 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoBot: Reference-Guided Interactive Photography via Natural Language
Jan 19, 2024

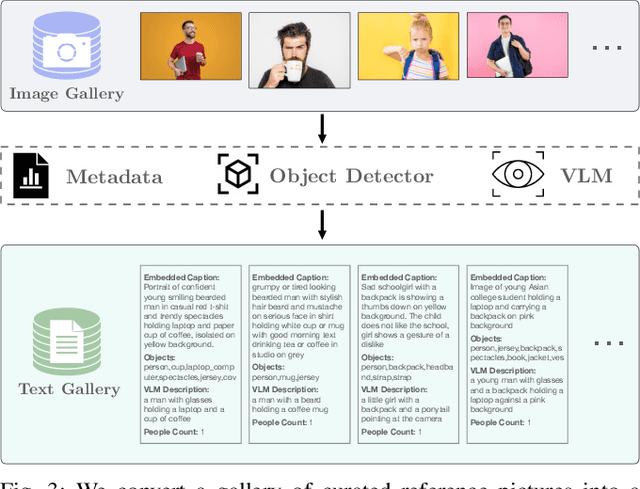

We introduce PhotoBot, a framework for automated photo acquisition based on an interplay between high-level human language guidance and a robot photographer. We propose to communicate photography suggestions to the user via a reference picture that is retrieved from a curated gallery. We exploit a visual language model (VLM) and an object detector to characterize reference pictures via textual descriptions and use a large language model (LLM) to retrieve relevant reference pictures based on a user's language query through text-based reasoning. To correspond the reference picture and the observed scene, we exploit pre-trained features from a vision transformer capable of capturing semantic similarity across significantly varying images. Using these features, we compute pose adjustments for an RGB-D camera by solving a Perspective-n-Point (PnP) problem. We demonstrate our approach on a real-world manipulator equipped with a wrist camera. Our user studies show that photos taken by PhotoBot are often more aesthetically pleasing than those taken by users themselves, as measured by human feedback.
Working Backwards: Learning to Place by Picking
Dec 04, 2023



We present Learning to Place by Picking (LPP), a method capable of autonomously collecting demonstrations for a family of placing tasks in which objects must be manipulated to specific locations. With LPP, we approach the learning of robotic object placement policies by reversing the grasping process and exploiting the inherent symmetry of the pick and place problems. Specifically, we obtain placing demonstrations from a set of grasp sequences of objects that are initially located at their target placement locations. Our system is capable of collecting hundreds of demonstrations without human intervention by using a combination of tactile sensing and compliant control for grasps. We train a policy directly from visual observations through behaviour cloning, using the autonomously-collected demonstrations. By doing so, the policy can generalize to object placement scenarios outside of the training environment without privileged information (e.g., placing a plate picked up from a table and not at the original placement location). We validate our approach on home robotic scenarios that include dishwasher loading and table setting. Our approach yields robotic placing policies that outperform policies trained with kinesthetic teaching, both in terms of performance and data efficiency, while requiring no human supervision.
Push it to the Demonstrated Limit: Multimodal Visuotactile Imitation Learning with Force Matching
Nov 02, 2023
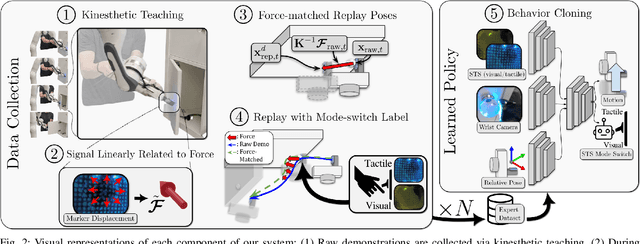
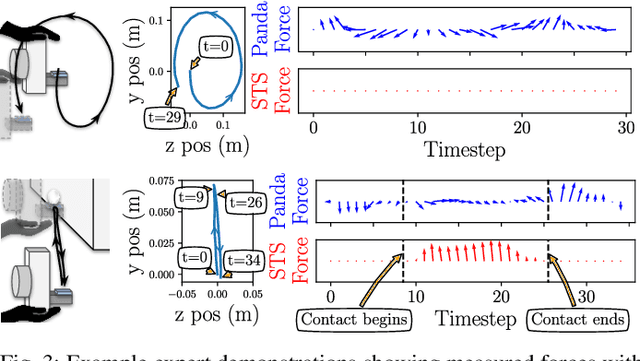
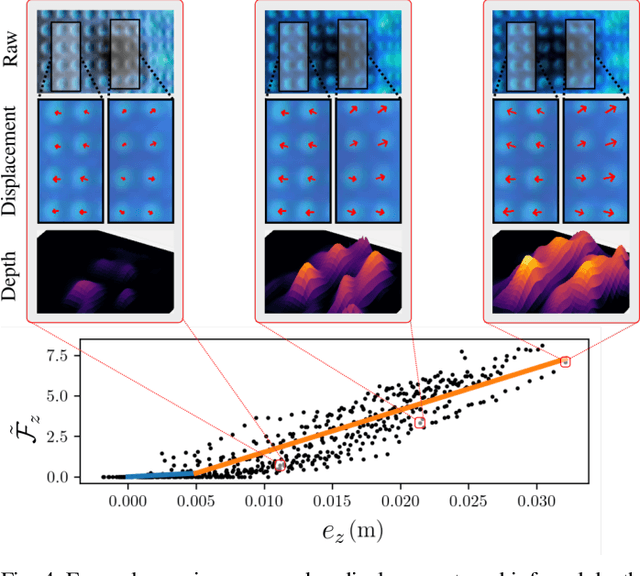
Optical tactile sensors have emerged as an effective means to acquire dense contact information during robotic manipulation. A recently-introduced `see-through-your-skin' (STS) variant of this type of sensor has both visual and tactile modes, enabled by leveraging a semi-transparent surface and controllable lighting. In this work, we investigate the benefits of pairing visuotactile sensing with imitation learning for contact-rich manipulation tasks. First, we use tactile force measurements and a novel algorithm during kinesthetic teaching to yield a force profile that better matches that of the human demonstrator. Second, we add visual/tactile STS mode switching as a control policy output, simplifying the application of the sensor. Finally, we study multiple observation configurations to compare and contrast the value of visual/tactile data (both with and without mode switching) with visual data from a wrist-mounted eye-in-hand camera. We perform an extensive series of experiments on a real robotic manipulator with door-opening and closing tasks, including over 3,000 real test episodes. Our results highlight the importance of tactile sensing for imitation learning, both for data collection to allow force matching, and for policy execution to allow accurate task feedback.
Euclidean Equivariant Models for Generative Graphical Inverse Kinematics
Jul 04, 2023



Quickly and reliably finding accurate inverse kinematics (IK) solutions remains a challenging problem for robotic manipulation. Existing numerical solvers typically produce a single solution only and rely on local search techniques to minimize a highly nonconvex objective function. Recently, learning-based approaches that approximate the entire feasible set of solutions have shown promise as a means to generate multiple fast and accurate IK results in parallel. However, existing learning-based techniques have a significant drawback: each robot of interest requires a specialized model that must be trained from scratch. To address this shortcoming, we investigate a novel distance-geometric robot representation coupled with a graph structure that allows us to leverage the flexibility of graph neural networks (GNNs). We use this approach to train a generative graphical inverse kinematics solver (GGIK) that is able to produce a large number of diverse solutions in parallel while also generalizing well -- a single learned model can be used to produce IK solutions for a variety of different robots. The graphical formulation elegantly exposes the symmetry and Euclidean equivariance of the IK problem that stems from the spatial nature of robot manipulators. We exploit this symmetry by encoding it into the architecture of our learned model, yielding a flexible solver that is able to produce sets of IK solutions for multiple robots.
ANSEL Photobot: A Robot Event Photographer with Semantic Intelligence
Feb 15, 2023
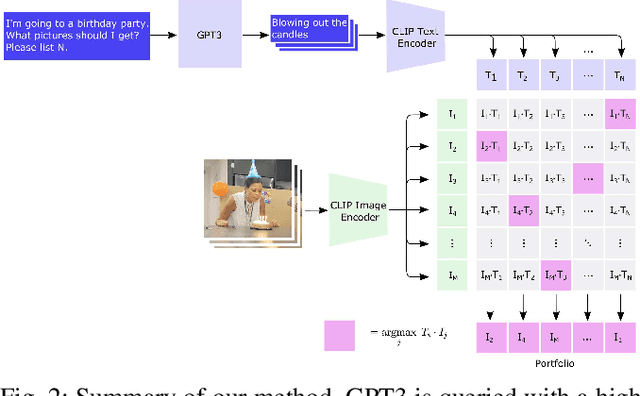

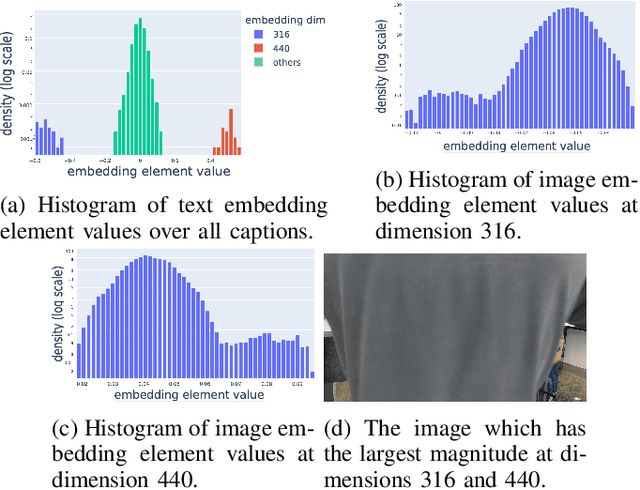
Our work examines the way in which large language models can be used for robotic planning and sampling, specifically the context of automated photographic documentation. Specifically, we illustrate how to produce a photo-taking robot with an exceptional level of semantic awareness by leveraging recent advances in general purpose language (LM) and vision-language (VLM) models. Given a high-level description of an event we use an LM to generate a natural-language list of photo descriptions that one would expect a photographer to capture at the event. We then use a VLM to identify the best matches to these descriptions in the robot's video stream. The photo portfolios generated by our method are consistently rated as more appropriate to the event by human evaluators than those generated by existing methods.
One Network, Many Robots: Generative Graphical Inverse Kinematics
Sep 22, 2022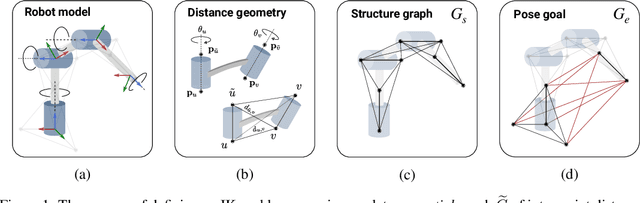
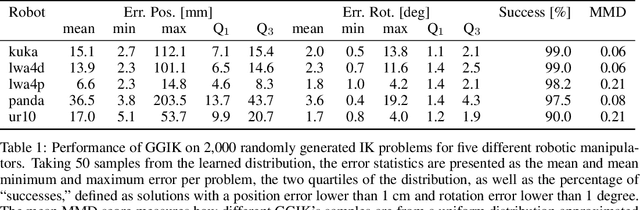
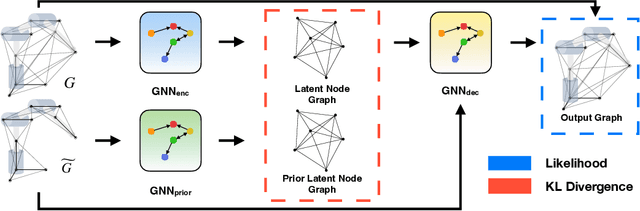

Quickly and reliably finding accurate inverse kinematics (IK) solutions remains a challenging problem for robotic manipulation. Existing numerical solvers are broadly applicable, but rely on local search techniques to manage highly nonconvex objective functions. Recently, learning-based approaches have shown promise as a means to generate fast and accurate IK results; learned solvers can easily be integrated with other learning algorithms in end-to-end systems. However, learning-based methods have an Achilles' heel: each robot of interest requires a specialized model which must be trained from scratch. To address this key shortcoming, we investigate a novel distance-geometric robot representation coupled with a graph structure that allows us to leverage the flexibility of graph neural networks (GNNs). We use this approach to train the first learned generative graphical inverse kinematics (GGIK) solver that is, crucially, "robot-agnostic"-a single model is able to provide IK solutions for a variety of different robots. Additionally, the generative nature of GGIK allows the solver to produce a large number of diverse solutions in parallel with minimal additional computation time, making it appropriate for applications such as sampling-based motion planning. Finally, GGIK can complement local IK solvers by providing reliable initializations. These advantages, as well as the ability to use task-relevant priors and to continuously improve with new data, suggest that GGIK has the potential to be a key component of flexible, learning-based robotic manipulation systems.
Learning Sequential Latent Variable Models from Multimodal Time Series Data
Apr 21, 2022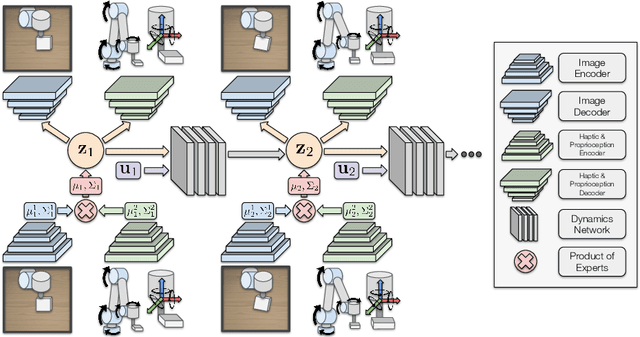

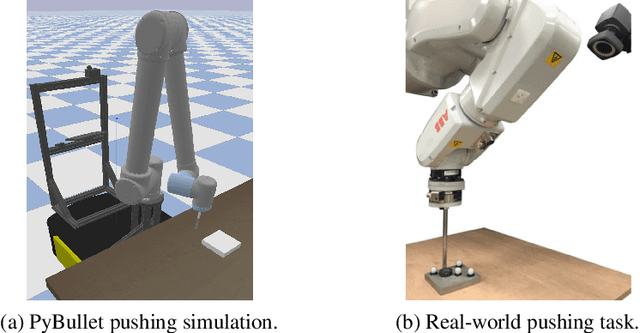

Sequential modelling of high-dimensional data is an important problem that appears in many domains including model-based reinforcement learning and dynamics identification for control. Latent variable models applied to sequential data (i.e., latent dynamics models) have been shown to be a particularly effective probabilistic approach to solve this problem, especially when dealing with images. However, in many application areas (e.g., robotics), information from multiple sensing modalities is available -- existing latent dynamics methods have not yet been extended to effectively make use of such multimodal sequential data. Multimodal sensor streams can be correlated in a useful manner and often contain complementary information across modalities. In this work, we present a self-supervised generative modelling framework to jointly learn a probabilistic latent state representation of multimodal data and the respective dynamics. Using synthetic and real-world datasets from a multimodal robotic planar pushing task, we demonstrate that our approach leads to significant improvements in prediction and representation quality. Furthermore, we compare to the common learning baseline of concatenating each modality in the latent space and show that our principled probabilistic formulation performs better. Finally, despite being fully self-supervised, we demonstrate that our method is nearly as effective as an existing supervised approach that relies on ground truth labels.
Heteroscedastic Uncertainty for Robust Generative Latent Dynamics
Aug 18, 2020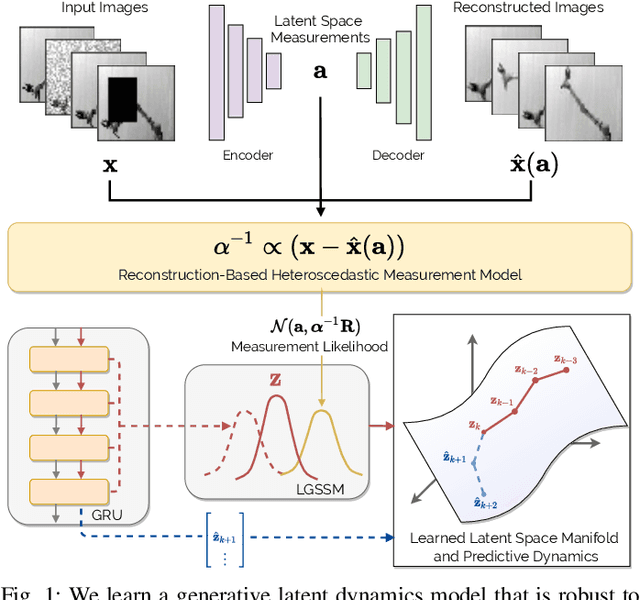
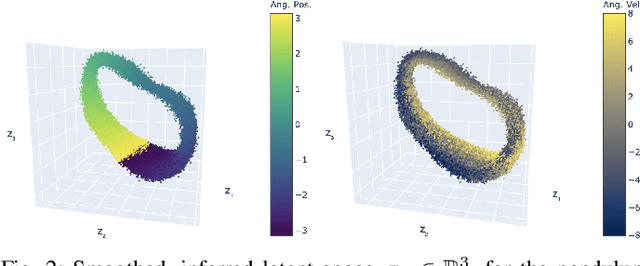
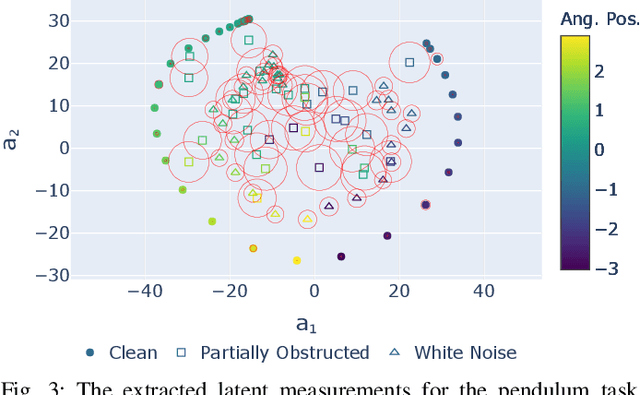
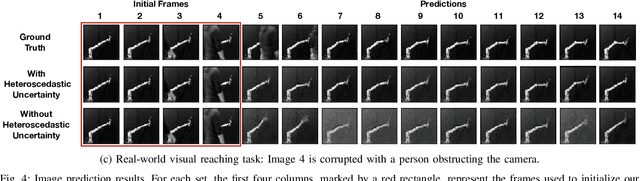
Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.
Fast Manipulability Maximization Using Continuous-Time Trajectory Optimization
Aug 08, 2019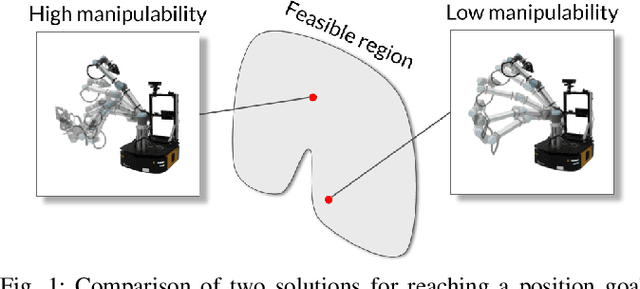
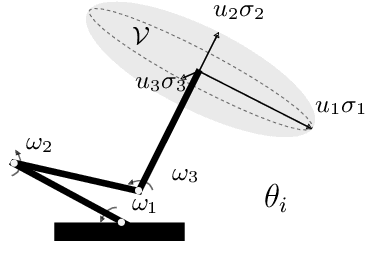
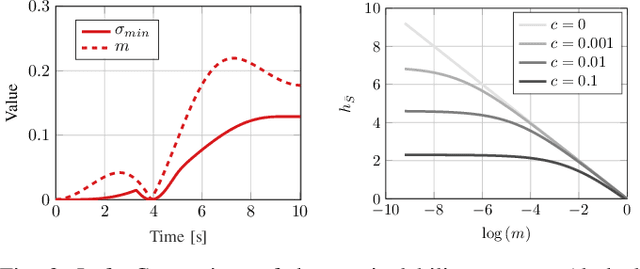
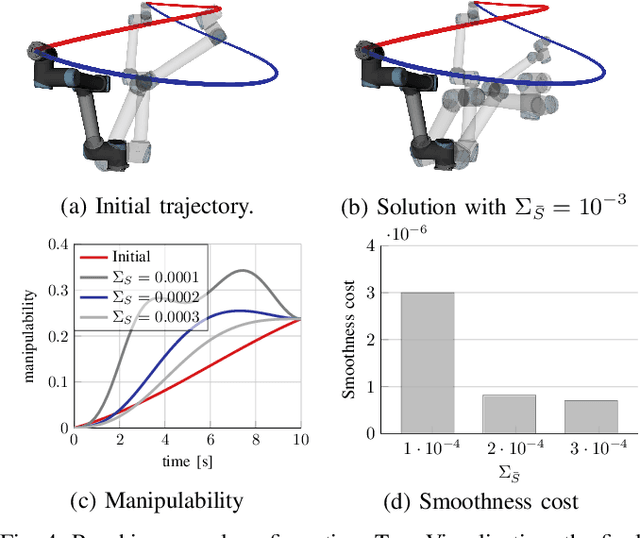
A significant challenge in manipulation motion planning is to ensure agility in the face of unpredictable changes during task execution. This requires the identification and possible modification of suitable joint-space trajectories, since the joint velocities required to achieve a specific end-effector motion vary with manipulator configuration. For a given manipulator configuration, the joint space-to-task space velocity mapping is characterized by a quantity known as the manipulability index. In contrast to previous control-based approaches, we examine the maximization of manipulability during planning as a way of achieving adaptable and safe joint space-to-task space motion mappings in various scenarios. By representing the manipulator trajectory as a continuous-time Gaussian process (GP), we are able to leverage recent advances in trajectory optimization to maximize the manipulability index during trajectory generation. Moreover, the sparsity of our chosen representation reduces the typically large computational cost associated with maximizing manipulability when additional constraints exist. Results from simulation studies and experiments with a real manipulator demonstrate increases in manipulability, while maintaining smooth trajectories with more dexterous (and therefore more agile) arm configurations.
Self-Calibration of Mobile Manipulator Kinematic and Sensor Extrinsic Parameters Through Contact-Based Interaction
Oct 22, 2018

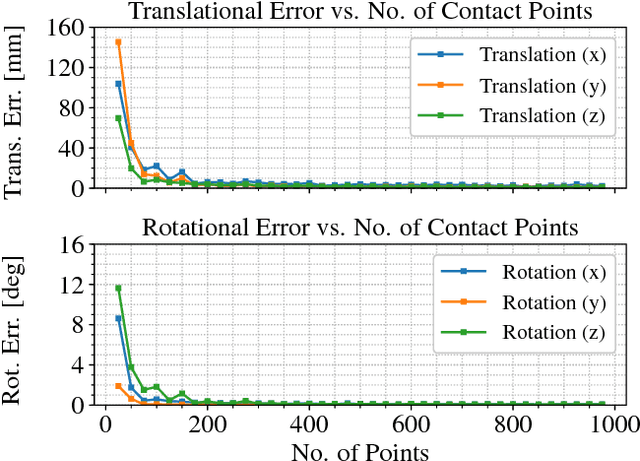
We present a novel approach for mobile manipulator self-calibration using contact information. Our method, based on point cloud registration, is applied to estimate the extrinsic transform between a fixed vision sensor mounted on a mobile base and an end effector. Beyond sensor calibration, we demonstrate that the method can be extended to include manipulator kinematic model parameters, which involves a non-rigid registration process. Our procedure uses on-board sensing exclusively and does not rely on any external measurement devices, fiducial markers, or calibration rigs. Further, it is fully automatic in the general case. We experimentally validate the proposed method on a custom mobile manipulator platform, and demonstrate centimetre-level post-calibration accuracy in positioning of the end effector using visual guidance only. We also discuss the stability properties of the registration algorithm, in order to determine the conditions under which calibration is possible.