 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Paper and Code
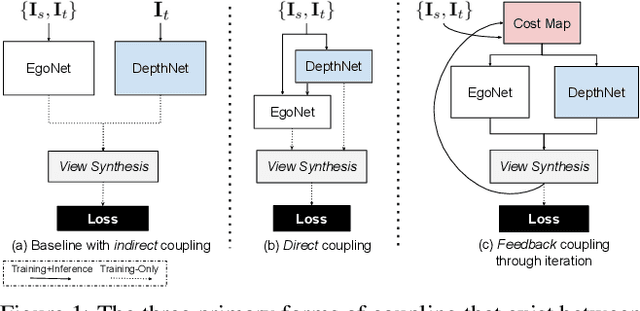

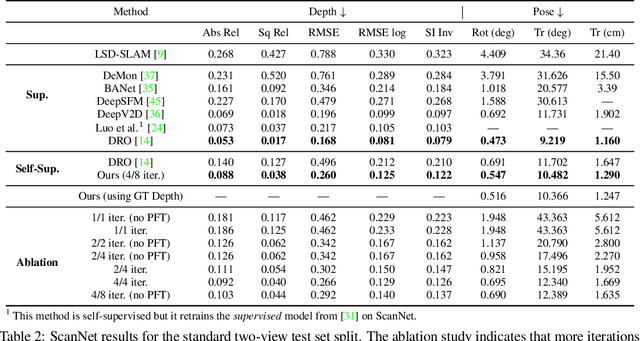

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.