 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoBot: Reference-Guided Interactive Photography via Natural Language
Paper and Code
Jan 19, 2024

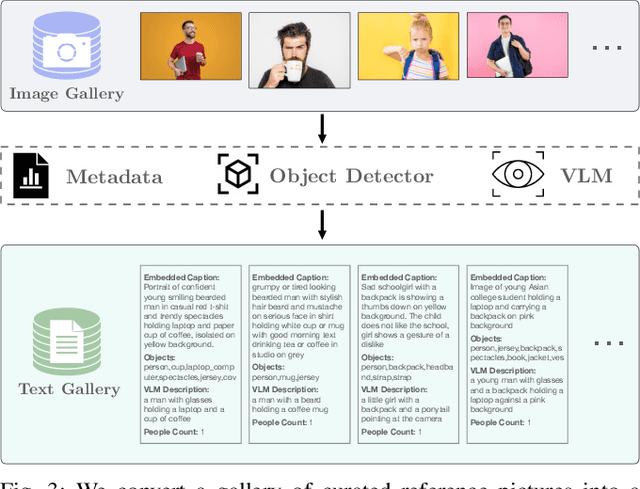

We introduce PhotoBot, a framework for automated photo acquisition based on an interplay between high-level human language guidance and a robot photographer. We propose to communicate photography suggestions to the user via a reference picture that is retrieved from a curated gallery. We exploit a visual language model (VLM) and an object detector to characterize reference pictures via textual descriptions and use a large language model (LLM) to retrieve relevant reference pictures based on a user's language query through text-based reasoning. To correspond the reference picture and the observed scene, we exploit pre-trained features from a vision transformer capable of capturing semantic similarity across significantly varying images. Using these features, we compute pose adjustments for an RGB-D camera by solving a Perspective-n-Point (PnP) problem. We demonstrate our approach on a real-world manipulator equipped with a wrist camera. Our user studies show that photos taken by PhotoBot are often more aesthetically pleasing than those taken by users themselves, as measured by human feedback.