 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Matchable Colorspace Transformations for Long-term Metric Visual Localization
Apr 01, 2019
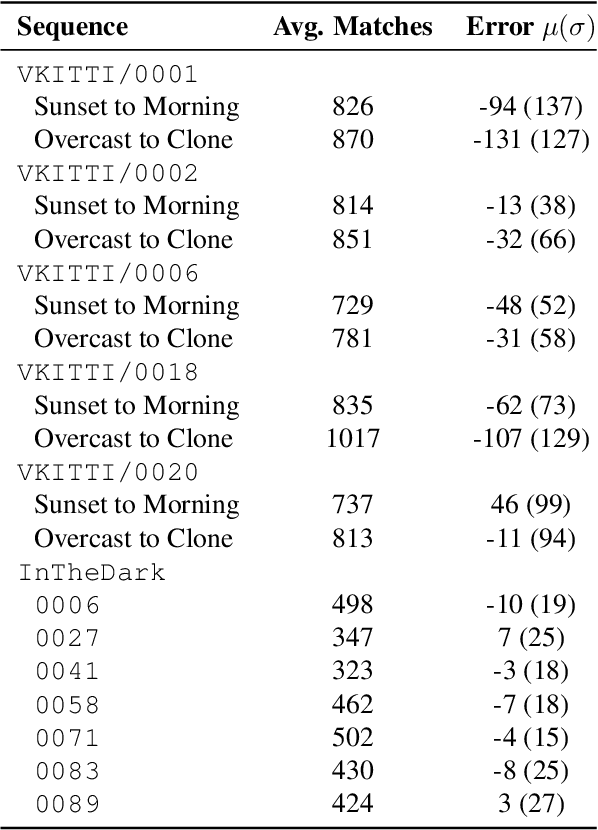
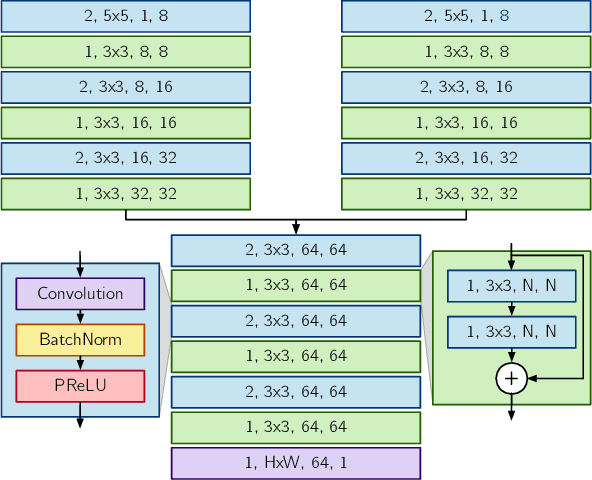
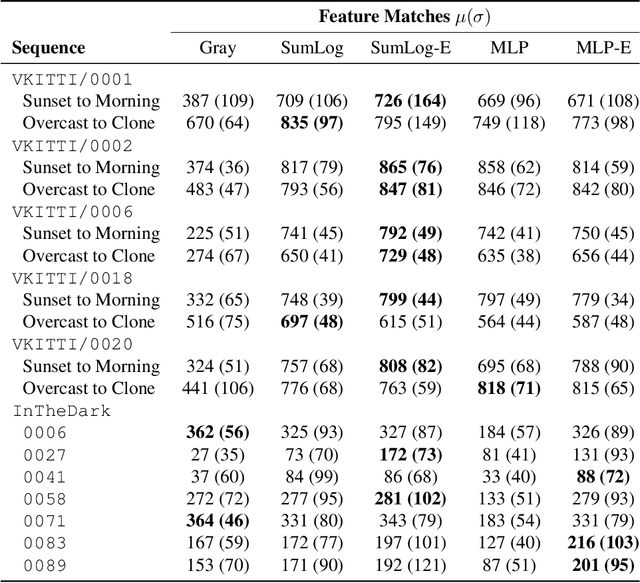
Long-term metric localization is an essential capability of autonomous mobile robots, but remains challenging for vision-based systems in the presence of appearance change caused by lighting, weather or seasonal variations. While experience-based mapping has proven to be an effective technique for enabling visual localization across appearance change, the number of experiences required for reliable long-term localization can be large, and methods for reducing the necessary number of experiences are desired. Taking inspiration from physics-based models of color constancy, we propose a method for learning a nonlinear mapping from RGB to grayscale colorspaces that maximizes the number of feature matches for images captured under varying lighting and weather conditions. Our key insight is that useful image transformations can be learned by approximating conventional non-differentiable localization pipelines with a differentiable learned model that can predict a convenient measure of localization quality, such as the number of feature matches, for a given pair of images. Moreover, we find that the generality of appearance-robust RGB-to-grayscale mappings can be improved by incorporating a learned low-dimensional context feature computed for a specific image pair. Using synthetic and real-world datasets, we show that our method substantially improves feature matching across day-night cycles and presents a viable strategy for significantly improving the efficiency of experience-based visual localization.
How to Train a CAT: Learning Canonical Appearance Transformations for Direct Visual Localization Under Illumination Change
Sep 11, 2018



Direct visual localization has recently enjoyed a resurgence in popularity with the increasing availability of cheap mobile computing power. The competitive accuracy and robustness of these algorithms compared to state-of-the-art feature-based methods, as well as their natural ability to yield dense maps, makes them an appealing choice for a variety of mobile robotics applications. However, direct methods remain brittle in the face of appearance change due to their underlying assumption of photometric consistency, which is commonly violated in practice. In this paper, we propose to mitigate this problem by training deep convolutional encoder-decoder models to transform images of a scene such that they correspond to a previously-seen canonical appearance. We validate our method in multiple environments and illumination conditions using high-fidelity synthetic RGB-D datasets, and integrate the trained models into a direct visual localization pipeline, yielding improvements in visual odometry (VO) accuracy through time-varying illumination conditions, as well as improved metric relocalization performance under illumination change, where conventional methods normally fail. We further provide a preliminary investigation of transfer learning from synthetic to real environments in a localization context. An open-source implementation of our method using PyTorch is available at https://github.com/utiasSTARS/cat-net.
Entropy-Based $Sim$ Calibration of 2D Lidars to Egomotion Sensors
Jul 13, 2018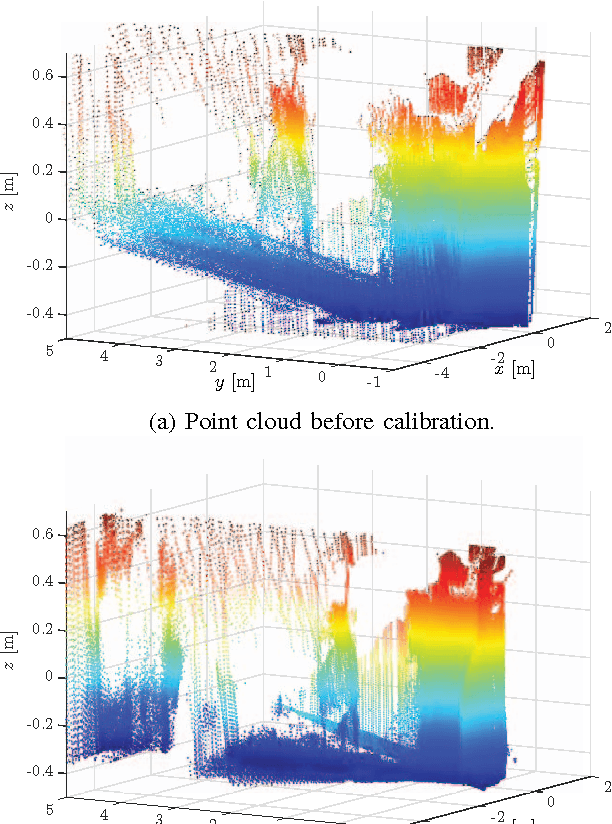
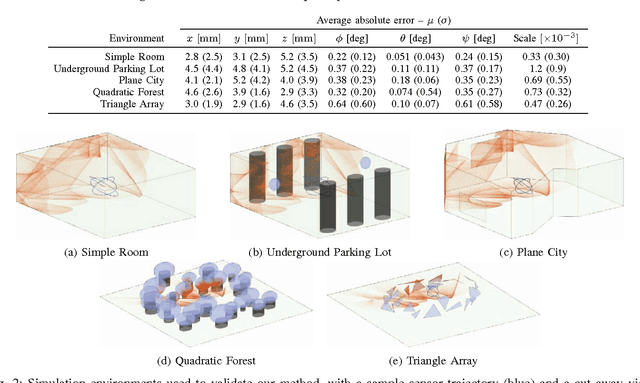
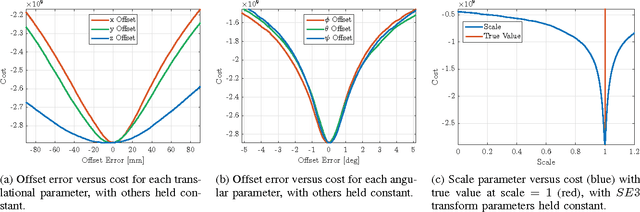
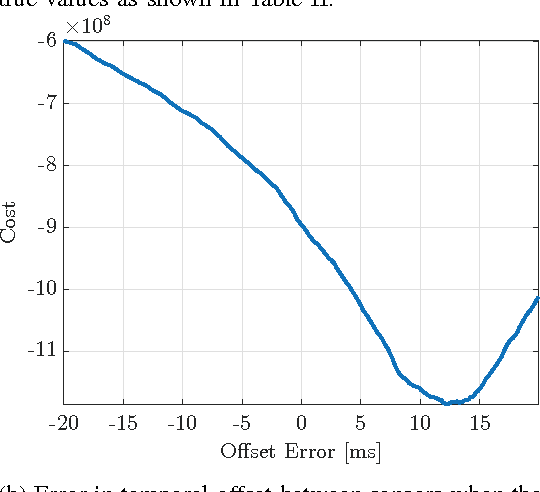
This paper explores the use of an entropy-based technique for point cloud reconstruction with the goal of calibrating a lidar to a sensor capable of providing egomotion information. We extend recent work in this area to the problem of recovering the $Sim(3)$ transformation between a 2D lidar and a rigidly attached monocular camera, where the scale of the camera trajectory is not known a priori. We demonstrate the robustness of our approach on realistic simulations in multiple environments, as well as on data collected from a hand-held sensor rig. Given a non-degenerate trajectory and a sufficient number of lidar measurements, our calibration procedure achieves millimetre-scale and sub-degree accuracy. Moreover, our method relaxes the need for specific scene geometry, fiducial markers, or overlapping sensor fields of view, which had previously limited similar techniques.
PROBE: Predictive Robust Estimation for Visual-Inertial Navigation
Aug 02, 2017


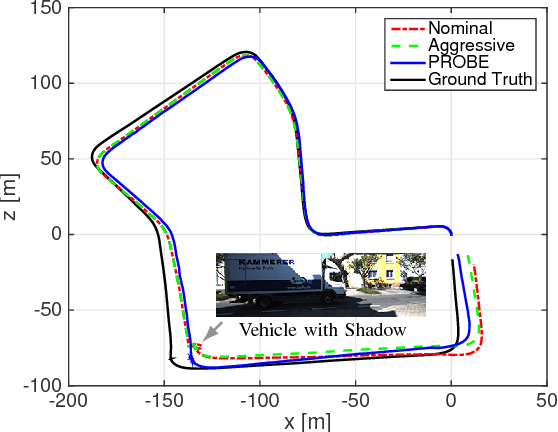
Navigation in unknown, chaotic environments continues to present a significant challenge for the robotics community. Lighting changes, self-similar textures, motion blur, and moving objects are all considerable stumbling blocks for state-of-the-art vision-based navigation algorithms. In this paper we present a novel technique for improving localization accuracy within a visual-inertial navigation system (VINS). We make use of training data to learn a model for the quality of visual features with respect to localization error in a given environment. This model maps each visual observation from a predefined prediction space of visual-inertial predictors onto a scalar weight, which is then used to scale the observation covariance matrix. In this way, our model can adjust the influence of each observation according to its quality. We discuss our choice of predictors and report substantial reductions in localization error on 4 km of data from the KITTI dataset, as well as on experimental datasets consisting of 700 m of indoor and outdoor driving on a small ground rover equipped with a Skybotix VI-Sensor.
Reducing Drift in Visual Odometry by Inferring Sun Direction Using a Bayesian Convolutional Neural Network
Jul 28, 2017



We present a method to incorporate global orientation information from the sun into a visual odometry pipeline using only the existing image stream, where the sun is typically not visible. We leverage recent advances in Bayesian Convolutional Neural Networks to train and implement a sun detection model that infers a three-dimensional sun direction vector from a single RGB image. Crucially, our method also computes a principled uncertainty associated with each prediction, using a Monte Carlo dropout scheme. We incorporate this uncertainty into a sliding window stereo visual odometry pipeline where accurate uncertainty estimates are critical for optimal data fusion. Our Bayesian sun detection model achieves a median error of approximately 12 degrees on the KITTI odometry benchmark training set, and yields improvements of up to 42% in translational ARMSE and 32% in rotational ARMSE compared to standard VO. An open source implementation of our Bayesian CNN sun estimator (Sun-BCNN) using Caffe is available at https://github. com/utiasSTARS/sun-bcnn-vo
Improving the Accuracy of Stereo Visual Odometry Using Visual Illumination Estimation
Jul 27, 2017

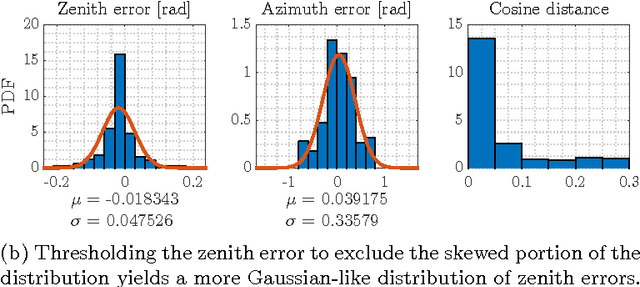

In the absence of reliable and accurate GPS, visual odometry (VO) has emerged as an effective means of estimating the egomotion of robotic vehicles. Like any dead-reckoning technique, VO suffers from unbounded accumulation of drift error over time, but this accumulation can be limited by incorporating absolute orientation information from, for example, a sun sensor. In this paper, we leverage recent work on visual outdoor illumination estimation to show that estimation error in a stereo VO pipeline can be reduced by inferring the sun position from the same image stream used to compute VO, thereby gaining the benefits of sun sensing without requiring a dedicated sun sensor or the sun to be visible to the camera. We compare sun estimation methods based on hand-crafted visual cues and Convolutional Neural Networks (CNNs) and demonstrate our approach on a combined 7.8 km of urban driving from the popular KITTI dataset, achieving up to a 43% reduction in translational average root mean squared error (ARMSE) and a 59% reduction in final translational drift error compared to pure VO alone.
Monocular Visual Teach and Repeat Aided by Local Ground Planarity
Jul 27, 2017



Visual Teach and Repeat (VT\&R) allows an autonomous vehicle to repeat a previously traversed route without a global positioning system. Existing implementations of VT\&R typically rely on 3D sensors such as stereo cameras for mapping and localization, but many mobile robots are equipped with only 2D monocular vision for tasks such as teleoperated bomb disposal. While simultaneous localization and mapping (SLAM) algorithms exist that can recover 3D structure and motion from monocular images, the scale ambiguity inherent in these methods complicates the estimation and control of lateral path-tracking error, which is essential for achieving high-accuracy path following. In this paper, we propose a monocular vision pipeline that enables kilometre-scale route repetition with centimetre-level accuracy by approximating the ground surface near the vehicle as planar (with some uncertainty) and recovering absolute scale from the known position and orientation of the camera relative to the vehicle. This system provides added value to many existing robots by allowing for high-accuracy autonomous route repetition with a simple software upgrade and no additional sensors. We validate our system over 4.3 km of autonomous navigation and demonstrate accuracy on par with the conventional stereo pipeline, even in highly non-planar terrain.