 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Online Mirror Descent for Robust Learning in Schrödinger Bridge
Apr 03, 2025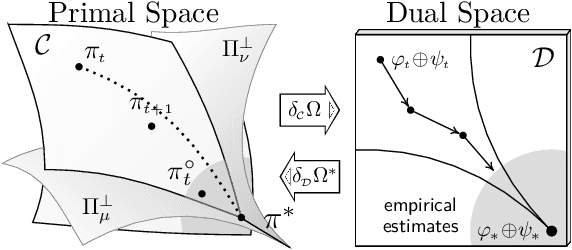

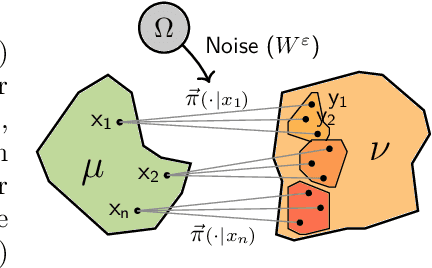
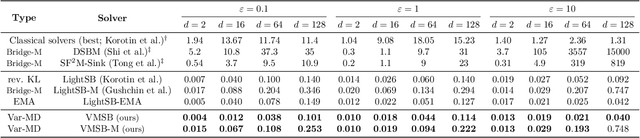
Sch\"odinger bridge (SB) has evolved into a universal class of probabilistic generative models. In practice, however, estimated learning signals are often uncertain, and the reliability promised by existing methods is often based on speculative optimal-case scenarios. Recent studies regarding the Sinkhorn algorithm through mirror descent (MD) have gained attention, revealing geometric insights into solution acquisition of the SB problems. In this paper, we propose a variational online MD (OMD) framework for the SB problems, which provides further stability to SB solvers. We formally prove convergence and a regret bound for the novel OMD formulation of SB acquisition. As a result, we propose a simulation-free SB algorithm called Variational Mirrored Schr\"odinger Bridge (VMSB) by utilizing the Wasserstein-Fisher-Rao geometry of the Gaussian mixture parameterization for Schr\"odinger potentials. Based on the Wasserstein gradient flow theory, the algorithm offers tractable learning dynamics that precisely approximate each OMD step. In experiments, we validate the performance of the proposed VMSB algorithm across an extensive suite of benchmarks. VMSB consistently outperforms contemporary SB solvers on a range of SB problems, demonstrating the robustness predicted by our theory.
Unveiling the Significance of Toddler-Inspired Reward Transition in Goal-Oriented Reinforcement Learning
Mar 18, 2024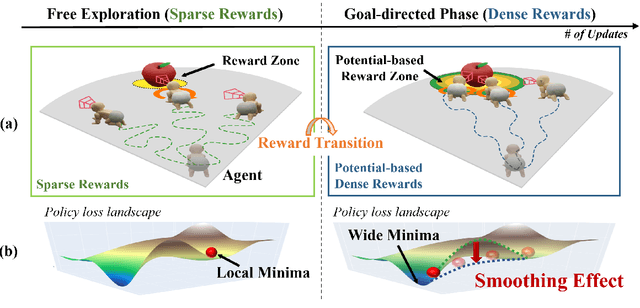

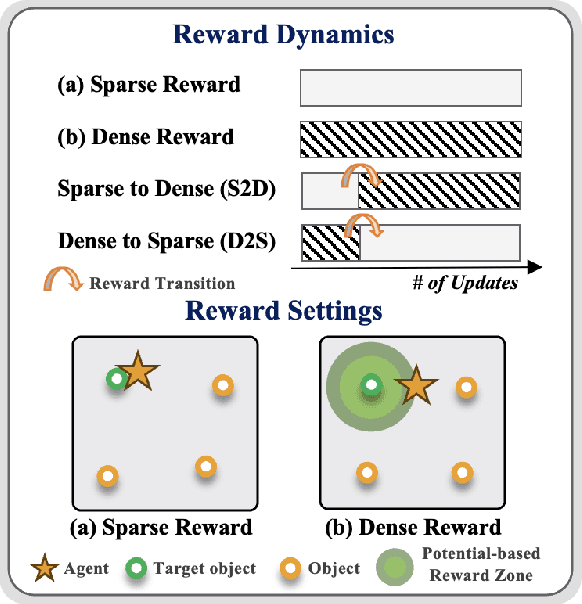
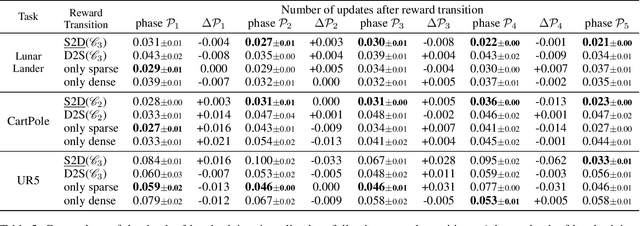
Toddlers evolve from free exploration with sparse feedback to exploiting prior experiences for goal-directed learning with denser rewards. Drawing inspiration from this Toddler-Inspired Reward Transition, we set out to explore the implications of varying reward transitions when incorporated into Reinforcement Learning (RL) tasks. Central to our inquiry is the transition from sparse to potential-based dense rewards, which share optimal strategies regardless of reward changes. Through various experiments, including those in egocentric navigation and robotic arm manipulation tasks, we found that proper reward transitions significantly influence sample efficiency and success rates. Of particular note is the efficacy of the toddler-inspired Sparse-to-Dense (S2D) transition. Beyond these performance metrics, using Cross-Density Visualizer technique, we observed that transitions, especially the S2D, smooth the policy loss landscape, promoting wide minima that enhance generalization in RL models.