 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePts3D-LLM: Studying the Impact of Token Structure for 3D Scene Understanding With Large Language Models
Jun 06, 2025Effectively representing 3D scenes for Multimodal Large Language Models (MLLMs) is crucial yet challenging. Existing approaches commonly only rely on 2D image features and use varied tokenization approaches. This work presents a rigorous study of 3D token structures, systematically comparing video-based and point-based representations while maintaining consistent model backbones and parameters. We propose a novel approach that enriches visual tokens by incorporating 3D point cloud features from a Sonata pretrained Point Transformer V3 encoder. Our experiments demonstrate that merging explicit 3D features significantly boosts performance. Furthermore, we show that point-based token structures can rival video-based ones when the points are cleverly sampled and ordered. Our best models from both structures achieve state-of-the-art results on multiple 3D understanding benchmarks. We emphasize our analysis of token structures as a key contribution, alongside transparent reporting of results averaged over multiple seeds, a practice we believe is vital for robust progress in the field.
DR-MPC: Deep Residual Model Predictive Control for Real-world Social Navigation
Oct 14, 2024



How can a robot safely navigate around people exhibiting complex motion patterns? Reinforcement Learning (RL) or Deep RL (DRL) in simulation holds some promise, although much prior work relies on simulators that fail to precisely capture the nuances of real human motion. To address this gap, we propose Deep Residual Model Predictive Control (DR-MPC), a method to enable robots to quickly and safely perform DRL from real-world crowd navigation data. By blending MPC with model-free DRL, DR-MPC overcomes the traditional DRL challenges of large data requirements and unsafe initial behavior. DR-MPC is initialized with MPC-based path tracking, and gradually learns to interact more effectively with humans. To further accelerate learning, a safety component estimates when the robot encounters out-of-distribution states and guides it away from likely collisions. In simulation, we show that DR-MPC substantially outperforms prior work, including traditional DRL and residual DRL models. Real-world experiments show our approach successfully enables a robot to navigate a variety of crowded situations with few errors using less than 4 hours of training data.
MakeWay: Object-Aware Costmaps for Proactive Indoor Navigation Using LiDAR
Aug 30, 2024



In this paper, we introduce a LiDAR-based robot navigation system, based on novel object-aware affordance-based costmaps. Utilizing a 3D object detection network, our system identifies objects of interest in LiDAR keyframes, refines their 3D poses with the Iterative Closest Point (ICP) algorithm, and tracks them via Kalman filters and the Hungarian algorithm for data association. It then updates existing object poses with new associated detections and creates new object maps for unmatched detections. Using the maintained object-level mapping system, our system creates affordance-driven object costmaps for proactive collision avoidance in path planning. Additionally, we address the scarcity of indoor semantic LiDAR data by introducing an automated labeling technique. This method utilizes a CAD model database for accurate ground-truth annotations, encompassing bounding boxes, positions, orientations, and point-wise semantics of each object in LiDAR sequences. Our extensive evaluations, conducted in both simulated and real-world robot platforms, highlights the effectiveness of proactive object avoidance by using object affordance costmaps, enhancing robotic navigation safety and efficiency. The system can operate in real-time onboard and we intend to release our code and data for public use.
KPConvX: Modernizing Kernel Point Convolution with Kernel Attention
May 21, 2024



In the field of deep point cloud understanding, KPConv is a unique architecture that uses kernel points to locate convolutional weights in space, instead of relying on Multi-Layer Perceptron (MLP) encodings. While it initially achieved success, it has since been surpassed by recent MLP networks that employ updated designs and training strategies. Building upon the kernel point principle, we present two novel designs: KPConvD (depthwise KPConv), a lighter design that enables the use of deeper architectures, and KPConvX, an innovative design that scales the depthwise convolutional weights of KPConvD with kernel attention values. Using KPConvX with a modern architecture and training strategy, we are able to outperform current state-of-the-art approaches on the ScanObjectNN, Scannetv2, and S3DIS datasets. We validate our design choices through ablation studies and release our code and models.
Embedding Pose Graph, Enabling 3D Foundation Model Capabilities with a Compact Representation
Mar 20, 2024



This paper presents the Embedding Pose Graph (EPG), an innovative method that combines the strengths of foundation models with a simple 3D representation suitable for robotics applications. Addressing the need for efficient spatial understanding in robotics, EPG provides a compact yet powerful approach by attaching foundation model features to the nodes of a pose graph. Unlike traditional methods that rely on bulky data formats like voxel grids or point clouds, EPG is lightweight and scalable. It facilitates a range of robotic tasks, including open-vocabulary querying, disambiguation, image-based querying, language-directed navigation, and re-localization in 3D environments. We showcase the effectiveness of EPG in handling these tasks, demonstrating its capacity to improve how robots interact with and navigate through complex spaces. Through both qualitative and quantitative assessments, we illustrate EPG's strong performance and its ability to outperform existing methods in re-localization. Our work introduces a crucial step forward in enabling robots to efficiently understand and operate within large-scale 3D spaces.
Human Following in Mobile Platforms with Person Re-Identification
Sep 21, 2023



Human following is a crucial feature of human-robot interaction, yet it poses numerous challenges to mobile agents in real-world scenarios. Some major hurdles are that the target person may be in a crowd, obstructed by others, or facing away from the agent. To tackle these challenges, we present a novel person re-identification module composed of three parts: a 360-degree visual registration, a neural-based person re-identification using human faces and torsos, and a motion tracker that records and predicts the target person's future position. Our human-following system also addresses other challenges, including identifying fast-moving targets with low latency, searching for targets that move out of the camera's sight, collision avoidance, and adaptively choosing different following mechanisms based on the distance between the target person and the mobile agent. Extensive experiments show that our proposed person re-identification module significantly enhances the human-following feature compared to other baseline variants.
The Foreseeable Future: Self-Supervised Learning to Predict Dynamic Scenes for Indoor Navigation
Aug 26, 2022
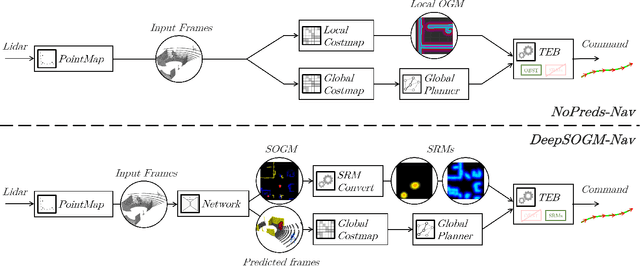
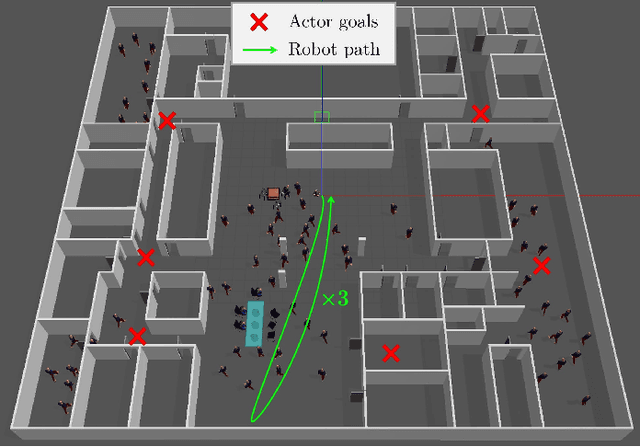
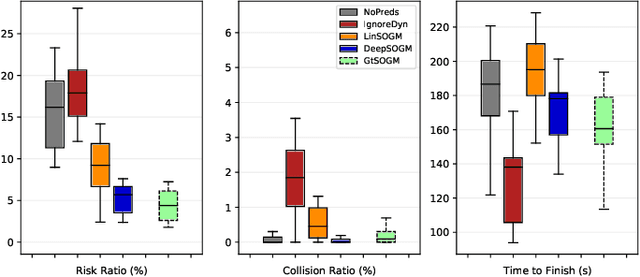
We present a method for generating, predicting, and using Spatiotemporal Occupancy Grid Maps (SOGM), which embed future semantic information of real dynamic scenes. We present an auto-labeling process that creates SOGMs from noisy real navigation data. We use a 3D-2D feedforward architecture, trained to predict the future time steps of SOGMs, given 3D lidar frames as input. Our pipeline is entirely self-supervised, thus enabling lifelong learning for real robots. The network is composed of a 3D back-end that extracts rich features and enables the semantic segmentation of the lidar frames, and a 2D front-end that predicts the future information embedded in the SOGM representation, potentially capturing the complexities and uncertainties of real-world multi-agent, multi-future interactions. We also design a navigation system that uses these predicted SOGMs within planning, after they have been transformed into Spatiotemporal Risk Maps (SRMs). We verify our navigation system's abilities in simulation, validate it on a real robot, study SOGM predictions on real data in various circumstances, and provide a novel indoor 3D lidar dataset, collected during our experiments, which includes our automated annotations.
Learning Spatiotemporal Occupancy Grid Maps for Lifelong Navigation in Dynamic Scenes
Aug 24, 2021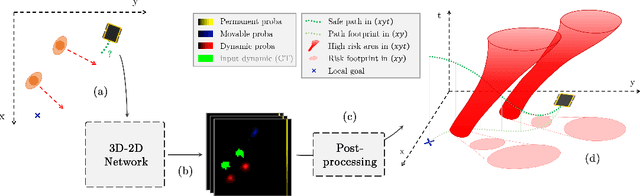
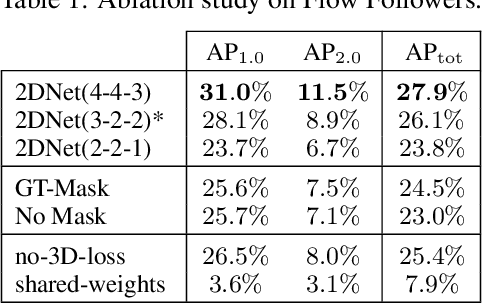
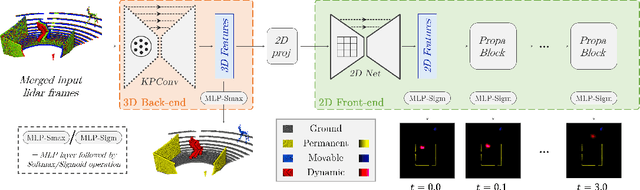

We present a novel method for generating, predicting, and using Spatiotemporal Occupancy Grid Maps (SOGM), which embed future information of dynamic scenes. Our automated generation process creates groundtruth SOGMs from previous navigation data. We use them to train a 3D-2D feedforward architecture, in a self-supervised fashion, thus enabling lifelong learning for robots. The automated generation process uses ray-tracing to label points in the robot environment based on their dynamic properties. The network is composed of a 3D back-end that extracts rich features and enables the semantic segmentation of the lidar frames, and a 2D front-end that predicts the future information embedded in the SOGMs. We also design a navigation pipeline using these predicted SOGMs. We provide both quantitative and qualitative insights into the predictions and validate our choices of network design with an ablation study.
Unsupervised Learning of Lidar Features for Use in a Probabilistic Trajectory Estimator
Feb 22, 2021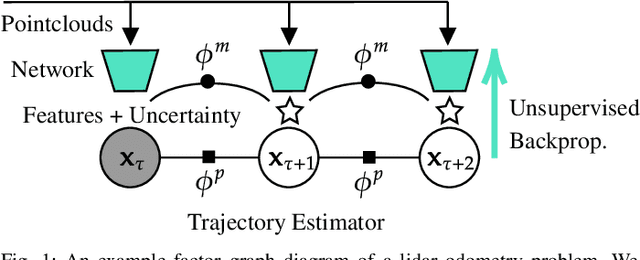


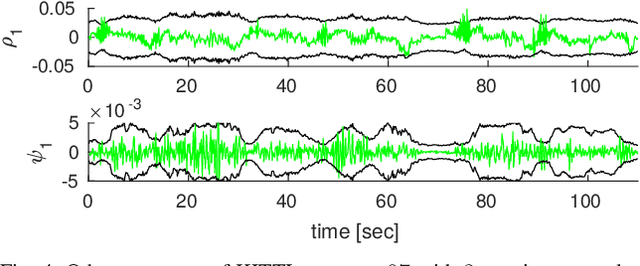
We present unsupervised parameter learning in a Gaussian variational inference setting that combines classic trajectory estimation for mobile robots with deep learning for rich sensor data, all under a single learning objective. The framework is an extension of an existing system identification method that optimizes for the observed data likelihood, which we improve with modern advances in batch trajectory estimation and deep learning. Though the framework is general to any form of parameter learning and sensor modality, we demonstrate application to feature and uncertainty learning with a deep network for 3D lidar odometry. Our framework learns from only the on-board lidar data, and does not require any form of groundtruth supervision. We demonstrate that our lidar odometry performs better than existing methods that learn the full estimator with a deep network, and comparable to state-of-the-art ICP-based methods on the KITTI odometry dataset. We additionally show results on lidar data from the Oxford RobotCar dataset.
Self-Supervised Learning of Lidar Segmentation for Autonomous Indoor Navigation
Dec 10, 2020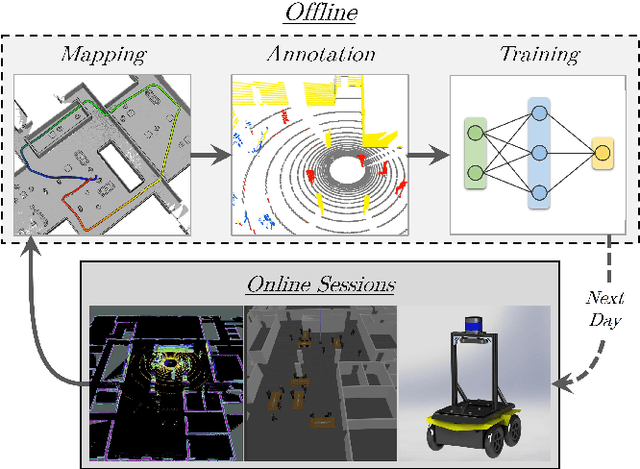
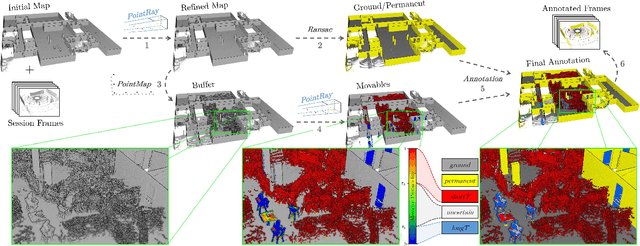
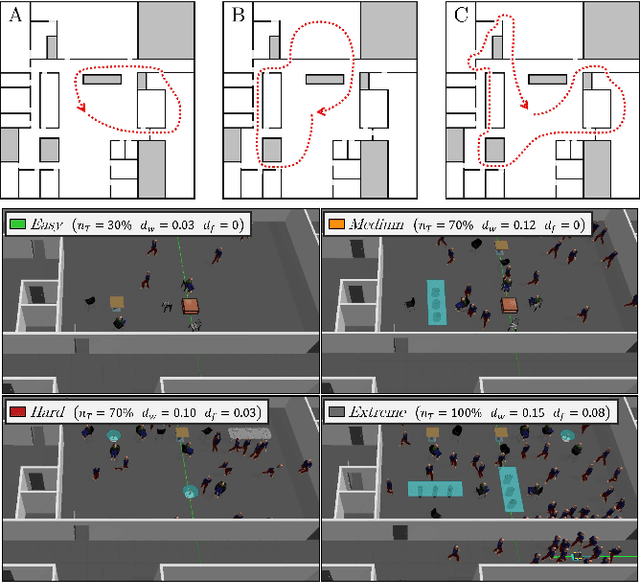
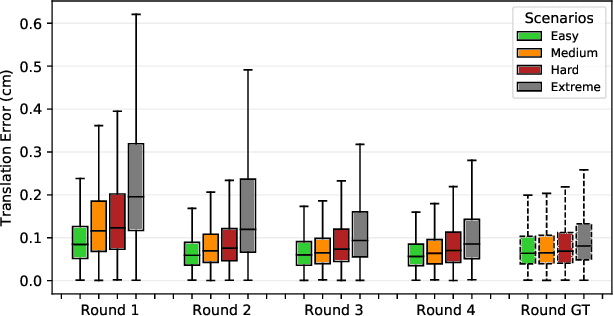
We present a self-supervised learning approach for the semantic segmentation of lidar frames. Our method is used to train a deep point cloud segmentation architecture without any human annotation. The annotation process is automated with the combination of simultaneous localization and mapping (SLAM) and ray-tracing algorithms. By performing multiple navigation sessions in the same environment, we are able to identify permanent structures, such as walls, and disentangle short-term and long-term movable objects, such as people and tables, respectively. New sessions can then be performed using a network trained to predict these semantic labels. We demonstrate the ability of our approach to improve itself over time, from one session to the next. With semantically filtered point clouds, our robot can navigate through more complex scenarios, which, when added to the training pool, help to improve our network predictions. We provide insights into our network predictions and show that our approach can also improve the performances of common localization techniques.