 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Scale Recovery for Monocular Depth and Egomotion Estimation
Paper and Code


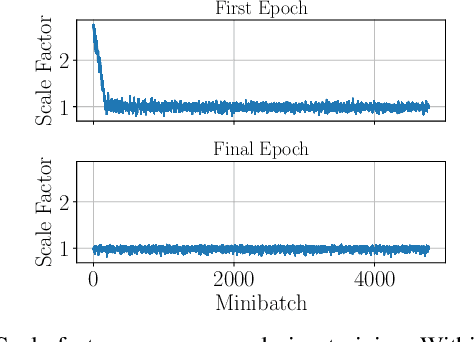
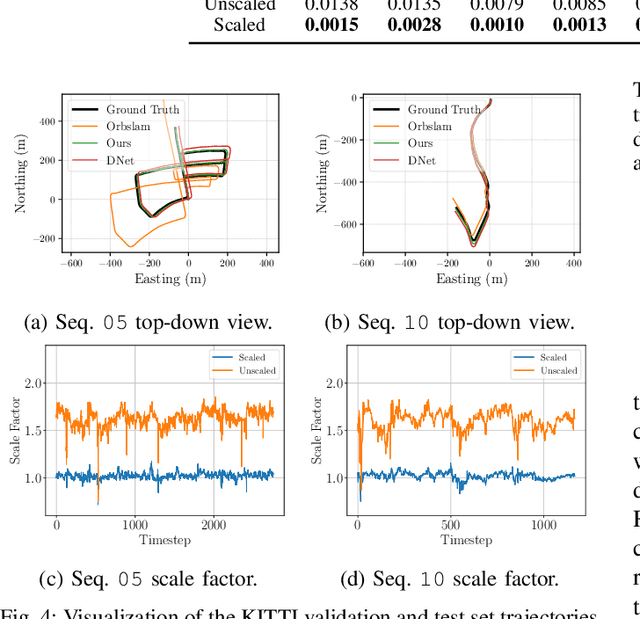
The self-supervised loss formulation for jointly training depth and egomotion neural networks with monocular images is well studied and has demonstrated state-of-the-art accuracy. One of the main limitations of this approach, however, is that the depth and egomotion estimates are only determined up to an unknown scale. In this paper, we present a novel scale recovery loss that enforces consistency between a known camera height and the estimated camera height, generating metric (scaled) depth and egomotion predictions. We show that our proposed method is competitive with other scale recovery techniques (i.e., pose supervision and stereo left/right consistency constraints). Further, we demonstrate how our method facilitates network retraining within new environments, whereas other scale-resolving approaches are incapable of doing so. Notably, our egomotion network is able to produce more accurate estimates than a similar method that only recovers scale at test time.