 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse to Dense: Toddler-inspired Reward Transition in Goal-Oriented Reinforcement Learning
Jan 29, 2025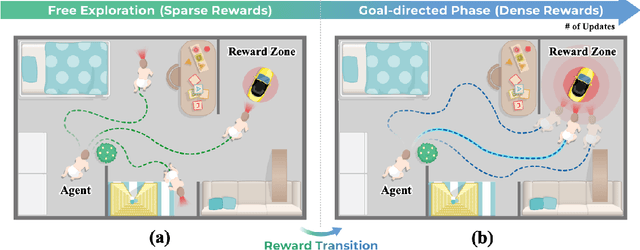
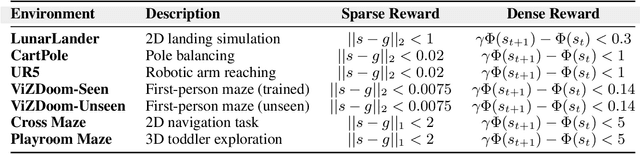
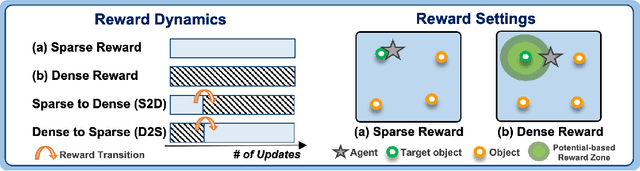
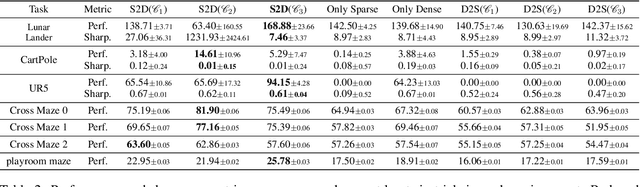
Reinforcement learning (RL) agents often face challenges in balancing exploration and exploitation, particularly in environments where sparse or dense rewards bias learning. Biological systems, such as human toddlers, naturally navigate this balance by transitioning from free exploration with sparse rewards to goal-directed behavior guided by increasingly dense rewards. Inspired by this natural progression, we investigate the Toddler-Inspired Reward Transition in goal-oriented RL tasks. Our study focuses on transitioning from sparse to potential-based dense (S2D) rewards while preserving optimal strategies. Through experiments on dynamic robotic arm manipulation and egocentric 3D navigation tasks, we demonstrate that effective S2D reward transitions significantly enhance learning performance and sample efficiency. Additionally, using a Cross-Density Visualizer, we show that S2D transitions smooth the policy loss landscape, resulting in wider minima that improve generalization in RL models. In addition, we reinterpret Tolman's maze experiments, underscoring the critical role of early free exploratory learning in the context of S2D rewards.
Unveiling the Significance of Toddler-Inspired Reward Transition in Goal-Oriented Reinforcement Learning
Mar 18, 2024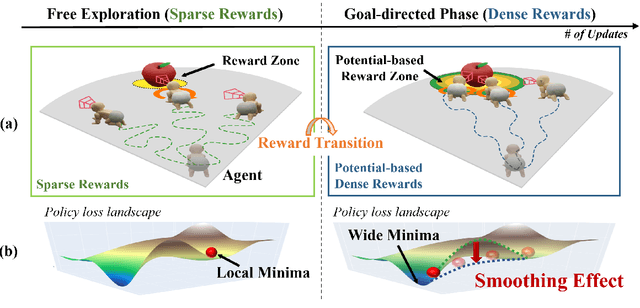

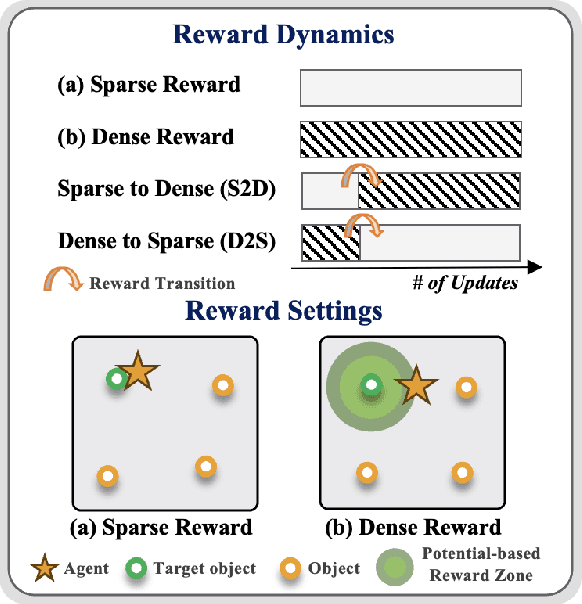
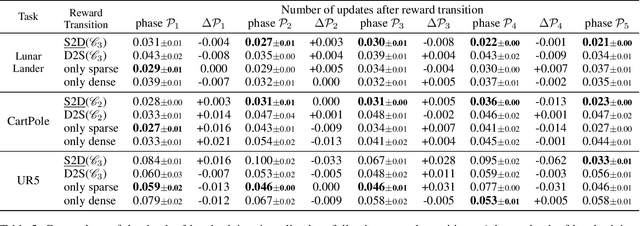
Toddlers evolve from free exploration with sparse feedback to exploiting prior experiences for goal-directed learning with denser rewards. Drawing inspiration from this Toddler-Inspired Reward Transition, we set out to explore the implications of varying reward transitions when incorporated into Reinforcement Learning (RL) tasks. Central to our inquiry is the transition from sparse to potential-based dense rewards, which share optimal strategies regardless of reward changes. Through various experiments, including those in egocentric navigation and robotic arm manipulation tasks, we found that proper reward transitions significantly influence sample efficiency and success rates. Of particular note is the efficacy of the toddler-inspired Sparse-to-Dense (S2D) transition. Beyond these performance metrics, using Cross-Density Visualizer technique, we observed that transitions, especially the S2D, smooth the policy loss landscape, promoting wide minima that enhance generalization in RL models.
DUEL: Duplicate Elimination on Active Memory for Self-Supervised Class-Imbalanced Learning
Feb 14, 2024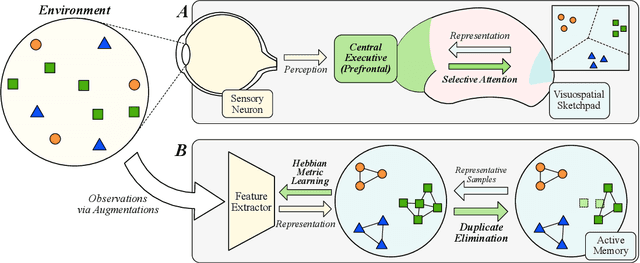
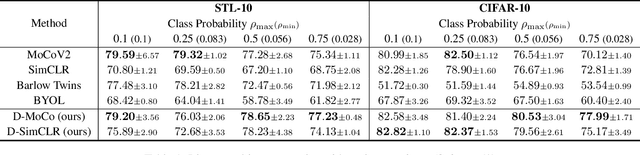
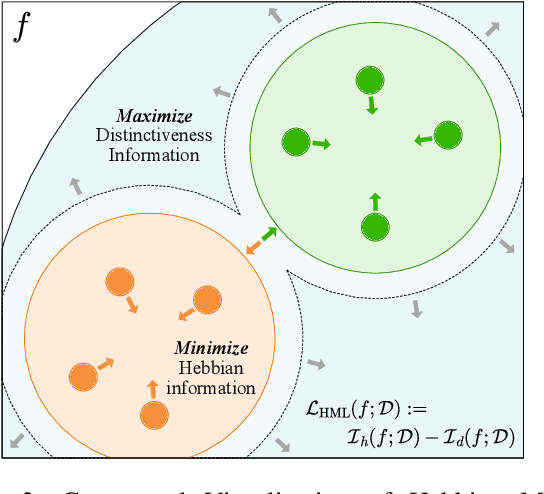
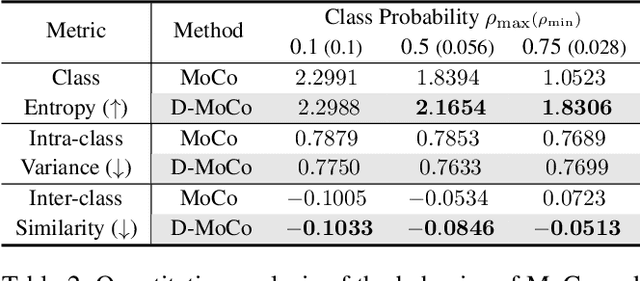
Recent machine learning algorithms have been developed using well-curated datasets, which often require substantial cost and resources. On the other hand, the direct use of raw data often leads to overfitting towards frequently occurring class information. To address class imbalances cost-efficiently, we propose an active data filtering process during self-supervised pre-training in our novel framework, Duplicate Elimination (DUEL). This framework integrates an active memory inspired by human working memory and introduces distinctiveness information, which measures the diversity of the data in the memory, to optimize both the feature extractor and the memory. The DUEL policy, which replaces the most duplicated data with new samples, aims to enhance the distinctiveness information in the memory and thereby mitigate class imbalances. We validate the effectiveness of the DUEL framework in class-imbalanced environments, demonstrating its robustness and providing reliable results in downstream tasks. We also analyze the role of the DUEL policy in the training process through various metrics and visualizations.
DUEL: Adaptive Duplicate Elimination on Working Memory for Self-Supervised Learning
Oct 31, 2022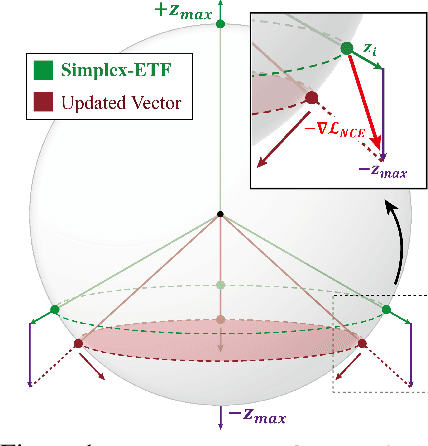
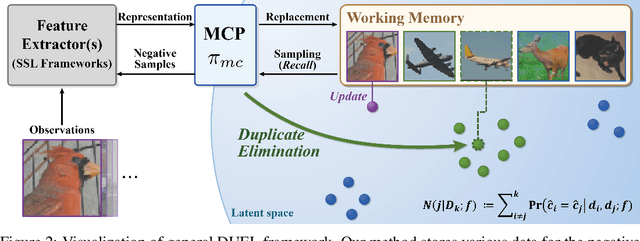
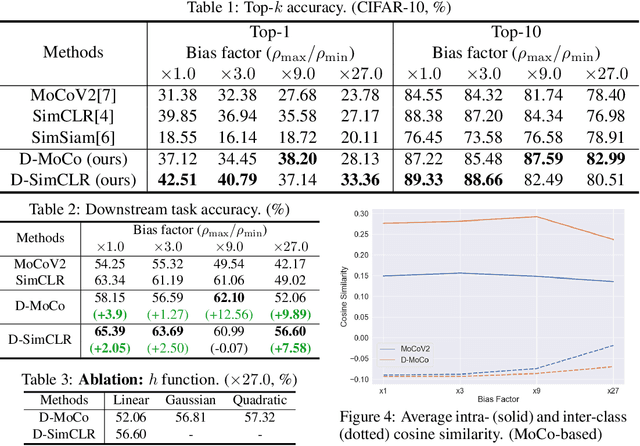
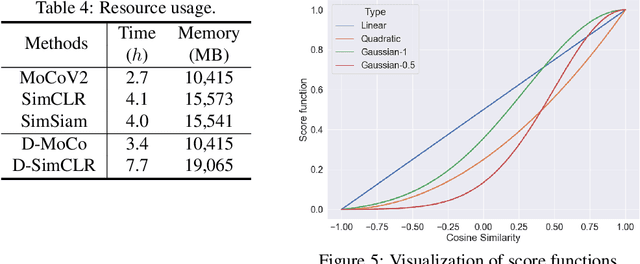
In Self-Supervised Learning (SSL), it is known that frequent occurrences of the collision in which target data and its negative samples share the same class can decrease performance. Especially in real-world data such as crawled data or robot-gathered observations, collisions may occur more often due to the duplicates in the data. To deal with this problem, we claim that sampling negative samples from the adaptively debiased distribution in the memory makes the model more stable than sampling from a biased dataset directly. In this paper, we introduce a novel SSL framework with adaptive Duplicate Elimination (DUEL) inspired by the human working memory. The proposed framework successfully prevents the downstream task performance from degradation due to a dramatic inter-class imbalance.
On the Importance of Critical Period in Multi-stage Reinforcement Learning
Aug 09, 2022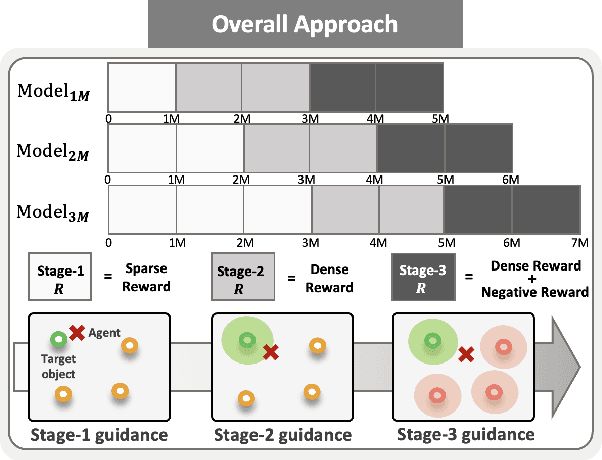
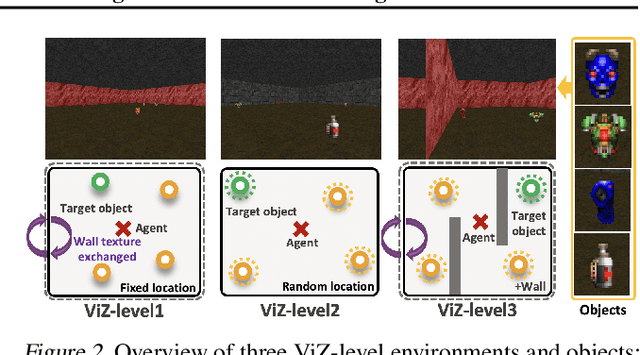
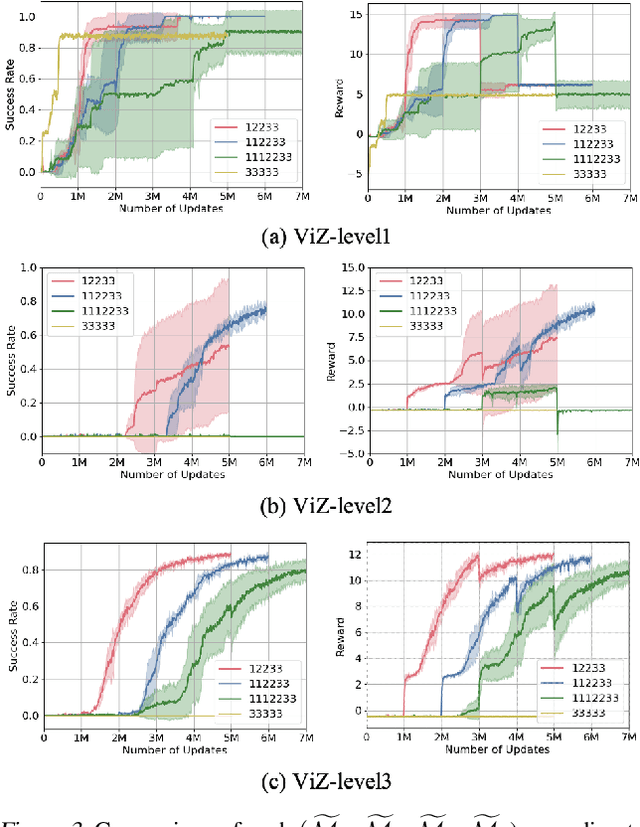
The initial years of an infant's life are known as the critical period, during which the overall development of learning performance is significantly impacted due to neural plasticity. In recent studies, an AI agent, with a deep neural network mimicking mechanisms of actual neurons, exhibited a learning period similar to human's critical period. Especially during this initial period, the appropriate stimuli play a vital role in developing learning ability. However, transforming human cognitive bias into an appropriate shaping reward is quite challenging, and prior works on critical period do not focus on finding the appropriate stimulus. To take a step further, we propose multi-stage reinforcement learning to emphasize finding ``appropriate stimulus" around the critical period. Inspired by humans' early cognitive-developmental stage, we use multi-stage guidance near the critical period, and demonstrate the appropriate shaping reward (stage-2 guidance) in terms of the AI agent's performance, efficiency, and stability.
Toddler-Guidance Learning: Impacts of Critical Period on Multimodal AI Agents
Jan 12, 2022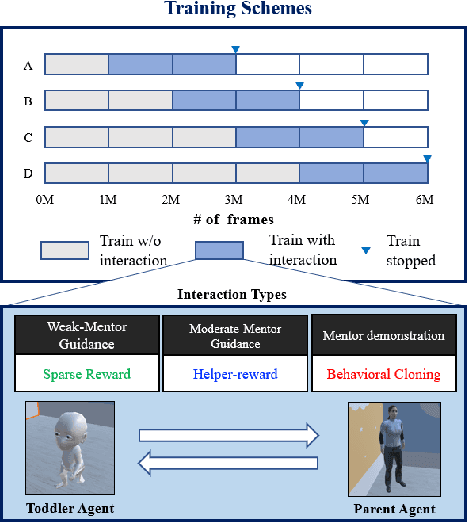

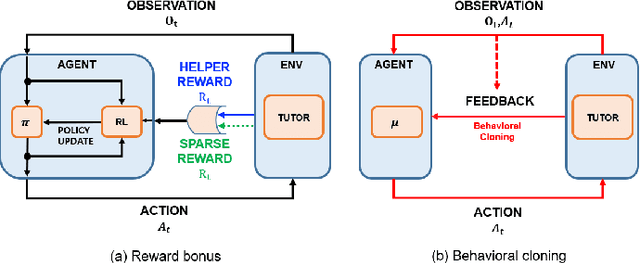
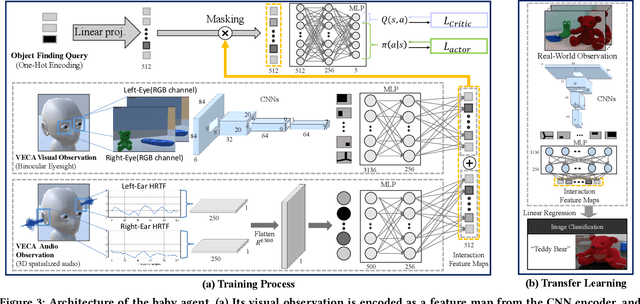
Critical periods are phases during which a toddler's brain develops in spurts. To promote children's cognitive development, proper guidance is critical in this stage. However, it is not clear whether such a critical period also exists for the training of AI agents. Similar to human toddlers, well-timed guidance and multimodal interactions might significantly enhance the training efficiency of AI agents as well. To validate this hypothesis, we adapt this notion of critical periods to learning in AI agents and investigate the critical period in the virtual environment for AI agents. We formalize the critical period and Toddler-guidance learning in the reinforcement learning (RL) framework. Then, we built up a toddler-like environment with VECA toolkit to mimic human toddlers' learning characteristics. We study three discrete levels of mutual interaction: weak-mentor guidance (sparse reward), moderate mentor guidance (helper-reward), and mentor demonstration (behavioral cloning). We also introduce the EAVE dataset consisting of 30,000 real-world images to fully reflect the toddler's viewpoint. We evaluate the impact of critical periods on AI agents from two perspectives: how and when they are guided best in both uni- and multimodal learning. Our experimental results show that both uni- and multimodal agents with moderate mentor guidance and critical period on 1 million and 2 million training steps show a noticeable improvement. We validate these results with transfer learning on the EAVE dataset and find the performance advancement on the same critical period and the guidance.
Learning task-agnostic representation via toddler-inspired learning
Jan 27, 2021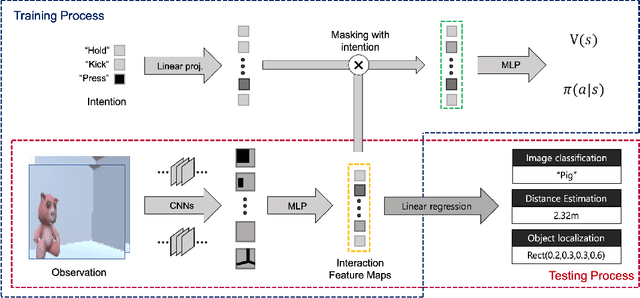


One of the inherent limitations of current AI systems, stemming from the passive learning mechanisms (e.g., supervised learning), is that they perform well on labeled datasets but cannot deduce knowledge on their own. To tackle this problem, we derive inspiration from a highly intentional learning system via action: the toddler. Inspired by the toddler's learning procedure, we design an interactive agent that can learn and store task-agnostic visual representation while exploring and interacting with objects in the virtual environment. Experimental results show that such obtained representation was expandable to various vision tasks such as image classification, object localization, and distance estimation tasks. In specific, the proposed model achieved 100%, 75.1% accuracy and 1.62% relative error, respectively, which is noticeably better than autoencoder-based model (99.7%, 66.1%, 1.95%), and also comparable with those of supervised models (100%, 87.3%, 0.71%).
DialGraph: Sparse Graph Learning Networks for Visual Dialog
Apr 14, 2020
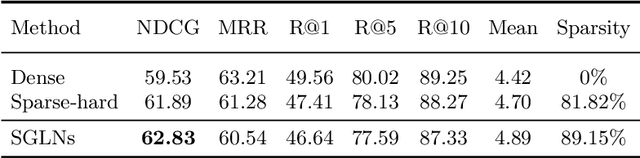
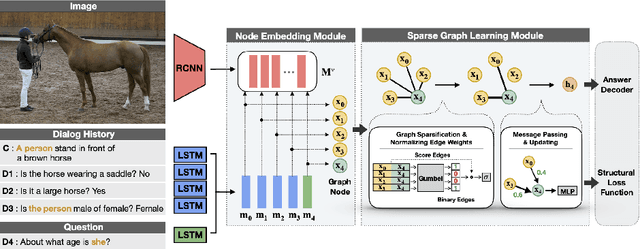
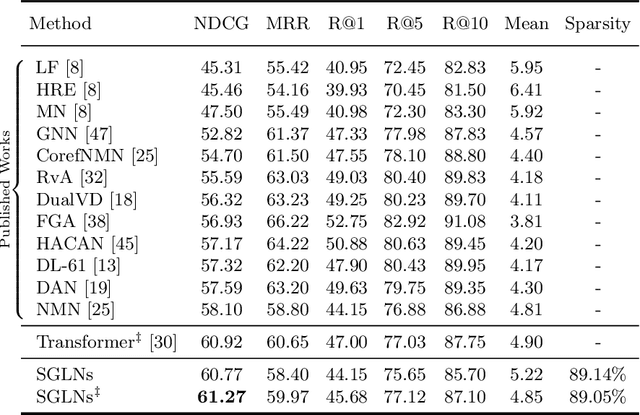
Visual dialog is a task of answering a sequence of questions grounded in an image utilizing a dialog history. Previous studies have implicitly explored the problem of reasoning semantic structures among the history using softmax attention. However, we argue that the softmax attention yields dense structures that could distract to answer the questions requiring partial or even no contextual information. In this paper, we formulate the visual dialog tasks as graph structure learning tasks. To tackle the problem, we propose Sparse Graph Learning Networks (SGLNs) consisting of a multimodal node embedding module and a sparse graph learning module. The proposed model explicitly learn sparse dialog structures by incorporating binary and score edges, leveraging a new structural loss function. Then, it finally outputs the answer, updating each node via a message passing framework. As a result, the proposed model outperforms the state-of-the-art approaches on the VisDial v1.0 dataset, only using 10.95% of the dialog history, as well as improves interpretability compared to baseline methods.