 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeeping an Eye on Things: Deep Learned Features for Long-Term Visual Localization
Sep 09, 2021
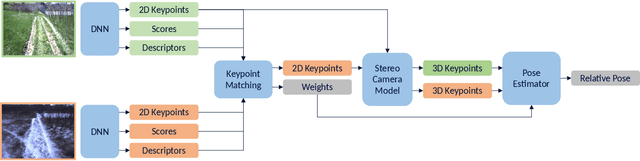
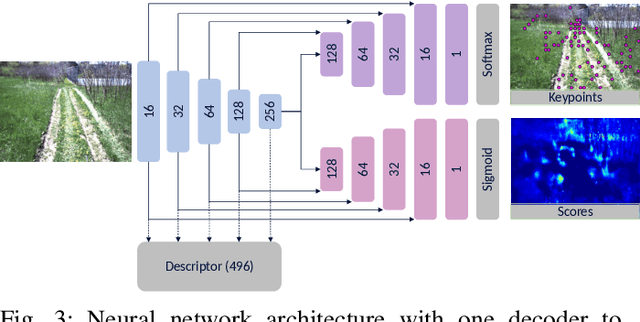

In this paper, we learn visual features that we use to first build a map and then localize a robot driving autonomously across a full day of lighting change, including in the dark. We train a neural network to predict sparse keypoints with associated descriptors and scores that can be used together with a classical pose estimator for localization. Our training pipeline includes a differentiable pose estimator such that training can be supervised with ground truth poses from data collected earlier, in our case from 2016 and 2017 gathered with multi-experience Visual Teach and Repeat (VT&R). We then insert the learned features into the existing VT&R pipeline to perform closed-loop path-following in unstructured outdoor environments. We show successful path following across all lighting conditions despite the robot's map being constructed using daylight conditions. Moreover, we explore generalizability of the features by driving the robot across all lighting conditions in two new areas not present in the feature training dataset. In all, we validated our approach with 30 km of autonomous path-following experiments in challenging conditions.
Unsupervised Learning of Lidar Features for Use in a Probabilistic Trajectory Estimator
Feb 22, 2021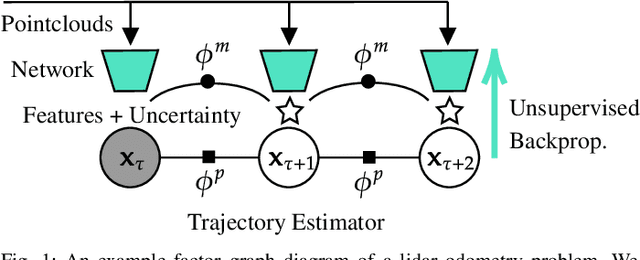


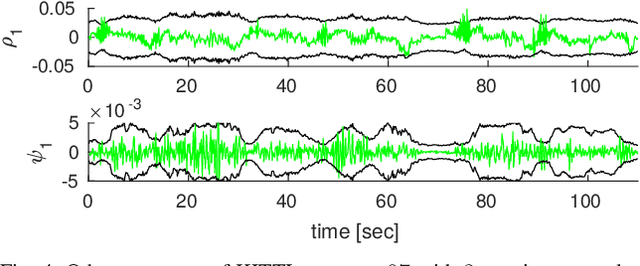
We present unsupervised parameter learning in a Gaussian variational inference setting that combines classic trajectory estimation for mobile robots with deep learning for rich sensor data, all under a single learning objective. The framework is an extension of an existing system identification method that optimizes for the observed data likelihood, which we improve with modern advances in batch trajectory estimation and deep learning. Though the framework is general to any form of parameter learning and sensor modality, we demonstrate application to feature and uncertainty learning with a deep network for 3D lidar odometry. Our framework learns from only the on-board lidar data, and does not require any form of groundtruth supervision. We demonstrate that our lidar odometry performs better than existing methods that learn the full estimator with a deep network, and comparable to state-of-the-art ICP-based methods on the KITTI odometry dataset. We additionally show results on lidar data from the Oxford RobotCar dataset.
Self-Supervised Learning of Lidar Segmentation for Autonomous Indoor Navigation
Dec 10, 2020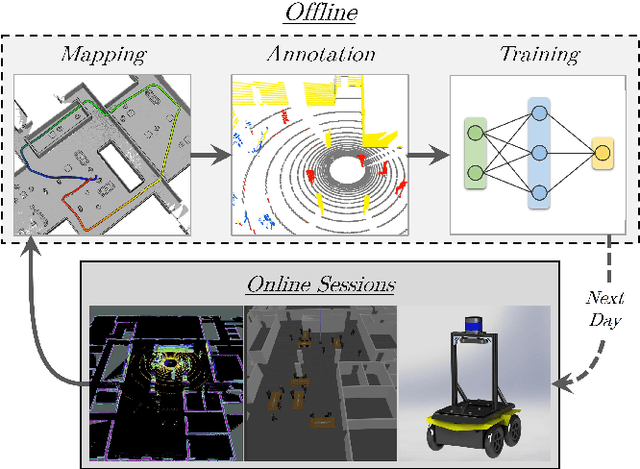
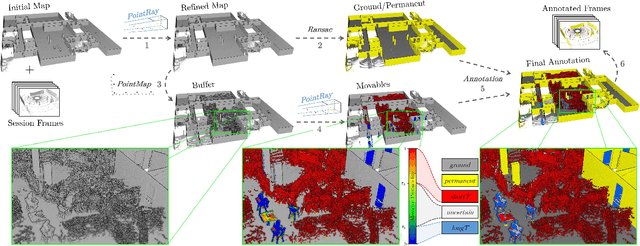
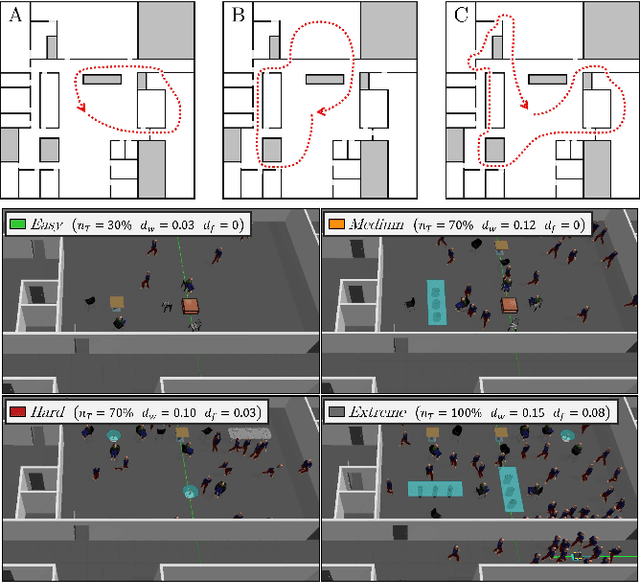
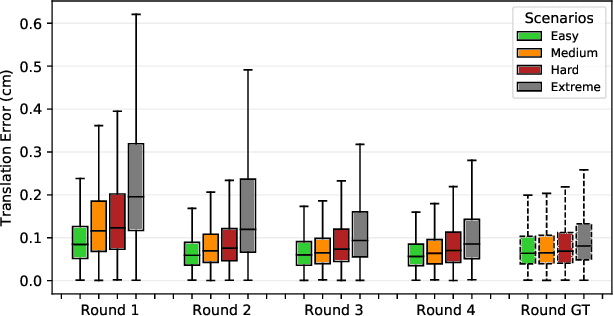
We present a self-supervised learning approach for the semantic segmentation of lidar frames. Our method is used to train a deep point cloud segmentation architecture without any human annotation. The annotation process is automated with the combination of simultaneous localization and mapping (SLAM) and ray-tracing algorithms. By performing multiple navigation sessions in the same environment, we are able to identify permanent structures, such as walls, and disentangle short-term and long-term movable objects, such as people and tables, respectively. New sessions can then be performed using a network trained to predict these semantic labels. We demonstrate the ability of our approach to improve itself over time, from one session to the next. With semantically filtered point clouds, our robot can navigate through more complex scenarios, which, when added to the training pool, help to improve our network predictions. We provide insights into our network predictions and show that our approach can also improve the performances of common localization techniques.
DeepMEL: Compiling Visual Multi-Experience Localization into a Deep Neural Network
Mar 05, 2020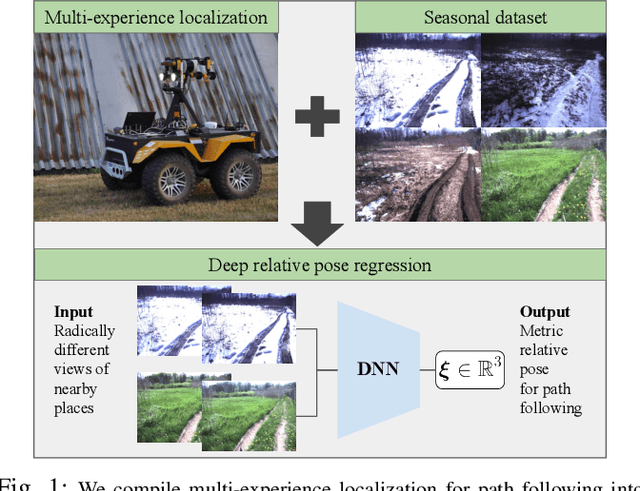
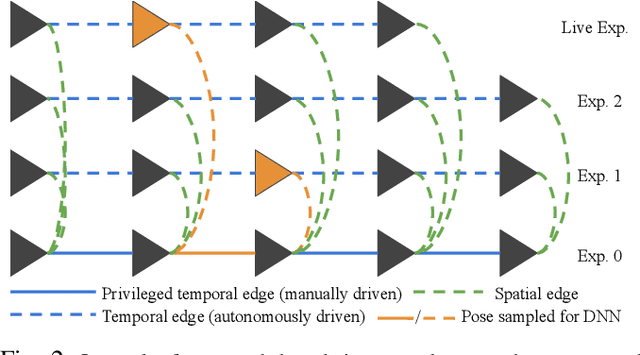
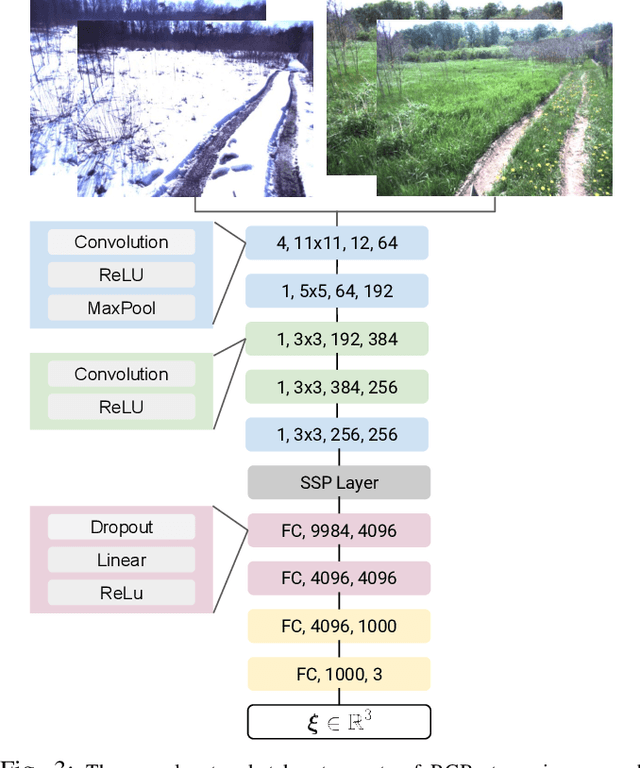

Vision-based path following allows robots to autonomously repeat manually taught paths. Stereo Visual Teach and Repeat (VT\&R) accomplishes accurate and robust long-range path following in unstructured outdoor environments across changing lighting, weather, and seasons by relying on colour-constant imaging and multi-experience localization. We leverage multi-experience VT\&R together with two datasets of outdoor driving on two separate paths spanning different times of day, weather, and seasons to teach a deep neural network to predict relative pose for visual odometry (VO) and for localization with respect to a path. In this paper we run experiments exclusively on datasets to study how the network generalizes across environmental conditions. Based on the results we believe that our system achieves relative pose estimates sufficiently accurate for in-the-loop path following and that it is able to localize radically different conditions against each other directly (i.e. winter to spring and day to night), a capability that our hand-engineered system does not have.
Learning Matchable Colorspace Transformations for Long-term Metric Visual Localization
Apr 01, 2019
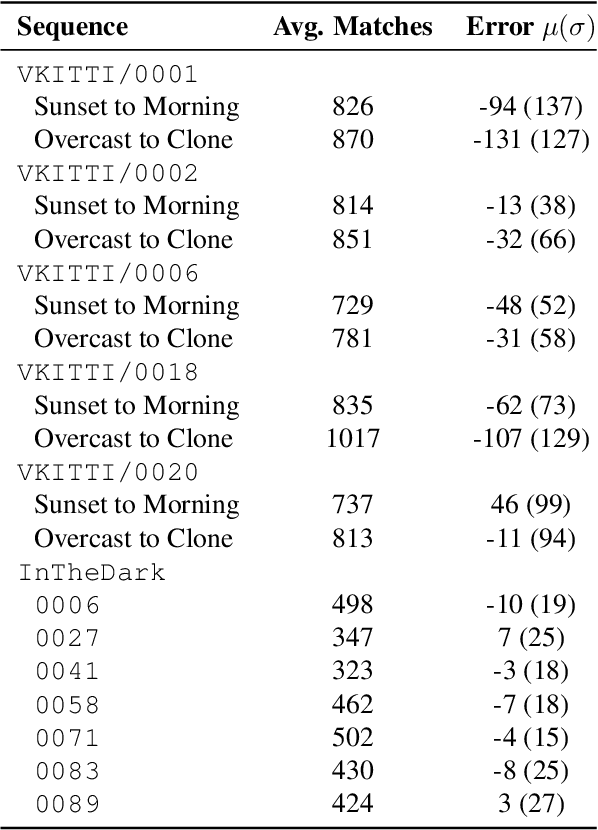
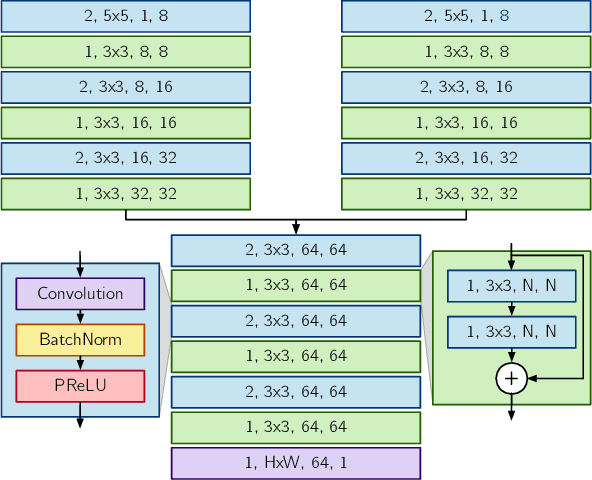
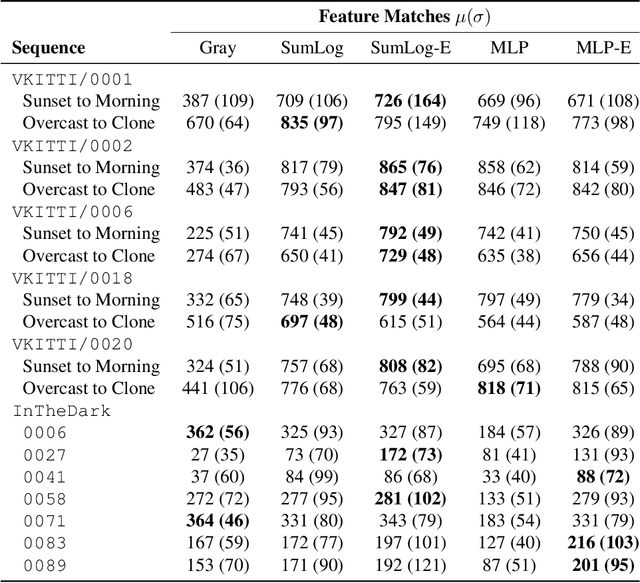
Long-term metric localization is an essential capability of autonomous mobile robots, but remains challenging for vision-based systems in the presence of appearance change caused by lighting, weather or seasonal variations. While experience-based mapping has proven to be an effective technique for enabling visual localization across appearance change, the number of experiences required for reliable long-term localization can be large, and methods for reducing the necessary number of experiences are desired. Taking inspiration from physics-based models of color constancy, we propose a method for learning a nonlinear mapping from RGB to grayscale colorspaces that maximizes the number of feature matches for images captured under varying lighting and weather conditions. Our key insight is that useful image transformations can be learned by approximating conventional non-differentiable localization pipelines with a differentiable learned model that can predict a convenient measure of localization quality, such as the number of feature matches, for a given pair of images. Moreover, we find that the generality of appearance-robust RGB-to-grayscale mappings can be improved by incorporating a learned low-dimensional context feature computed for a specific image pair. Using synthetic and real-world datasets, we show that our method substantially improves feature matching across day-night cycles and presents a viable strategy for significantly improving the efficiency of experience-based visual localization.
Building a Winning Self-Driving Car in Six Months
Nov 03, 2018

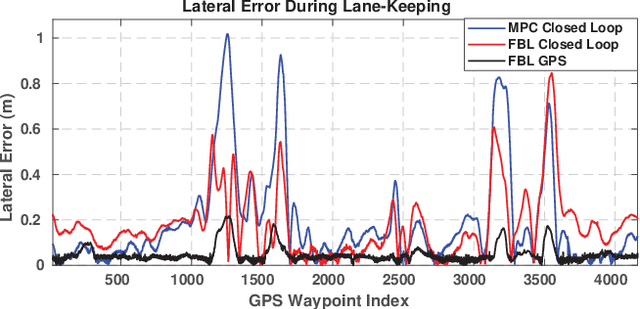
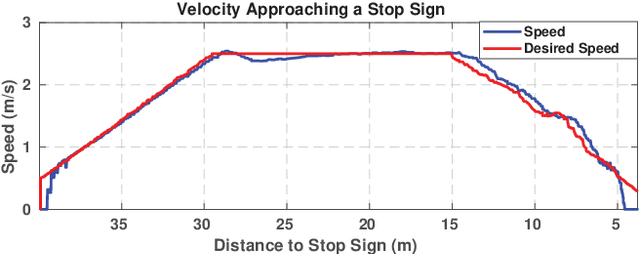
The SAE AutoDrive Challenge is a three-year competition to develop a Level 4 autonomous vehicle by 2020. The first set of challenges were held in April of 2018 in Yuma, Arizona. Our team (aUToronto/Zeus) placed first. In this paper, we describe our complete system architecture and specialized algorithms that enabled us to win. We show that it is possible to develop a vehicle with basic autonomy features in just six months relying on simple, robust algorithms. We do not make use of a prior map. Instead, we have developed a multi-sensor visual localization solution. All of our algorithms run in real-time using CPUs only. We also highlight the closed-loop performance of our system in detail in several experiments.