 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Camera Gain and Exposure Control for Improved Visual Feature Detection and Matching
Paper and Code
Feb 28, 2021
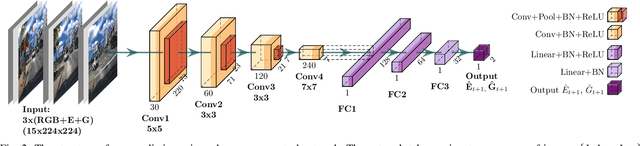


Successful visual navigation depends upon capturing images that contain sufficient useful information. In this paper, we explore a data-driven approach to account for environmental lighting changes, improving the quality of images for use in visual odometry (VO) or visual simultaneous localization and mapping (SLAM). We train a deep convolutional neural network model to predictively adjust camera gain and exposure time parameters such that consecutive images contain a maximal number of matchable features. The training process is fully self-supervised: our training signal is derived from an underlying VO or SLAM pipeline and, as a result, the model is optimized to perform well with that specific pipeline. We demonstrate through extensive real-world experiments that our network can anticipate and compensate for dramatic lighting changes (e.g., transitions into and out of road tunnels), maintaining a substantially higher number of inlier feature matches than competing camera parameter control algorithms.