 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoZero: Robot Learning from Smart Glasses
May 26, 2025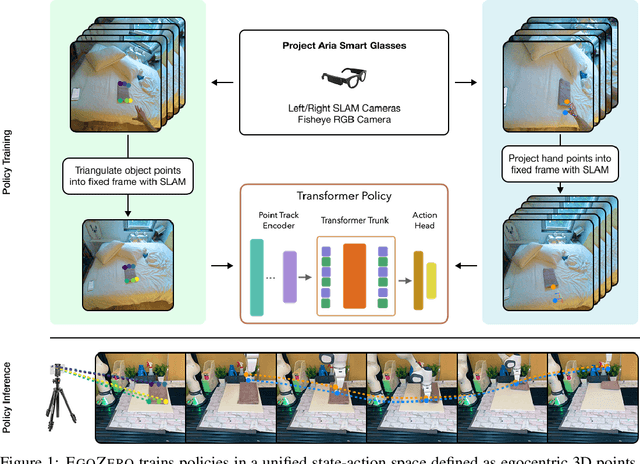
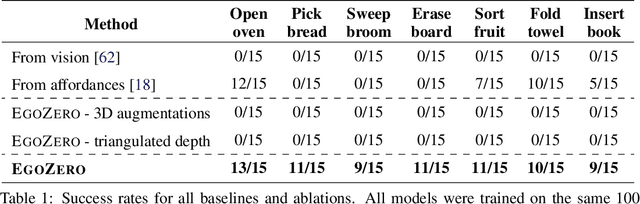

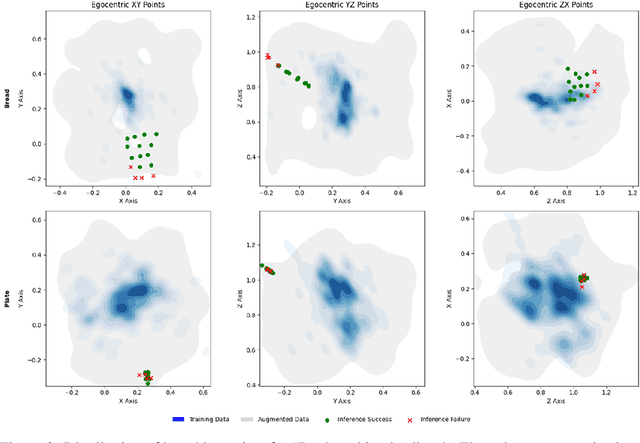
Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans interact constantly with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, $\textbf{and zero robot data}$. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning - paving the way toward a future of abundant, diverse, and naturalistic training data for robots. Code and videos are available at https://egozero-robot.github.io.
Language Reward Modulation for Pretraining Reinforcement Learning
Aug 23, 2023Using learned reward functions (LRFs) as a means to solve sparse-reward reinforcement learning (RL) tasks has yielded some steady progress in task-complexity through the years. In this work, we question whether today's LRFs are best-suited as a direct replacement for task rewards. Instead, we propose leveraging the capabilities of LRFs as a pretraining signal for RL. Concretely, we propose $\textbf{LA}$nguage Reward $\textbf{M}$odulated $\textbf{P}$retraining (LAMP) which leverages the zero-shot capabilities of Vision-Language Models (VLMs) as a $\textit{pretraining}$ utility for RL as opposed to a downstream task reward. LAMP uses a frozen, pretrained VLM to scalably generate noisy, albeit shaped exploration rewards by computing the contrastive alignment between a highly diverse collection of language instructions and the image observations of an agent in its pretraining environment. LAMP optimizes these rewards in conjunction with standard novelty-seeking exploration rewards with reinforcement learning to acquire a language-conditioned, pretrained policy. Our VLM pretraining approach, which is a departure from previous attempts to use LRFs, can warmstart sample-efficient learning on robot manipulation tasks in RLBench.
Video Prediction Models as Rewards for Reinforcement Learning
May 23, 2023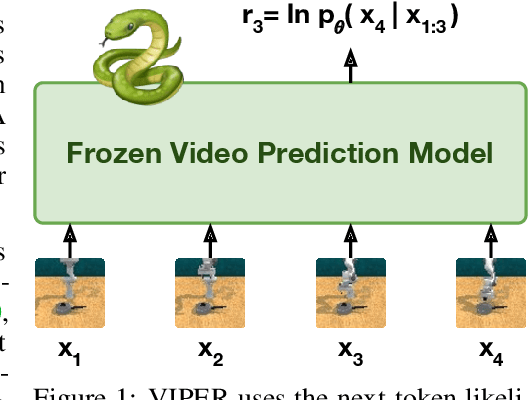


Specifying reward signals that allow agents to learn complex behaviors is a long-standing challenge in reinforcement learning. A promising approach is to extract preferences for behaviors from unlabeled videos, which are widely available on the internet. We present Video Prediction Rewards (VIPER), an algorithm that leverages pretrained video prediction models as action-free reward signals for reinforcement learning. Specifically, we first train an autoregressive transformer on expert videos and then use the video prediction likelihoods as reward signals for a reinforcement learning agent. VIPER enables expert-level control without programmatic task rewards across a wide range of DMC, Atari, and RLBench tasks. Moreover, generalization of the video prediction model allows us to derive rewards for an out-of-distribution environment where no expert data is available, enabling cross-embodiment generalization for tabletop manipulation. We see our work as starting point for scalable reward specification from unlabeled videos that will benefit from the rapid advances in generative modeling. Source code and datasets are available on the project website: https://escontrela.me
Skill-Based Reinforcement Learning with Intrinsic Reward Matching
Oct 17, 2022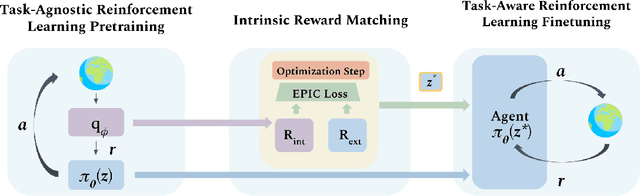
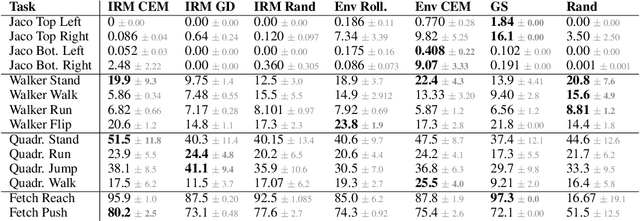
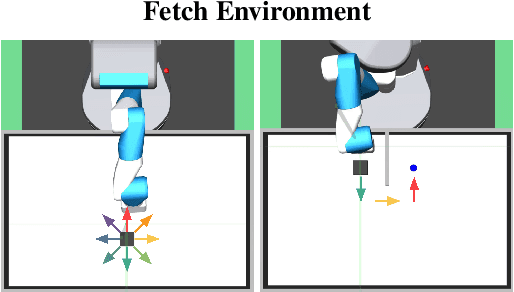
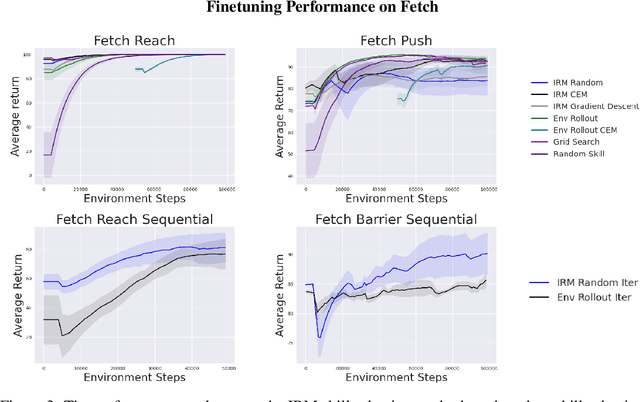
While unsupervised skill discovery has shown promise in autonomously acquiring behavioral primitives, there is still a large methodological disconnect between task-agnostic skill pretraining and downstream, task-aware finetuning. We present Intrinsic Reward Matching (IRM), which unifies these two phases of learning via the $\textit{skill discriminator}$, a pretraining model component often discarded during finetuning. Conventional approaches finetune pretrained agents directly at the policy level, often relying on expensive environment rollouts to empirically determine the optimal skill. However, often the most concise yet complete description of a task is the reward function itself, and skill learning methods learn an $\textit{intrinsic}$ reward function via the discriminator that corresponds to the skill policy. We propose to leverage the skill discriminator to $\textit{match}$ the intrinsic and downstream task rewards and determine the optimal skill for an unseen task without environment samples, consequently finetuning with greater sample-efficiency. Furthermore, we generalize IRM to sequence skills and solve more complex, long-horizon tasks. We demonstrate that IRM is competitive with previous skill selection methods on the Unsupervised Reinforcement Learning Benchmark and enables us to utilize pretrained skills far more effectively on challenging tabletop manipulation tasks.
Recurrent Control Nets for Deep Reinforcement Learning
Jan 18, 2019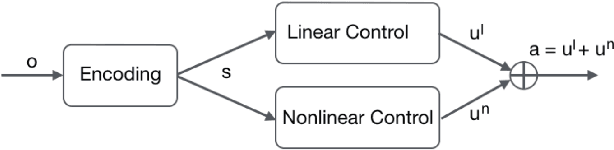
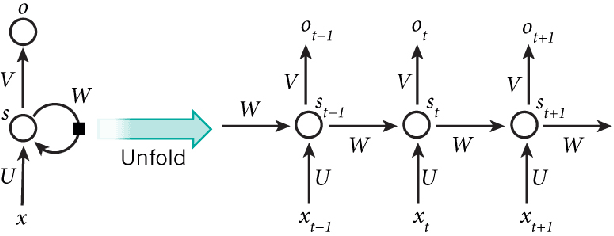
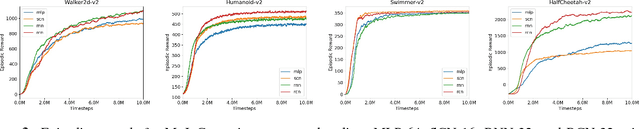
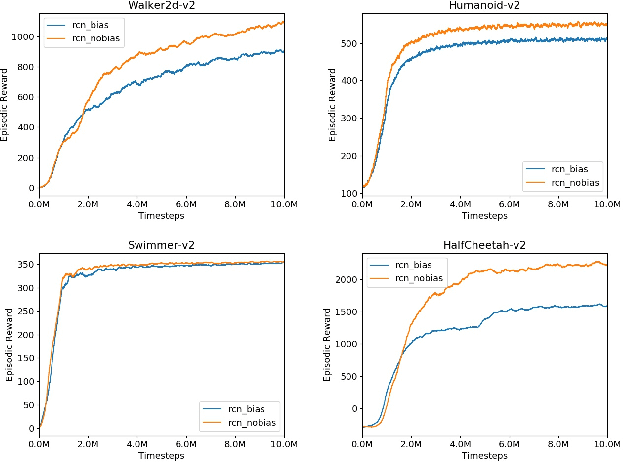
Central Pattern Generators (CPGs) are biological neural circuits capable of producing coordinated rhythmic outputs in the absence of rhythmic input. As a result, they are responsible for most rhythmic motion in living organisms. This rhythmic control is broadly applicable to fields such as locomotive robotics and medical devices. In this paper, we explore the possibility of creating a self-sustaining CPG network for reinforcement learning that learns rhythmic motion more efficiently and across more general environments than the current multilayer perceptron (MLP) baseline models. Recent work introduces the Structured Control Net (SCN), which maintains linear and nonlinear modules for local and global control, respectively. Here, we show that time-sequence architectures such as Recurrent Neural Networks (RNNs) model CPGs effectively. Combining previous work with RNNs and SCNs, we introduce the Recurrent Control Net (RCN), which adds a linear component to the, RCNs match and exceed the performance of baseline MLPs and SCNs across all environment tasks. Our findings confirm existing intuitions for RNNs on reinforcement learning tasks, and demonstrate promise of SCN-like structures in reinforcement learning.