 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collage Transfer: Artistic Reconstruction via Material Manipulation
Nov 03, 2023



Collage is a creative art form that uses diverse material scraps as a base unit to compose a single image. Although pixel-wise generation techniques can reproduce a target image in collage style, it is not a suitable method due to the solid stroke-by-stroke nature of the collage form. While some previous works for stroke-based rendering produced decent sketches and paintings, collages have received much less attention in research despite their popularity as a style. In this paper, we propose a method for learning to make collages via reinforcement learning without the need for demonstrations or collage artwork data. We design the collage Markov Decision Process (MDP), which allows the agent to handle various materials and propose a model-based soft actor-critic to mitigate the agent's training burden derived from the sophisticated dynamics of collage. Moreover, we devise additional techniques such as active material selection and complexity-based multi-scale collage to handle target images at any size and enhance the results' aesthetics by placing relatively more scraps in areas of high complexity. Experimental results show that the trained agent appropriately selected and pasted materials to regenerate the target image into a collage and obtained a higher evaluation score on content and style than pixel-wise generation methods. Code is available at https://github.com/northadventure/CollageRL.
From Scratch to Sketch: Deep Decoupled Hierarchical Reinforcement Learning for Robotic Sketching Agent
Aug 09, 2022
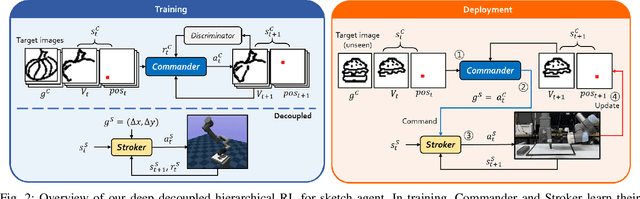
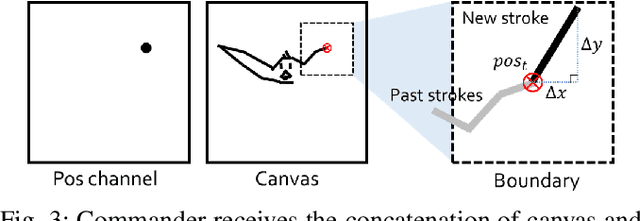
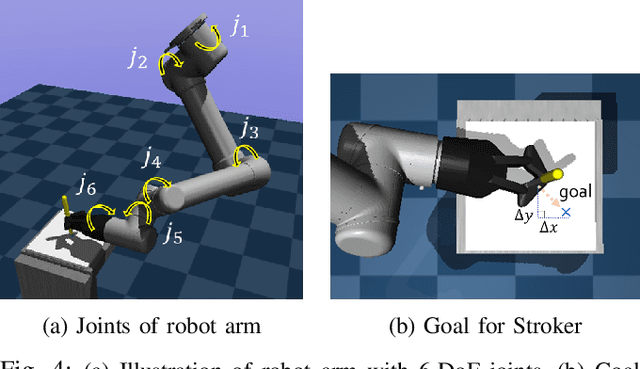
We present an automated learning framework for a robotic sketching agent that is capable of learning stroke-based rendering and motor control simultaneously. We formulate the robotic sketching problem as a deep decoupled hierarchical reinforcement learning; two policies for stroke-based rendering and motor control are learned independently to achieve sub-tasks for drawing, and form a hierarchy when cooperating for real-world drawing. Without hand-crafted features, drawing sequences or trajectories, and inverse kinematics, the proposed method trains the robotic sketching agent from scratch. We performed experiments with a 6-DoF robot arm with 2F gripper to sketch doodles. Our experimental results show that the two policies successfully learned the sub-tasks and collaborated to sketch the target images. Also, the robustness and flexibility were examined by varying drawing tools and surfaces.
Toddler-Guidance Learning: Impacts of Critical Period on Multimodal AI Agents
Jan 12, 2022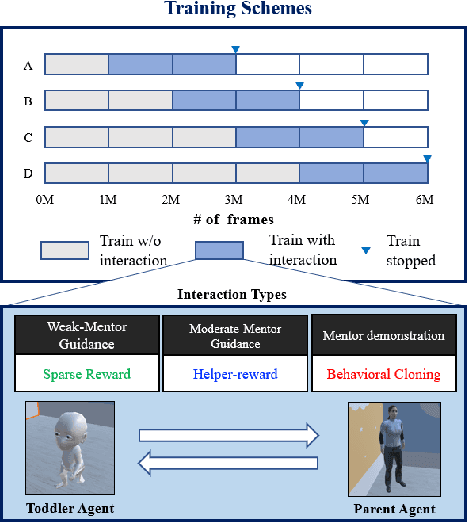

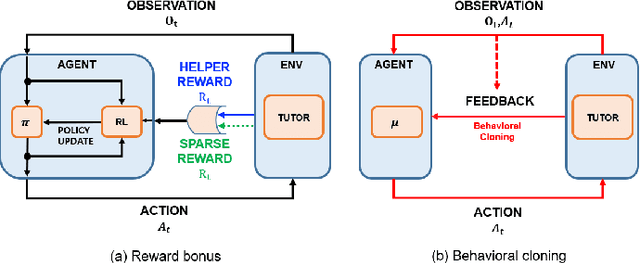
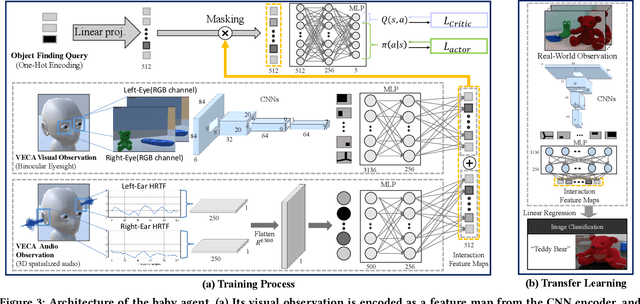
Critical periods are phases during which a toddler's brain develops in spurts. To promote children's cognitive development, proper guidance is critical in this stage. However, it is not clear whether such a critical period also exists for the training of AI agents. Similar to human toddlers, well-timed guidance and multimodal interactions might significantly enhance the training efficiency of AI agents as well. To validate this hypothesis, we adapt this notion of critical periods to learning in AI agents and investigate the critical period in the virtual environment for AI agents. We formalize the critical period and Toddler-guidance learning in the reinforcement learning (RL) framework. Then, we built up a toddler-like environment with VECA toolkit to mimic human toddlers' learning characteristics. We study three discrete levels of mutual interaction: weak-mentor guidance (sparse reward), moderate mentor guidance (helper-reward), and mentor demonstration (behavioral cloning). We also introduce the EAVE dataset consisting of 30,000 real-world images to fully reflect the toddler's viewpoint. We evaluate the impact of critical periods on AI agents from two perspectives: how and when they are guided best in both uni- and multimodal learning. Our experimental results show that both uni- and multimodal agents with moderate mentor guidance and critical period on 1 million and 2 million training steps show a noticeable improvement. We validate these results with transfer learning on the EAVE dataset and find the performance advancement on the same critical period and the guidance.