 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Self-Supervised Pre-Training of Point Cloud Segmentation Networks With Image Data
Jan 18, 2023



Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is particularly important for semantic segmentation tasks involving 3D datasets, which are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on unlabelled data is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point clouds exclusively. While useful, this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene and can be applied to cases where localization information is unavailable. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Dec 13, 2022


Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
A Self-Supervised, Differentiable Kalman Filter for Uncertainty-Aware Visual-Inertial Odometry
Mar 14, 2022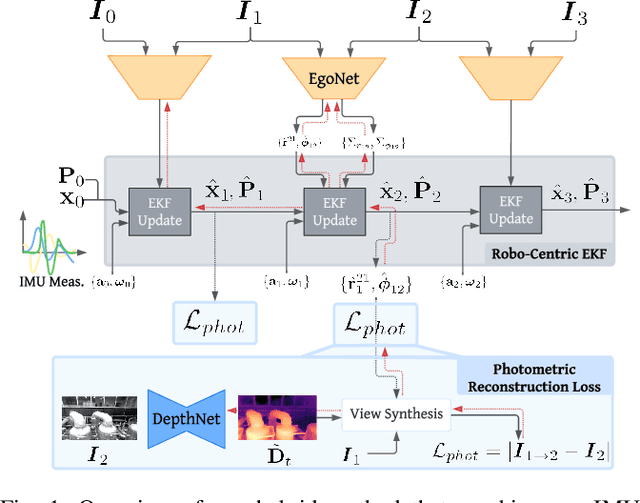
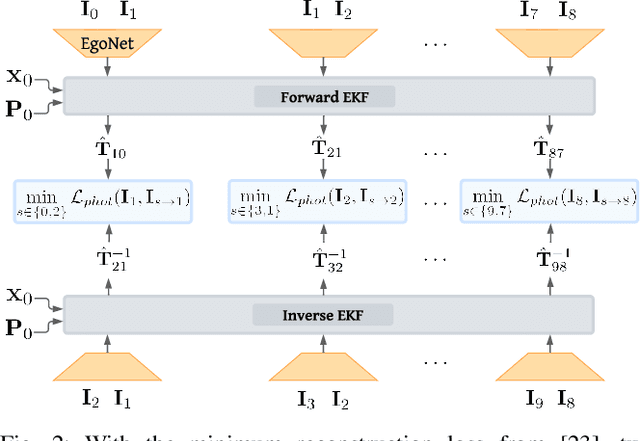
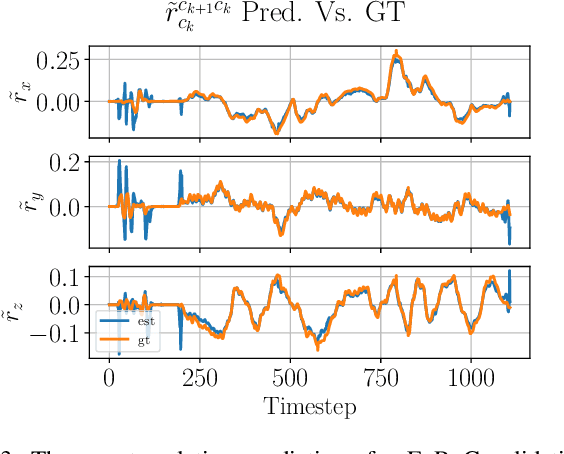

Traditionally, visual-inertial-odometry (VIO) systems rely on filtering or optimization-based frameworks for robot egomotion estimation. While these methods are accurate under nominal conditions, they are prone to failure in degraded environments, where illumination changes, fast camera motion, or textureless scenes are present. Learning-based systems have the potential to outperform classical implementations in degraded environments, but are, currently, less accurate than classical methods in nominal settings. A third class, of hybrid systems, attempts to leverage the advantages of both systems. Herein, we introduce a framework for training a hybrid VIO system. Our approach uses a differentiable Kalman filter with an IMU-based process model and a robust, neural network-based relative pose measurement model. By utilizing the data efficiency of self-supervised learning, we show that our system significantly outperforms a similar, supervised system, while enabling online retraining. To demonstrate the utility of our approach, we evaluate our system on a visually degraded version of the EuRoC dataset. Notably, we find that, in cases where classical estimators consistently diverge, our estimator does not diverge or suffer from a significant reduction in accuracy. Finally, our system, by properly utilizing the metric information contained in the IMU measurements, is able to recover metric scale, while other self-supervised monocular VIO approaches cannot.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021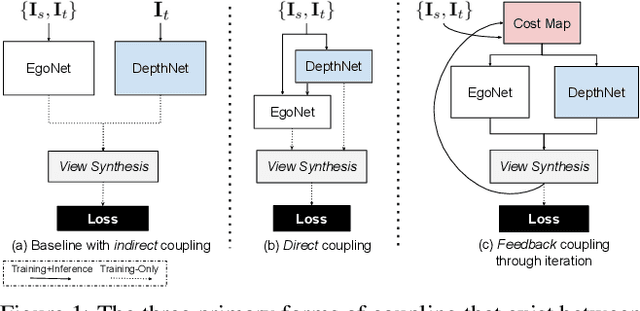

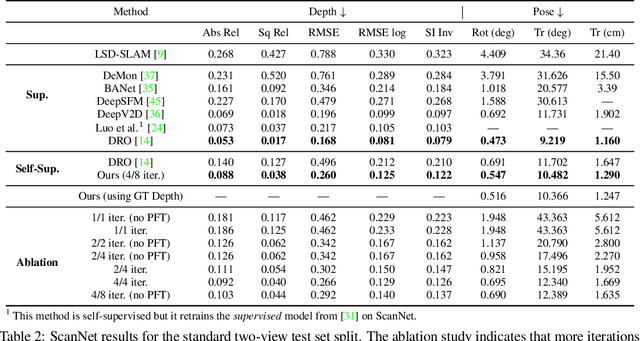

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
Learned Camera Gain and Exposure Control for Improved Visual Feature Detection and Matching
Feb 28, 2021
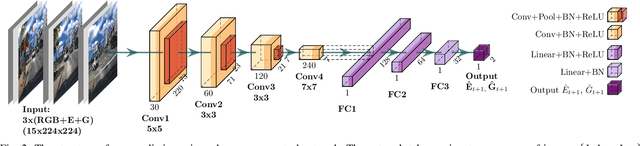


Successful visual navigation depends upon capturing images that contain sufficient useful information. In this paper, we explore a data-driven approach to account for environmental lighting changes, improving the quality of images for use in visual odometry (VO) or visual simultaneous localization and mapping (SLAM). We train a deep convolutional neural network model to predictively adjust camera gain and exposure time parameters such that consecutive images contain a maximal number of matchable features. The training process is fully self-supervised: our training signal is derived from an underlying VO or SLAM pipeline and, as a result, the model is optimized to perform well with that specific pipeline. We demonstrate through extensive real-world experiments that our network can anticipate and compensate for dramatic lighting changes (e.g., transitions into and out of road tunnels), maintaining a substantially higher number of inlier feature matches than competing camera parameter control algorithms.
Self-Supervised Scale Recovery for Monocular Depth and Egomotion Estimation
Sep 09, 2020

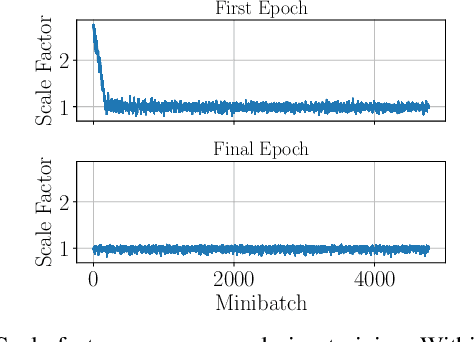
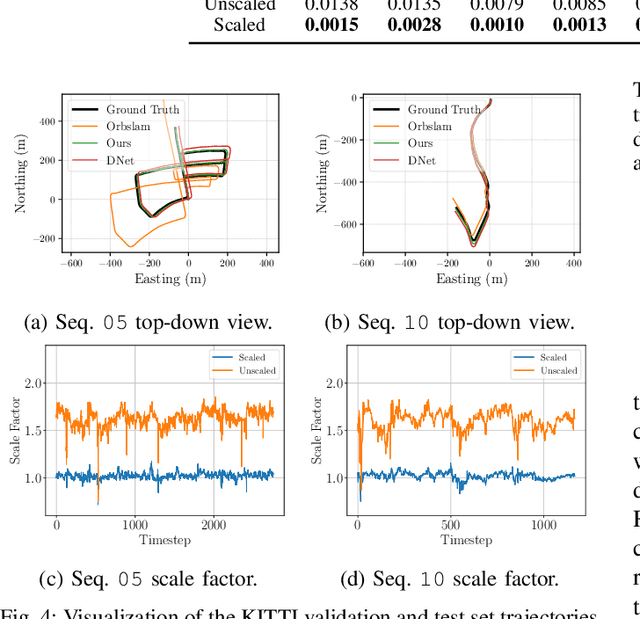
The self-supervised loss formulation for jointly training depth and egomotion neural networks with monocular images is well studied and has demonstrated state-of-the-art accuracy. One of the main limitations of this approach, however, is that the depth and egomotion estimates are only determined up to an unknown scale. In this paper, we present a novel scale recovery loss that enforces consistency between a known camera height and the estimated camera height, generating metric (scaled) depth and egomotion predictions. We show that our proposed method is competitive with other scale recovery techniques (i.e., pose supervision and stereo left/right consistency constraints). Further, we demonstrate how our method facilitates network retraining within new environments, whereas other scale-resolving approaches are incapable of doing so. Notably, our egomotion network is able to produce more accurate estimates than a similar method that only recovers scale at test time.
Heteroscedastic Uncertainty for Robust Generative Latent Dynamics
Aug 18, 2020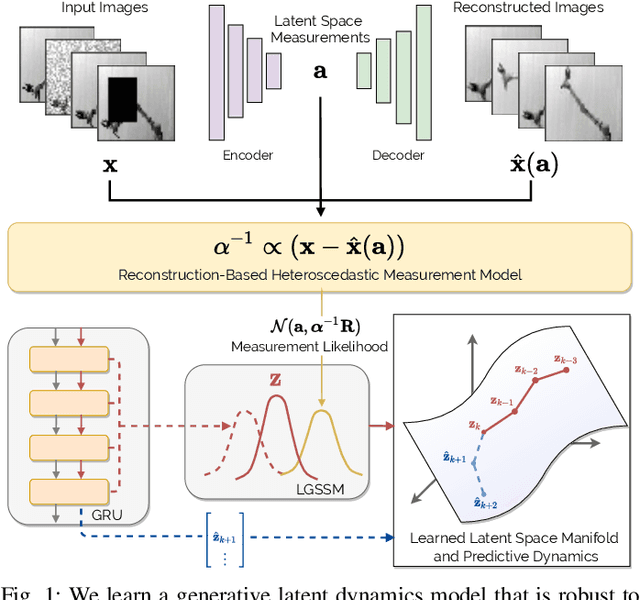
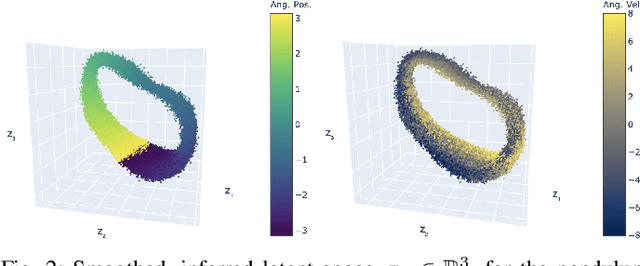
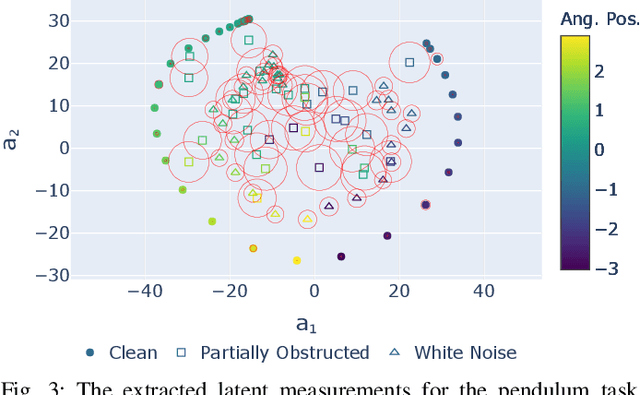
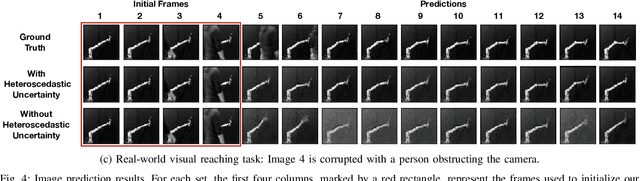
Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.
Self-Supervised Deep Pose Corrections for Robust Visual Odometry
Feb 27, 2020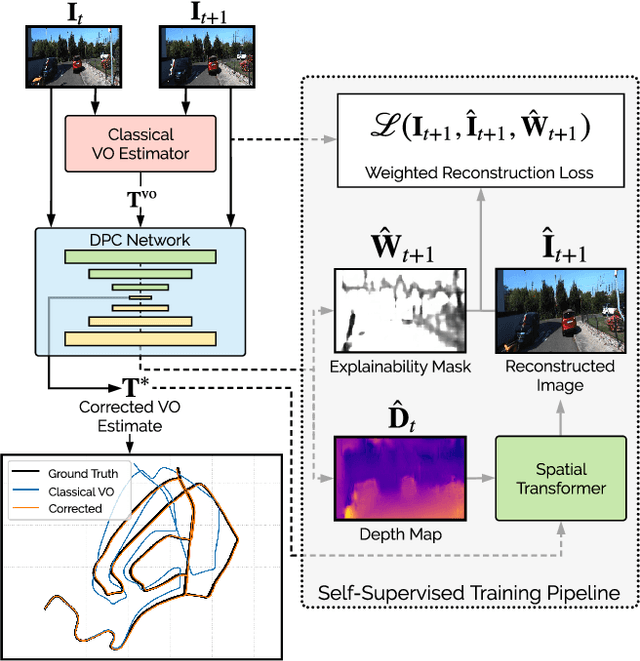

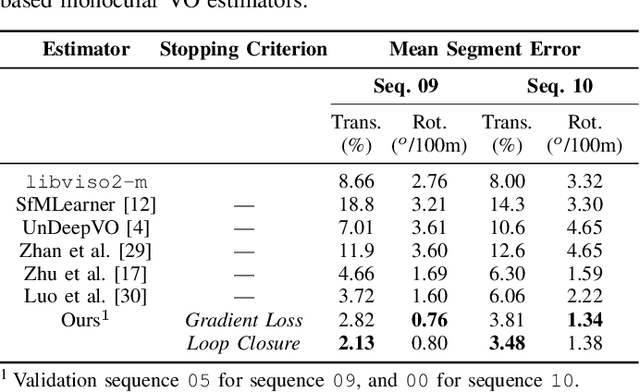

We present a self-supervised deep pose correction (DPC) network that applies pose corrections to a visual odometry estimator to improve its accuracy. Instead of regressing inter-frame pose changes directly, we build on prior work that uses data-driven learning to regress pose corrections that account for systematic errors due to violations of modelling assumptions. Our self-supervised formulation removes any requirement for six-degrees-of-freedom ground truth and, in contrast to expectations, often improves overall navigation accuracy compared to a supervised approach. Through extensive experiments, we show that our self-supervised DPC network can significantly enhance the performance of classical monocular and stereo odometry estimators and substantially out-performs state-of-the-art learning-only approaches.
Robust Data-Driven Zero-Velocity Detection for Foot-Mounted Inertial Navigation
Oct 25, 2019


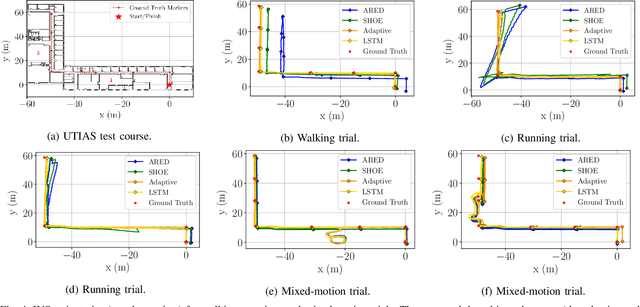
We present two novel techniques for detecting zero-velocity events to improve foot-mounted inertial navigation. Our first technique augments a classical zero-velocity detector by incorporating a motion classifier that adaptively updates the detector's threshold parameter. Our second technique uses a long short-term memory (LSTM) recurrent neural network to classify zero-velocity events from raw inertial data, in contrast to the majority of zero-velocity detection methods that rely on basic statistical hypothesis testing. We demonstrate that both of our proposed detectors achieve higher accuracies than existing detectors for trajectories including walking, running, and stair-climbing motions. Additionally, we present a straightforward data augmentation method that is able to extend the LSTM-based model to different inertial sensors without the need to collect new training data.
Probabilistic Regression of Rotations using Quaternion Averaging and a Deep Multi-Headed Network
Apr 01, 2019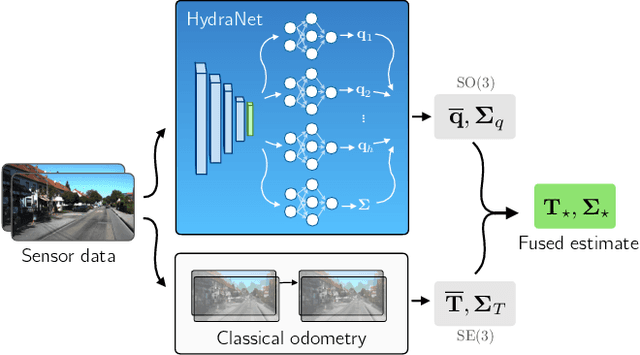

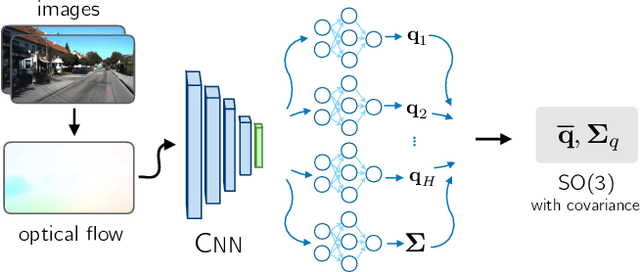
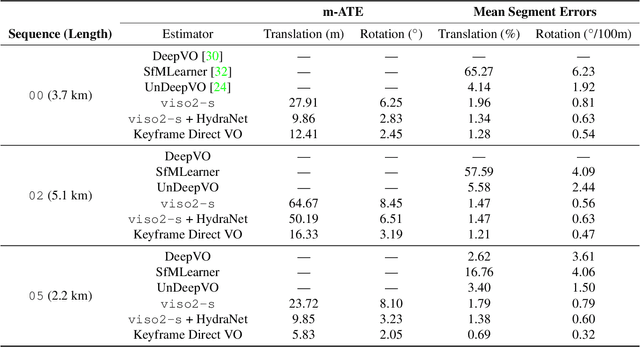
Accurate estimates of rotation are crucial to vision-based motion estimation in augmented reality and robotics. In this work, we present a method to extract probabilistic estimates of rotation from deep regression models. First, we build on prior work and argue that a multi-headed network structure we name HydraNet provides better calibrated uncertainty estimates than methods that rely on stochastic forward passes. Second, we extend HydraNet to targets that belong to the rotation group, SO(3), by regressing unit quaternions and using the tools of rotation averaging and uncertainty injection onto the manifold to produce three-dimensional covariances. Finally, we present results and analysis on a synthetic dataset, learn consistent orientation estimates on the 7-Scenes dataset, and show how we can use our learned covariances to fuse deep estimates of relative orientation with classical stereo visual odometry to improve localization on the KITTI dataset.