 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Lidar Segmentation for Autonomous Indoor Navigation
Paper and Code
Dec 10, 2020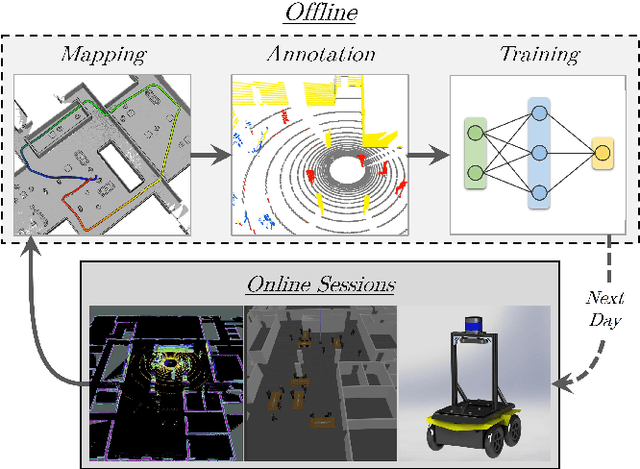
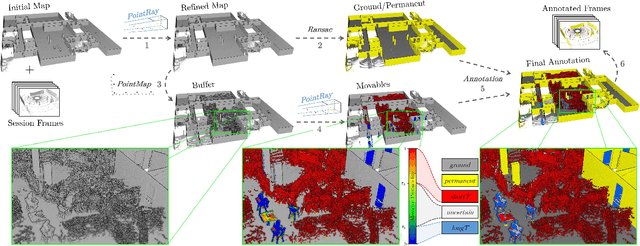
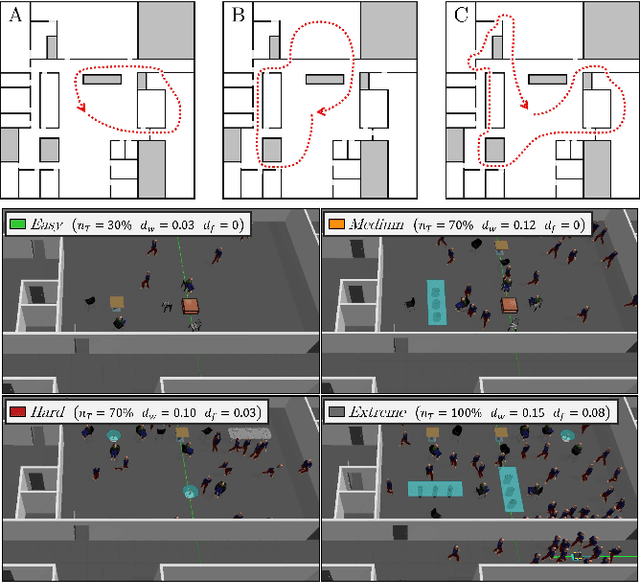
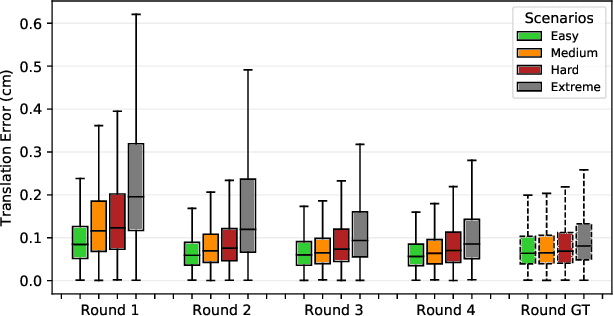
We present a self-supervised learning approach for the semantic segmentation of lidar frames. Our method is used to train a deep point cloud segmentation architecture without any human annotation. The annotation process is automated with the combination of simultaneous localization and mapping (SLAM) and ray-tracing algorithms. By performing multiple navigation sessions in the same environment, we are able to identify permanent structures, such as walls, and disentangle short-term and long-term movable objects, such as people and tables, respectively. New sessions can then be performed using a network trained to predict these semantic labels. We demonstrate the ability of our approach to improve itself over time, from one session to the next. With semantically filtered point clouds, our robot can navigate through more complex scenarios, which, when added to the training pool, help to improve our network predictions. We provide insights into our network predictions and show that our approach can also improve the performances of common localization techniques.