 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse to Dense: Toddler-inspired Reward Transition in Goal-Oriented Reinforcement Learning
Jan 29, 2025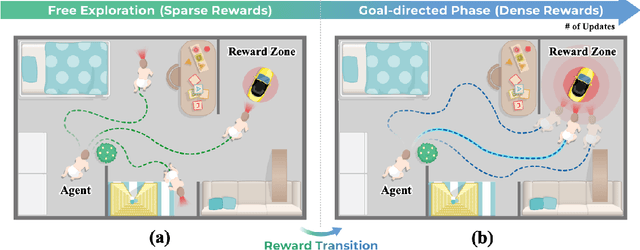
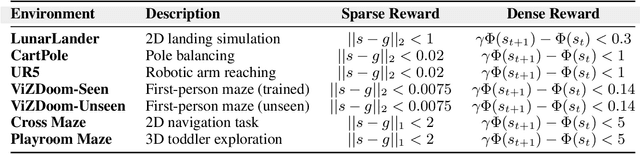
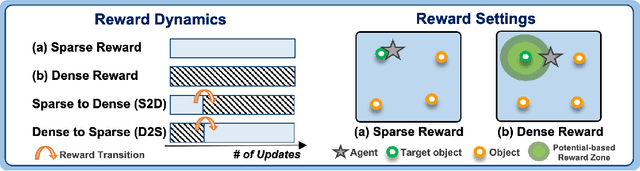
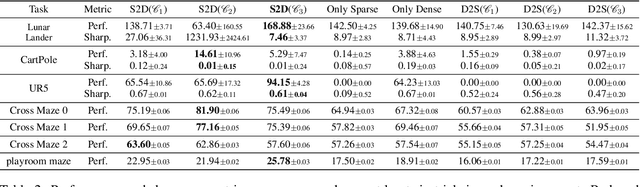
Reinforcement learning (RL) agents often face challenges in balancing exploration and exploitation, particularly in environments where sparse or dense rewards bias learning. Biological systems, such as human toddlers, naturally navigate this balance by transitioning from free exploration with sparse rewards to goal-directed behavior guided by increasingly dense rewards. Inspired by this natural progression, we investigate the Toddler-Inspired Reward Transition in goal-oriented RL tasks. Our study focuses on transitioning from sparse to potential-based dense (S2D) rewards while preserving optimal strategies. Through experiments on dynamic robotic arm manipulation and egocentric 3D navigation tasks, we demonstrate that effective S2D reward transitions significantly enhance learning performance and sample efficiency. Additionally, using a Cross-Density Visualizer, we show that S2D transitions smooth the policy loss landscape, resulting in wider minima that improve generalization in RL models. In addition, we reinterpret Tolman's maze experiments, underscoring the critical role of early free exploratory learning in the context of S2D rewards.
Unveiling the Significance of Toddler-Inspired Reward Transition in Goal-Oriented Reinforcement Learning
Mar 18, 2024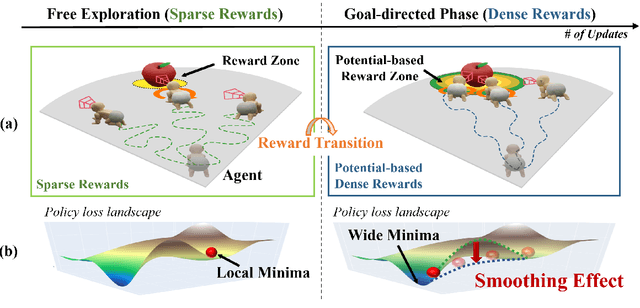

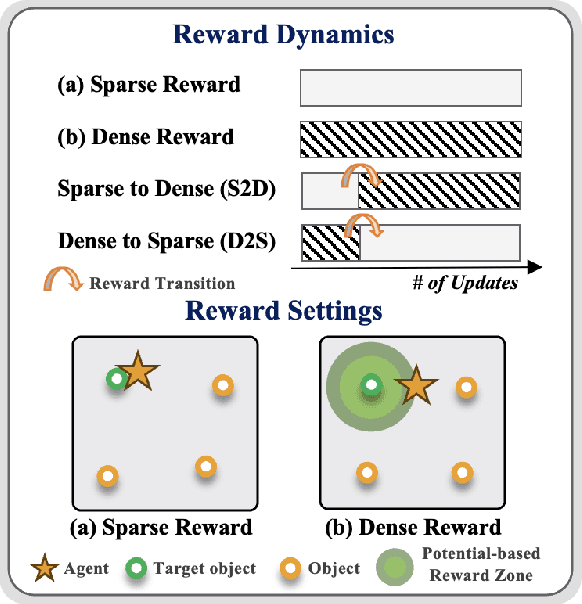
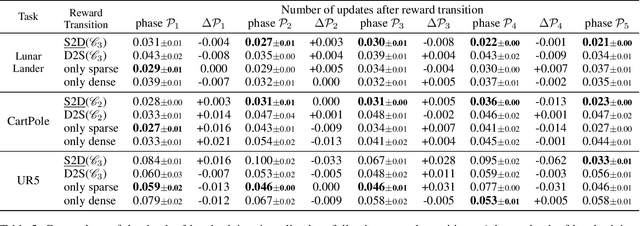
Toddlers evolve from free exploration with sparse feedback to exploiting prior experiences for goal-directed learning with denser rewards. Drawing inspiration from this Toddler-Inspired Reward Transition, we set out to explore the implications of varying reward transitions when incorporated into Reinforcement Learning (RL) tasks. Central to our inquiry is the transition from sparse to potential-based dense rewards, which share optimal strategies regardless of reward changes. Through various experiments, including those in egocentric navigation and robotic arm manipulation tasks, we found that proper reward transitions significantly influence sample efficiency and success rates. Of particular note is the efficacy of the toddler-inspired Sparse-to-Dense (S2D) transition. Beyond these performance metrics, using Cross-Density Visualizer technique, we observed that transitions, especially the S2D, smooth the policy loss landscape, promoting wide minima that enhance generalization in RL models.
Visual Hindsight Self-Imitation Learning for Interactive Navigation
Dec 05, 2023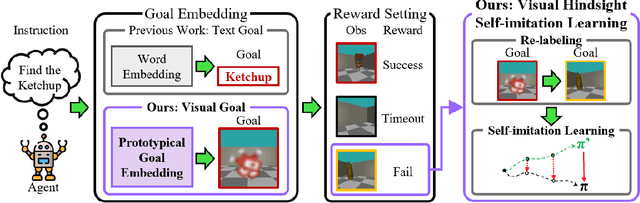
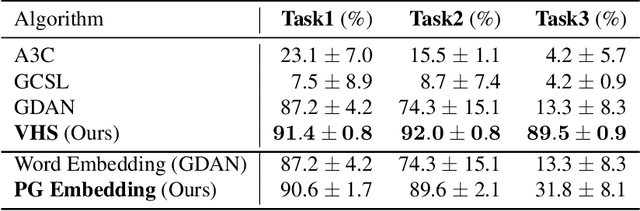
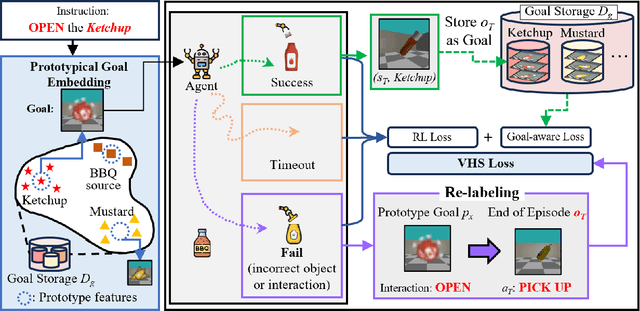
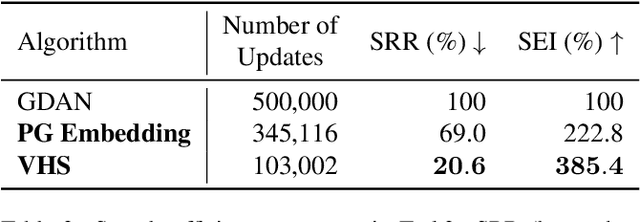
Interactive visual navigation tasks, which involve following instructions to reach and interact with specific targets, are challenging not only because successful experiences are very rare but also because the complex visual inputs require a substantial number of samples. Previous methods for these tasks often rely on intricately designed dense rewards or the use of expensive expert data for imitation learning. To tackle these challenges, we propose a novel approach, Visual Hindsight Self-Imitation Learning (VHS) for enhancing sample efficiency through hindsight goal re-labeling and self-imitation. We also introduce a prototypical goal embedding method derived from experienced goal observations, that is particularly effective in vision-based and partially observable environments. This embedding technique allows the agent to visually reinterpret its unsuccessful attempts, enabling vision-based goal re-labeling and self-imitation from enhanced successful experiences. Experimental results show that VHS outperforms existing techniques in interactive visual navigation tasks, confirming its superior performance and sample efficiency.
Neural Collage Transfer: Artistic Reconstruction via Material Manipulation
Nov 03, 2023



Collage is a creative art form that uses diverse material scraps as a base unit to compose a single image. Although pixel-wise generation techniques can reproduce a target image in collage style, it is not a suitable method due to the solid stroke-by-stroke nature of the collage form. While some previous works for stroke-based rendering produced decent sketches and paintings, collages have received much less attention in research despite their popularity as a style. In this paper, we propose a method for learning to make collages via reinforcement learning without the need for demonstrations or collage artwork data. We design the collage Markov Decision Process (MDP), which allows the agent to handle various materials and propose a model-based soft actor-critic to mitigate the agent's training burden derived from the sophisticated dynamics of collage. Moreover, we devise additional techniques such as active material selection and complexity-based multi-scale collage to handle target images at any size and enhance the results' aesthetics by placing relatively more scraps in areas of high complexity. Experimental results show that the trained agent appropriately selected and pasted materials to regenerate the target image into a collage and obtained a higher evaluation score on content and style than pixel-wise generation methods. Code is available at https://github.com/northadventure/CollageRL.
L-SA: Learning Under-Explored Targets in Multi-Target Reinforcement Learning
May 23, 2023



Tasks that involve interaction with various targets are called multi-target tasks. When applying general reinforcement learning approaches for such tasks, certain targets that are difficult to access or interact with may be neglected throughout the course of training - a predicament we call Under-explored Target Problem (UTP). To address this problem, we propose L-SA (Learning by adaptive Sampling and Active querying) framework that includes adaptive sampling and active querying. In the L-SA framework, adaptive sampling dynamically samples targets with the highest increase of success rates at a high proportion, resulting in curricular learning from easy to hard targets. Active querying prompts the agent to interact more frequently with under-explored targets that need more experience or exploration. Our experimental results on visual navigation tasks show that the L-SA framework improves sample efficiency as well as success rates on various multi-target tasks with UTP. Also, it is experimentally demonstrated that the cyclic relationship between adaptive sampling and active querying effectively improves the sample richness of under-explored targets and alleviates UTP.
From Scratch to Sketch: Deep Decoupled Hierarchical Reinforcement Learning for Robotic Sketching Agent
Aug 09, 2022
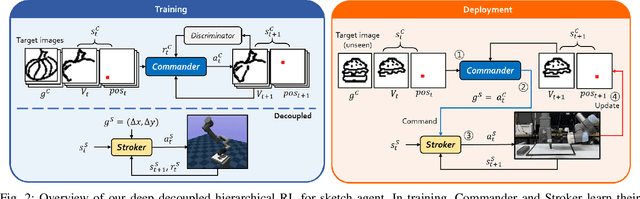
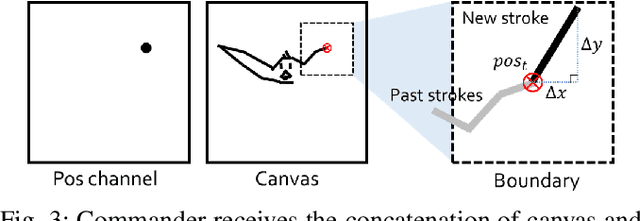
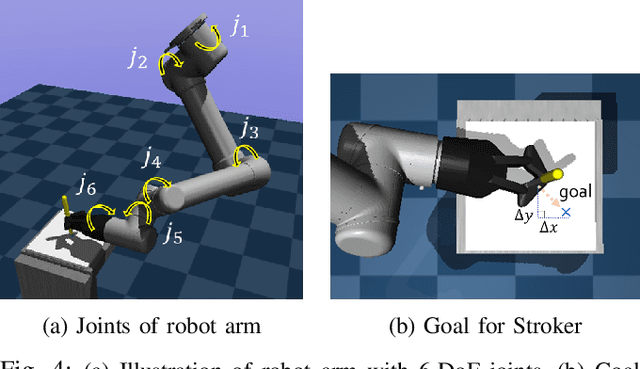
We present an automated learning framework for a robotic sketching agent that is capable of learning stroke-based rendering and motor control simultaneously. We formulate the robotic sketching problem as a deep decoupled hierarchical reinforcement learning; two policies for stroke-based rendering and motor control are learned independently to achieve sub-tasks for drawing, and form a hierarchy when cooperating for real-world drawing. Without hand-crafted features, drawing sequences or trajectories, and inverse kinematics, the proposed method trains the robotic sketching agent from scratch. We performed experiments with a 6-DoF robot arm with 2F gripper to sketch doodles. Our experimental results show that the two policies successfully learned the sub-tasks and collaborated to sketch the target images. Also, the robustness and flexibility were examined by varying drawing tools and surfaces.
On the Importance of Critical Period in Multi-stage Reinforcement Learning
Aug 09, 2022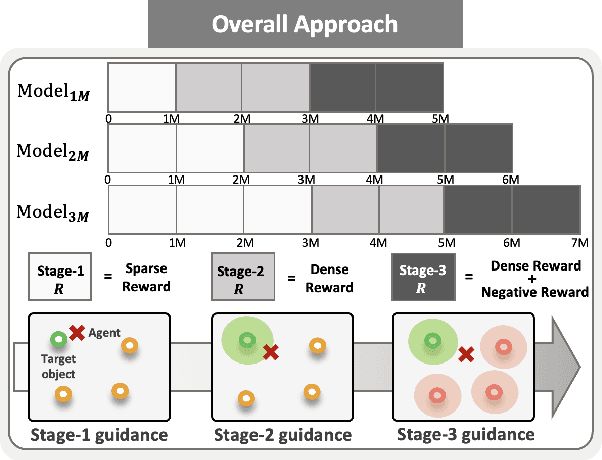
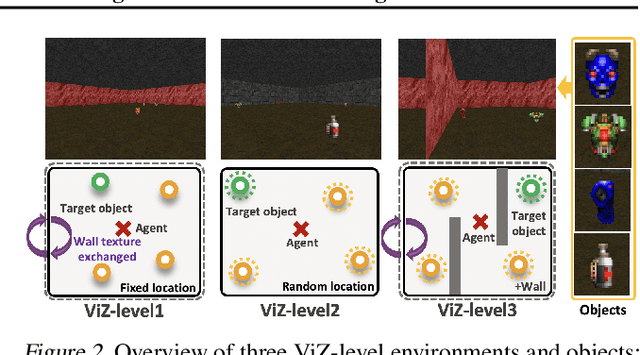
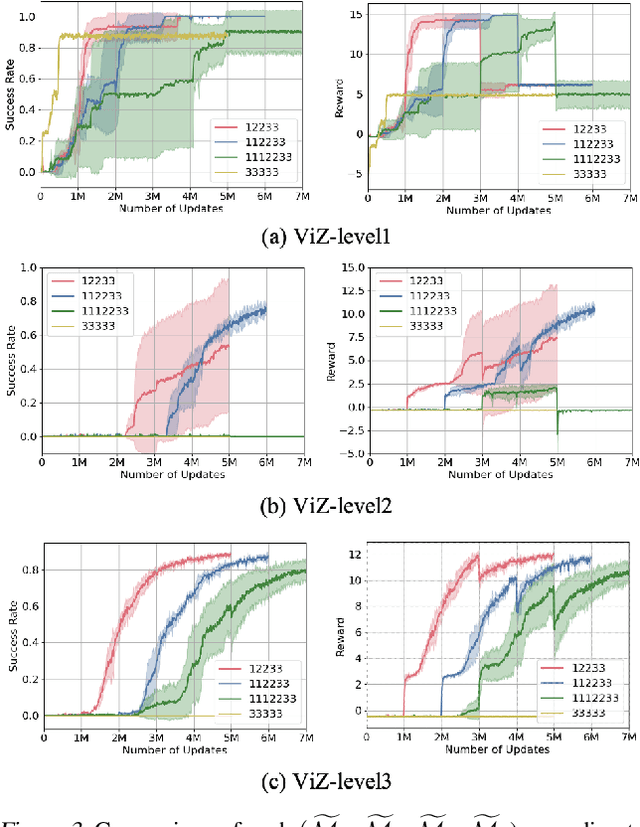
The initial years of an infant's life are known as the critical period, during which the overall development of learning performance is significantly impacted due to neural plasticity. In recent studies, an AI agent, with a deep neural network mimicking mechanisms of actual neurons, exhibited a learning period similar to human's critical period. Especially during this initial period, the appropriate stimuli play a vital role in developing learning ability. However, transforming human cognitive bias into an appropriate shaping reward is quite challenging, and prior works on critical period do not focus on finding the appropriate stimulus. To take a step further, we propose multi-stage reinforcement learning to emphasize finding ``appropriate stimulus" around the critical period. Inspired by humans' early cognitive-developmental stage, we use multi-stage guidance near the critical period, and demonstrate the appropriate shaping reward (stage-2 guidance) in terms of the AI agent's performance, efficiency, and stability.
Toddler-Guidance Learning: Impacts of Critical Period on Multimodal AI Agents
Jan 12, 2022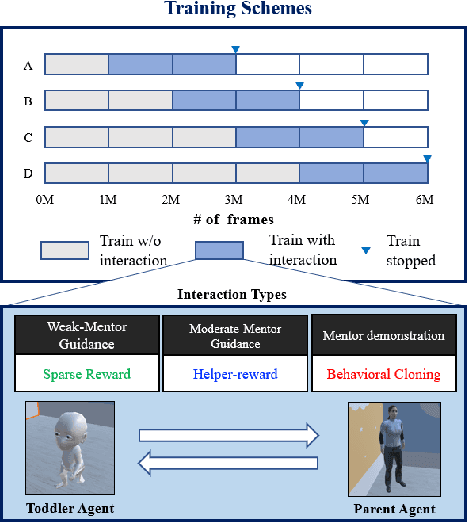

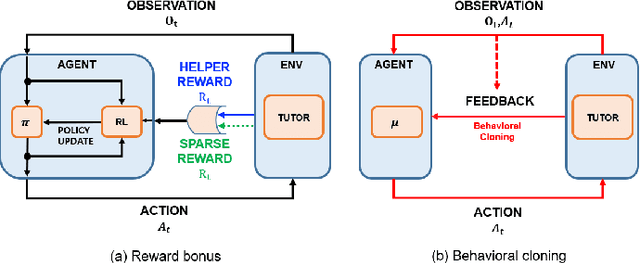
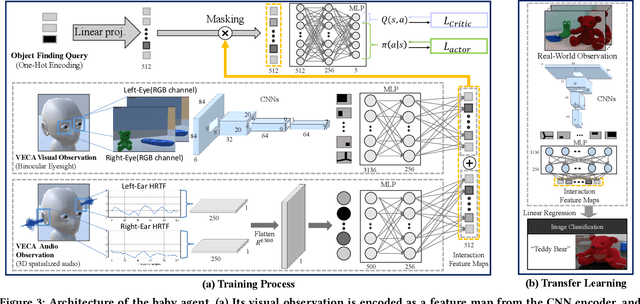
Critical periods are phases during which a toddler's brain develops in spurts. To promote children's cognitive development, proper guidance is critical in this stage. However, it is not clear whether such a critical period also exists for the training of AI agents. Similar to human toddlers, well-timed guidance and multimodal interactions might significantly enhance the training efficiency of AI agents as well. To validate this hypothesis, we adapt this notion of critical periods to learning in AI agents and investigate the critical period in the virtual environment for AI agents. We formalize the critical period and Toddler-guidance learning in the reinforcement learning (RL) framework. Then, we built up a toddler-like environment with VECA toolkit to mimic human toddlers' learning characteristics. We study three discrete levels of mutual interaction: weak-mentor guidance (sparse reward), moderate mentor guidance (helper-reward), and mentor demonstration (behavioral cloning). We also introduce the EAVE dataset consisting of 30,000 real-world images to fully reflect the toddler's viewpoint. We evaluate the impact of critical periods on AI agents from two perspectives: how and when they are guided best in both uni- and multimodal learning. Our experimental results show that both uni- and multimodal agents with moderate mentor guidance and critical period on 1 million and 2 million training steps show a noticeable improvement. We validate these results with transfer learning on the EAVE dataset and find the performance advancement on the same critical period and the guidance.
Goal-Aware Cross-Entropy for Multi-Target Reinforcement Learning
Oct 26, 2021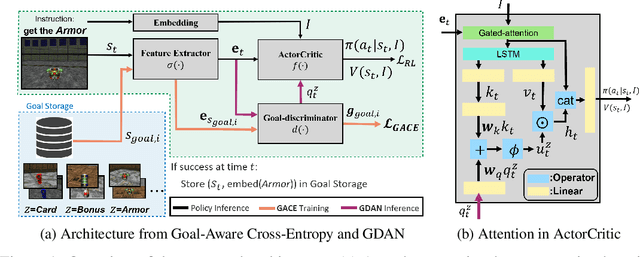
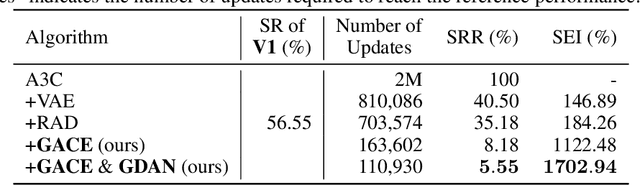


Learning in a multi-target environment without prior knowledge about the targets requires a large amount of samples and makes generalization difficult. To solve this problem, it is important to be able to discriminate targets through semantic understanding. In this paper, we propose goal-aware cross-entropy (GACE) loss, that can be utilized in a self-supervised way using auto-labeled goal states alongside reinforcement learning. Based on the loss, we then devise goal-discriminative attention networks (GDAN) which utilize the goal-relevant information to focus on the given instruction. We evaluate the proposed methods on visual navigation and robot arm manipulation tasks with multi-target environments and show that GDAN outperforms the state-of-the-art methods in terms of task success ratio, sample efficiency, and generalization. Additionally, qualitative analyses demonstrate that our proposed method can help the agent become aware of and focus on the given instruction clearly, promoting goal-directed behavior.
Toward a Human-Level Video Understanding Intelligence
Oct 18, 2021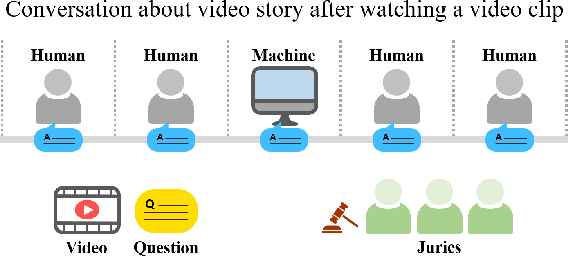

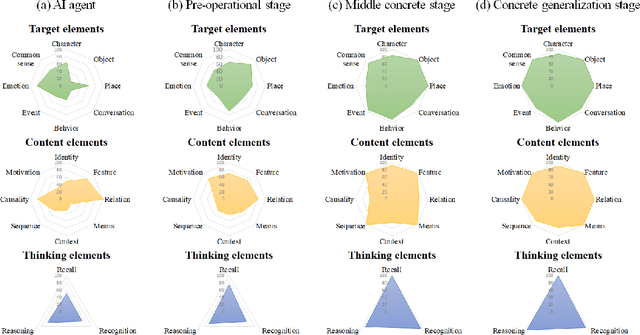
We aim to develop an AI agent that can watch video clips and have a conversation with human about the video story. Developing video understanding intelligence is a significantly challenging task, and evaluation methods for adequately measuring and analyzing the progress of AI agent are lacking as well. In this paper, we propose the Video Turing Test to provide effective and practical assessments of video understanding intelligence as well as human-likeness evaluation of AI agents. We define a general format and procedure of the Video Turing Test and present a case study to confirm the effectiveness and usefulness of the proposed test.