 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUEL: Duplicate Elimination on Active Memory for Self-Supervised Class-Imbalanced Learning
Feb 14, 2024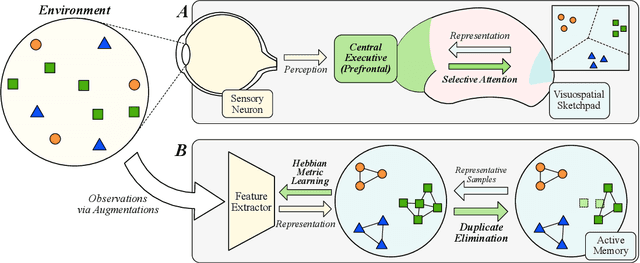
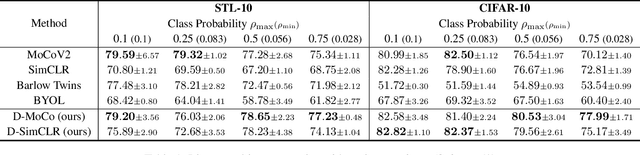
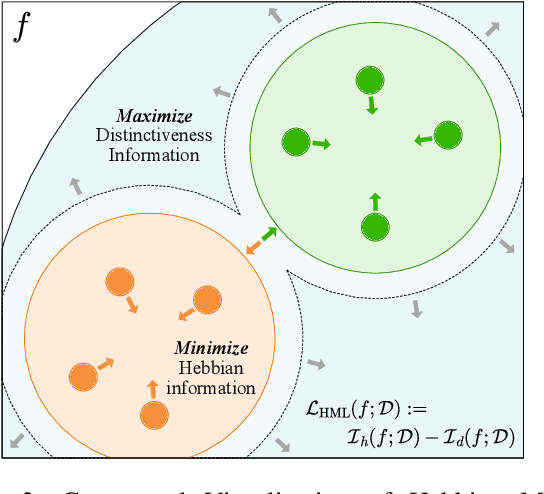
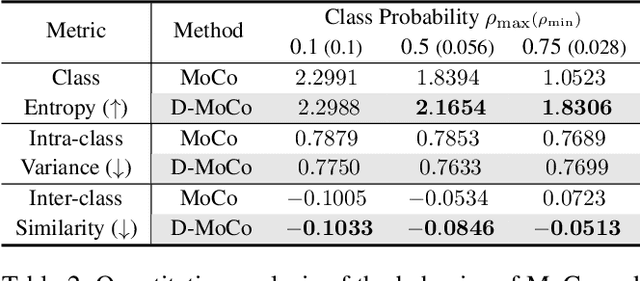
Recent machine learning algorithms have been developed using well-curated datasets, which often require substantial cost and resources. On the other hand, the direct use of raw data often leads to overfitting towards frequently occurring class information. To address class imbalances cost-efficiently, we propose an active data filtering process during self-supervised pre-training in our novel framework, Duplicate Elimination (DUEL). This framework integrates an active memory inspired by human working memory and introduces distinctiveness information, which measures the diversity of the data in the memory, to optimize both the feature extractor and the memory. The DUEL policy, which replaces the most duplicated data with new samples, aims to enhance the distinctiveness information in the memory and thereby mitigate class imbalances. We validate the effectiveness of the DUEL framework in class-imbalanced environments, demonstrating its robustness and providing reliable results in downstream tasks. We also analyze the role of the DUEL policy in the training process through various metrics and visualizations.