 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR: Unsupervised Goal-Conditioned RL via Temporal Distance-Aware Representations
Paper and Code
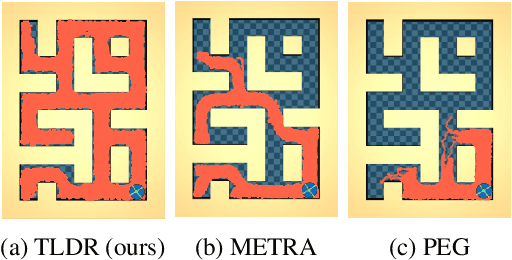
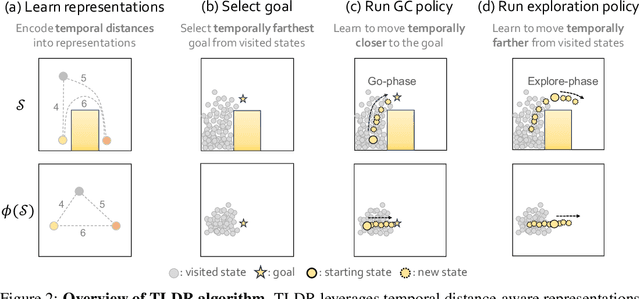

Unsupervised goal-conditioned reinforcement learning (GCRL) is a promising paradigm for developing diverse robotic skills without external supervision. However, existing unsupervised GCRL methods often struggle to cover a wide range of states in complex environments due to their limited exploration and sparse or noisy rewards for GCRL. To overcome these challenges, we propose a novel unsupervised GCRL method that leverages TemporaL Distance-aware Representations (TLDR). TLDR selects faraway goals to initiate exploration and computes intrinsic exploration rewards and goal-reaching rewards, based on temporal distance. Specifically, our exploration policy seeks states with large temporal distances (i.e. covering a large state space), while the goal-conditioned policy learns to minimize the temporal distance to the goal (i.e. reaching the goal). Our experimental results in six simulated robotic locomotion environments demonstrate that our method significantly outperforms previous unsupervised GCRL methods in achieving a wide variety of states.