we study whether model-based reinforcement learning (RL), in particular model-based value expansion, can provide a scalable recipe for tackling complex, long-horizon tasks in offline RL. Model-based value expansion fits an on-policy value function using length-n imaginary rollouts generated by the current policy and a learned dynamics model. While larger n reduces bias in value bootstrapping, it amplifies accumulated model errors over long horizons, degrading future predictions. We address this trade-off with an \emph{action-chunk} model that predicts a future state from a sequence of actions (an "action chunk") instead of a single action, which reduces compounding errors. In addition, instead of directly training a policy to maximize rewards, we employ rejection sampling from an expressive behavioral action-chunk policy, which prevents model exploitation from out-of-distribution actions. We call this recipe \textbf{Model-Based RL with Action Chunks (MAC)}. Through experiments on highly challenging tasks with large-scale datasets of up to 100M transitions, we show that MAC achieves the best performance among offline model-based RL algorithms, especially on challenging long-horizon tasks.
TLDR: Unsupervised Goal-Conditioned RL via Temporal Distance-Aware Representations
Jul 11, 2024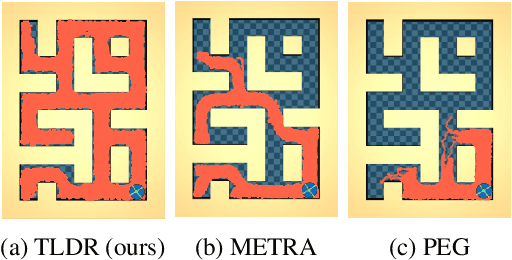
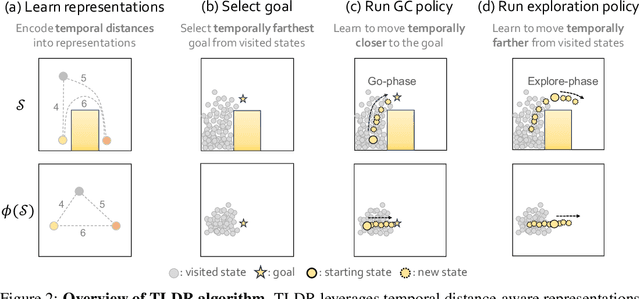

Unsupervised goal-conditioned reinforcement learning (GCRL) is a promising paradigm for developing diverse robotic skills without external supervision. However, existing unsupervised GCRL methods often struggle to cover a wide range of states in complex environments due to their limited exploration and sparse or noisy rewards for GCRL. To overcome these challenges, we propose a novel unsupervised GCRL method that leverages TemporaL Distance-aware Representations (TLDR). TLDR selects faraway goals to initiate exploration and computes intrinsic exploration rewards and goal-reaching rewards, based on temporal distance. Specifically, our exploration policy seeks states with large temporal distances (i.e. covering a large state space), while the goal-conditioned policy learns to minimize the temporal distance to the goal (i.e. reaching the goal). Our experimental results in six simulated robotic locomotion environments demonstrate that our method significantly outperforms previous unsupervised GCRL methods in achieving a wide variety of states.
Tackling Long-Horizon Tasks with Model-based Offline Reinforcement Learning
Jun 30, 2024Model-based offline reinforcement learning (RL) is a compelling approach that addresses the challenge of learning from limited, static data by generating imaginary trajectories using learned models. However, it falls short in solving long-horizon tasks due to high bias in value estimation from model rollouts. In this paper, we introduce a novel model-based offline RL method, Lower Expectile Q-learning (LEQ), which enhances long-horizon task performance by mitigating the high bias in model-based value estimation via expectile regression of $\lambda$-returns. Our empirical results show that LEQ significantly outperforms previous model-based offline RL methods on long-horizon tasks, such as the D4RL AntMaze tasks, matching or surpassing the performance of model-free approaches. Our experiments demonstrate that expectile regression, $\lambda$-returns, and critic training on offline data are all crucial for addressing long-horizon tasks. Additionally, LEQ achieves performance comparable to the state-of-the-art model-based and model-free offline RL methods on the NeoRL benchmark and the D4RL MuJoCo Gym tasks.
Toddler-Guidance Learning: Impacts of Critical Period on Multimodal AI Agents
Jan 12, 2022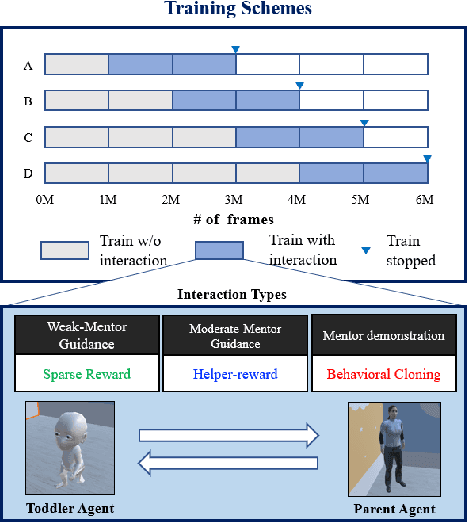

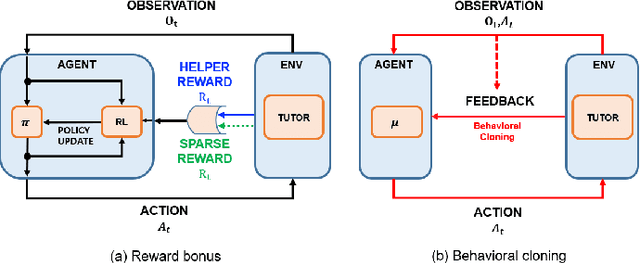
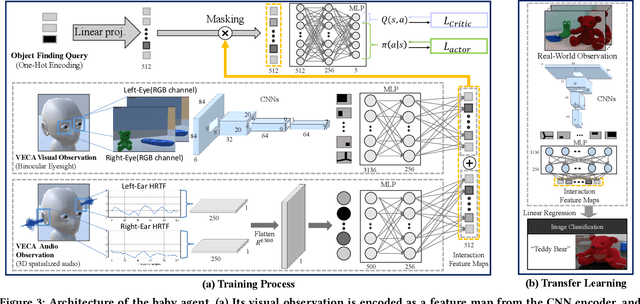
Critical periods are phases during which a toddler's brain develops in spurts. To promote children's cognitive development, proper guidance is critical in this stage. However, it is not clear whether such a critical period also exists for the training of AI agents. Similar to human toddlers, well-timed guidance and multimodal interactions might significantly enhance the training efficiency of AI agents as well. To validate this hypothesis, we adapt this notion of critical periods to learning in AI agents and investigate the critical period in the virtual environment for AI agents. We formalize the critical period and Toddler-guidance learning in the reinforcement learning (RL) framework. Then, we built up a toddler-like environment with VECA toolkit to mimic human toddlers' learning characteristics. We study three discrete levels of mutual interaction: weak-mentor guidance (sparse reward), moderate mentor guidance (helper-reward), and mentor demonstration (behavioral cloning). We also introduce the EAVE dataset consisting of 30,000 real-world images to fully reflect the toddler's viewpoint. We evaluate the impact of critical periods on AI agents from two perspectives: how and when they are guided best in both uni- and multimodal learning. Our experimental results show that both uni- and multimodal agents with moderate mentor guidance and critical period on 1 million and 2 million training steps show a noticeable improvement. We validate these results with transfer learning on the EAVE dataset and find the performance advancement on the same critical period and the guidance.
VECA : A Toolkit for Building Virtual Environments to Train and Test Human-like Agents
May 03, 2021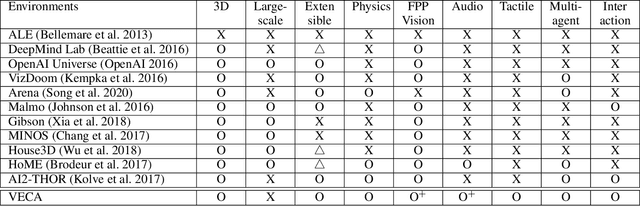
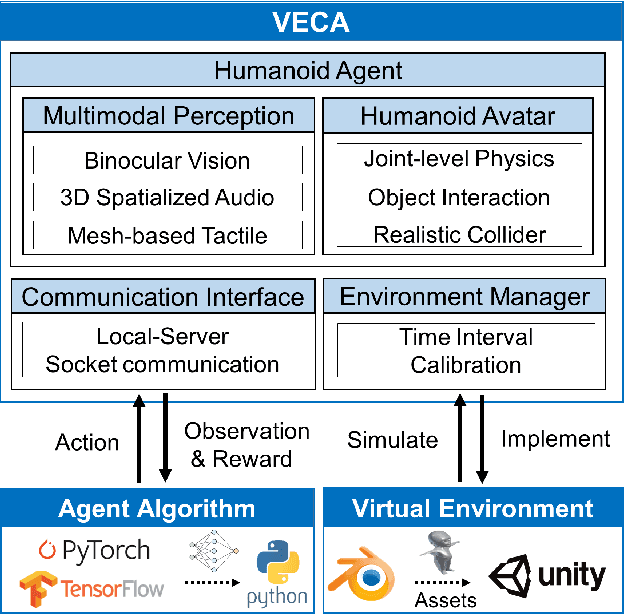


Building human-like agent, which aims to learn and think like human intelligence, has long been an important research topic in AI. To train and test human-like agents, we need an environment that imposes the agent to rich multimodal perception and allows comprehensive interactions for the agent, while also easily extensible to develop custom tasks. However, existing approaches do not support comprehensive interaction with the environment or lack variety in modalities. Also, most of the approaches are difficult or even impossible to implement custom tasks. In this paper, we propose a novel VR-based toolkit, VECA, which enables building fruitful virtual environments to train and test human-like agents. In particular, VECA provides a humanoid agent and an environment manager, enabling the agent to receive rich human-like perception and perform comprehensive interactions. To motivate VECA, we also provide 24 interactive tasks, which represent (but are not limited to) four essential aspects in early human development: joint-level locomotion and control, understanding contexts of objects, multimodal learning, and multi-agent learning. To show the usefulness of VECA on training and testing human-like learning agents, we conduct experiments on VECA and show that users can build challenging tasks for engaging human-like algorithms, and the features supported by VECA are critical on training human-like agents.
Learning task-agnostic representation via toddler-inspired learning
Jan 27, 2021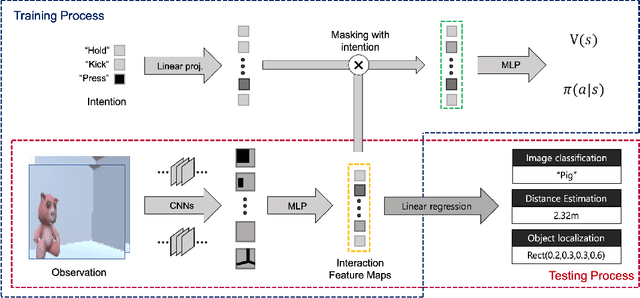


One of the inherent limitations of current AI systems, stemming from the passive learning mechanisms (e.g., supervised learning), is that they perform well on labeled datasets but cannot deduce knowledge on their own. To tackle this problem, we derive inspiration from a highly intentional learning system via action: the toddler. Inspired by the toddler's learning procedure, we design an interactive agent that can learn and store task-agnostic visual representation while exploring and interacting with objects in the virtual environment. Experimental results show that such obtained representation was expandable to various vision tasks such as image classification, object localization, and distance estimation tasks. In specific, the proposed model achieved 100%, 75.1% accuracy and 1.62% relative error, respectively, which is noticeably better than autoencoder-based model (99.7%, 66.1%, 1.95%), and also comparable with those of supervised models (100%, 87.3%, 0.71%).