 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlight Testing an Optionally Piloted Aircraft: a Case Study on Trust Dynamics in Human-Autonomy Teaming
Mar 20, 2025

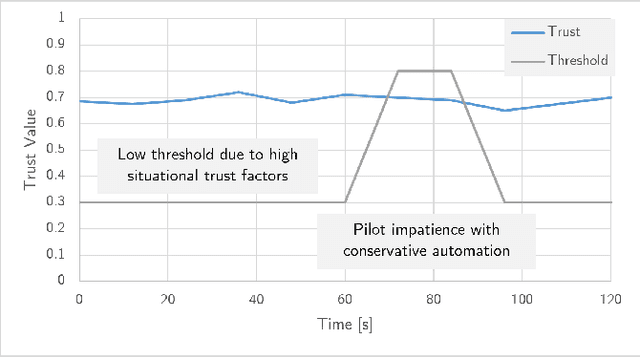
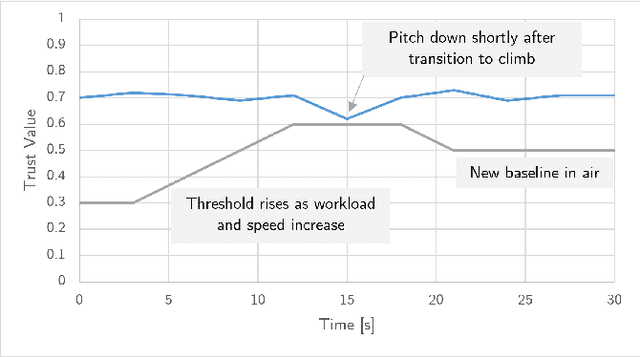
This paper examines how trust is formed, maintained, or diminished over time in the context of human-autonomy teaming with an optionally piloted aircraft. Whereas traditional factor-based trust models offer a static representation of human confidence in technology, here we discuss how variations in the underlying factors lead to variations in trust, trust thresholds, and human behaviours. Over 200 hours of flight test data collected over a multi-year test campaign from 2021 to 2023 were reviewed. The dispositional-situational-learned, process-performance-purpose, and IMPACTS homeostasis trust models are applied to illuminate trust trends during nominal autonomous flight operations. The results offer promising directions for future studies on trust dynamics and design-for-trust in human-autonomy teaming.
Learned Camera Gain and Exposure Control for Improved Visual Feature Detection and Matching
Feb 28, 2021
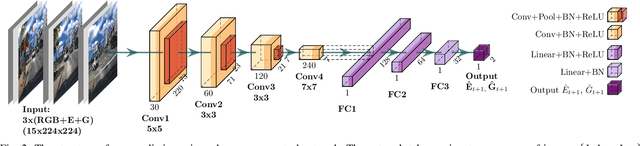


Successful visual navigation depends upon capturing images that contain sufficient useful information. In this paper, we explore a data-driven approach to account for environmental lighting changes, improving the quality of images for use in visual odometry (VO) or visual simultaneous localization and mapping (SLAM). We train a deep convolutional neural network model to predictively adjust camera gain and exposure time parameters such that consecutive images contain a maximal number of matchable features. The training process is fully self-supervised: our training signal is derived from an underlying VO or SLAM pipeline and, as a result, the model is optimized to perform well with that specific pipeline. We demonstrate through extensive real-world experiments that our network can anticipate and compensate for dramatic lighting changes (e.g., transitions into and out of road tunnels), maintaining a substantially higher number of inlier feature matches than competing camera parameter control algorithms.
Learning Matchable Colorspace Transformations for Long-term Metric Visual Localization
Apr 01, 2019
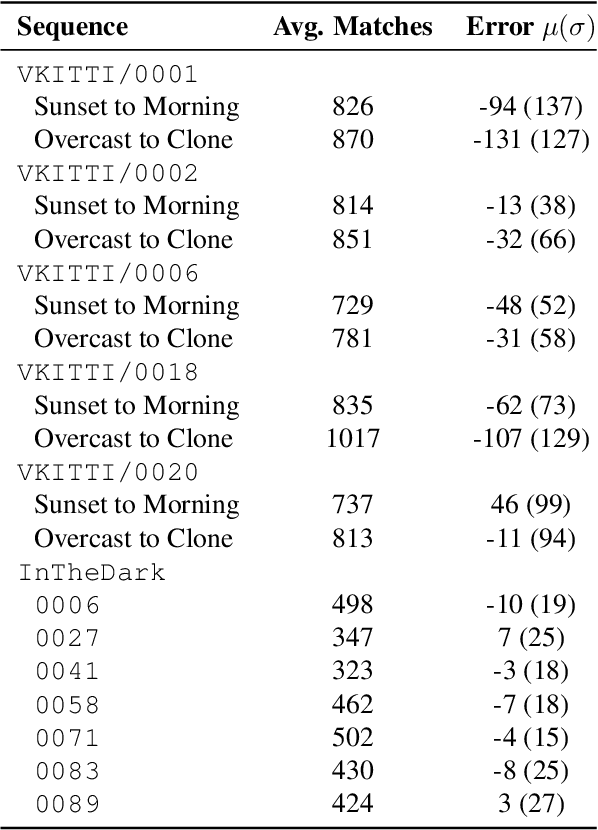
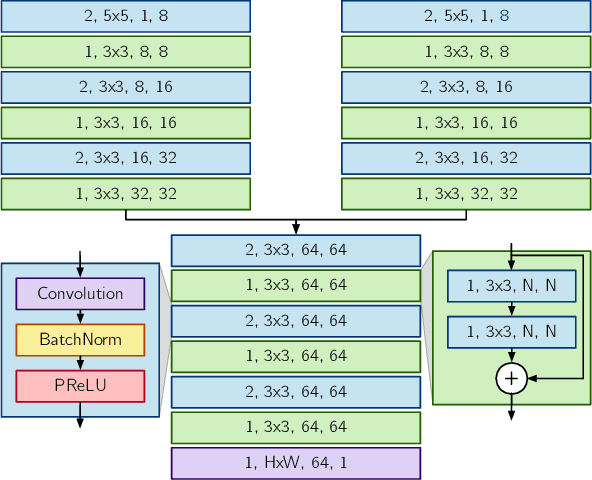
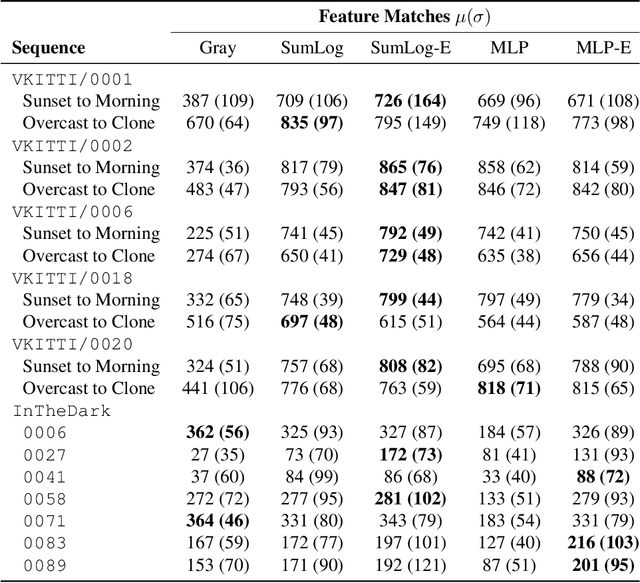
Long-term metric localization is an essential capability of autonomous mobile robots, but remains challenging for vision-based systems in the presence of appearance change caused by lighting, weather or seasonal variations. While experience-based mapping has proven to be an effective technique for enabling visual localization across appearance change, the number of experiences required for reliable long-term localization can be large, and methods for reducing the necessary number of experiences are desired. Taking inspiration from physics-based models of color constancy, we propose a method for learning a nonlinear mapping from RGB to grayscale colorspaces that maximizes the number of feature matches for images captured under varying lighting and weather conditions. Our key insight is that useful image transformations can be learned by approximating conventional non-differentiable localization pipelines with a differentiable learned model that can predict a convenient measure of localization quality, such as the number of feature matches, for a given pair of images. Moreover, we find that the generality of appearance-robust RGB-to-grayscale mappings can be improved by incorporating a learned low-dimensional context feature computed for a specific image pair. Using synthetic and real-world datasets, we show that our method substantially improves feature matching across day-night cycles and presents a viable strategy for significantly improving the efficiency of experience-based visual localization.