 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning
Nov 30, 2024



Humanoid robots have significant gaps in their sensing and perception, making it hard to perform motion planning in dense environments. To address this, we introduce ARMOR, a novel egocentric perception system that integrates both hardware and software, specifically incorporating wearable-like depth sensors for humanoid robots. Our distributed perception approach enhances the robot's spatial awareness, and facilitates more agile motion planning. We also train a transformer-based imitation learning (IL) policy in simulation to perform dynamic collision avoidance, by leveraging around 86 hours worth of human realistic motions from the AMASS dataset. We show that our ARMOR perception is superior against a setup with multiple dense head-mounted, and externally mounted depth cameras, with a 63.7% reduction in collisions, and 78.7% improvement on success rate. We also compare our IL policy against a sampling-based motion planning expert cuRobo, showing 31.6% less collisions, 16.9% higher success rate, and 26x reduction in computational latency. Lastly, we deploy our ARMOR perception on our real-world GR1 humanoid from Fourier Intelligence. We are going to update the link to the source code, HW description, and 3D CAD files in the arXiv version of this text.
Human Following in Mobile Platforms with Person Re-Identification
Sep 21, 2023



Human following is a crucial feature of human-robot interaction, yet it poses numerous challenges to mobile agents in real-world scenarios. Some major hurdles are that the target person may be in a crowd, obstructed by others, or facing away from the agent. To tackle these challenges, we present a novel person re-identification module composed of three parts: a 360-degree visual registration, a neural-based person re-identification using human faces and torsos, and a motion tracker that records and predicts the target person's future position. Our human-following system also addresses other challenges, including identifying fast-moving targets with low latency, searching for targets that move out of the camera's sight, collision avoidance, and adaptively choosing different following mechanisms based on the distance between the target person and the mobile agent. Extensive experiments show that our proposed person re-identification module significantly enhances the human-following feature compared to other baseline variants.
Safe Real-World Reinforcement Learning for Mobile Agent Obstacle Avoidance
Sep 23, 2022



Collision avoidance is key for mobile robots and agents to operate safely in the real world. In this work, we present an efficient and effective collision avoidance system that combines real-world reinforcement learning (RL), search-based online trajectory planning, and automatic emergency intervention, e.g. automatic emergency braking (AEB). The goal of the RL is to learn effective search heuristics that speed up the search for collision-free trajectory and reduce the frequency of triggering automatic emergency interventions. This novel setup enables RL to learn safely and directly on mobile robots in a real-world indoor environment, minimizing actual crashes even during training. Our real-world experiments show that, when compared with several baselines, our approach enjoys a higher average speed, lower crash rate, higher goals reached rate, smaller computation overhead, and smoother overall control.
Recurrent Control Nets for Deep Reinforcement Learning
Jan 18, 2019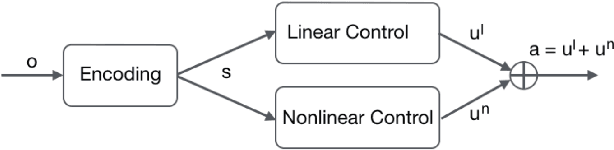
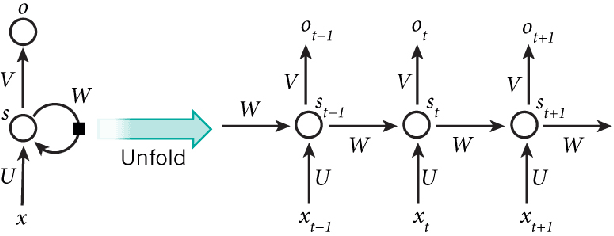
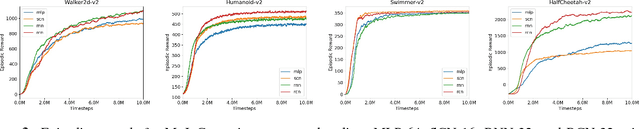
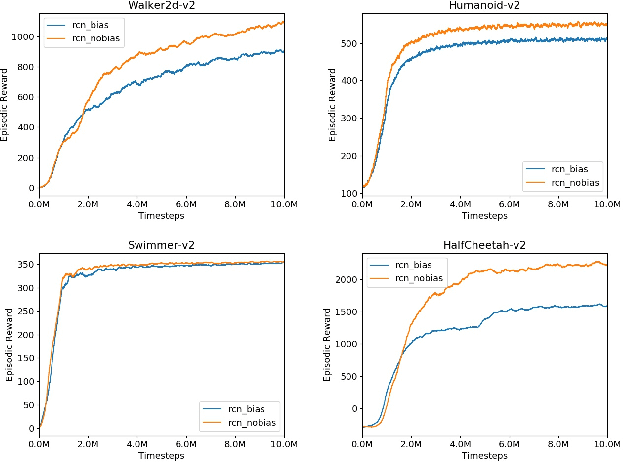
Central Pattern Generators (CPGs) are biological neural circuits capable of producing coordinated rhythmic outputs in the absence of rhythmic input. As a result, they are responsible for most rhythmic motion in living organisms. This rhythmic control is broadly applicable to fields such as locomotive robotics and medical devices. In this paper, we explore the possibility of creating a self-sustaining CPG network for reinforcement learning that learns rhythmic motion more efficiently and across more general environments than the current multilayer perceptron (MLP) baseline models. Recent work introduces the Structured Control Net (SCN), which maintains linear and nonlinear modules for local and global control, respectively. Here, we show that time-sequence architectures such as Recurrent Neural Networks (RNNs) model CPGs effectively. Combining previous work with RNNs and SCNs, we introduce the Recurrent Control Net (RCN), which adds a linear component to the, RCNs match and exceed the performance of baseline MLPs and SCNs across all environment tasks. Our findings confirm existing intuitions for RNNs on reinforcement learning tasks, and demonstrate promise of SCN-like structures in reinforcement learning.
Structured Control Nets for Deep Reinforcement Learning
Feb 22, 2018


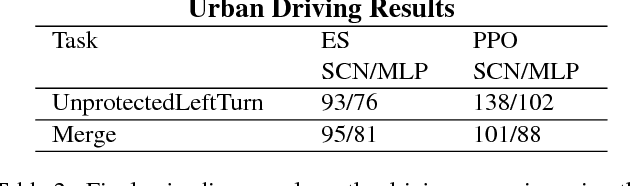
In recent years, Deep Reinforcement Learning has made impressive advances in solving several important benchmark problems for sequential decision making. Many control applications use a generic multilayer perceptron (MLP) for non-vision parts of the policy network. In this work, we propose a new neural network architecture for the policy network representation that is simple yet effective. The proposed Structured Control Net (SCN) splits the generic MLP into two separate sub-modules: a nonlinear control module and a linear control module. Intuitively, the nonlinear control is for forward-looking and global control, while the linear control stabilizes the local dynamics around the residual of global control. We hypothesize that this will bring together the benefits of both linear and nonlinear policies: improve training sample efficiency, final episodic reward, and generalization of learned policy, while requiring a smaller network and being generally applicable to different training methods. We validated our hypothesis with competitive results on simulations from OpenAI MuJoCo, Roboschool, Atari, and a custom 2D urban driving environment, with various ablation and generalization tests, trained with multiple black-box and policy gradient training methods. The proposed architecture has the potential to improve upon broader control tasks by incorporating problem specific priors into the architecture. As a case study, we demonstrate much improved performance for locomotion tasks by emulating the biological central pattern generators (CPGs) as the nonlinear part of the architecture.