 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoBot: Reference-Guided Interactive Photography via Natural Language
Jan 19, 2024

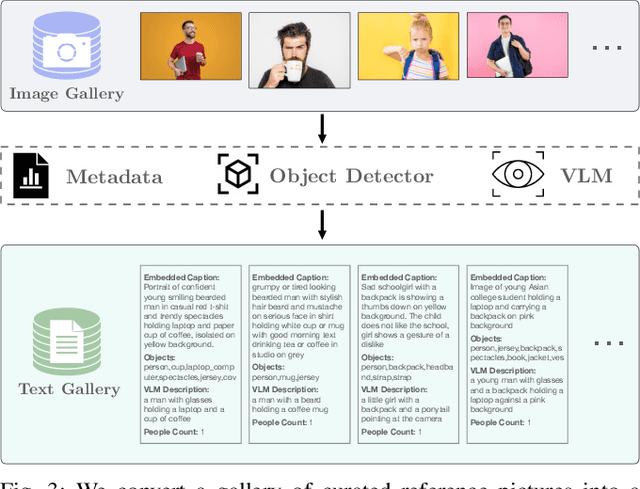

We introduce PhotoBot, a framework for automated photo acquisition based on an interplay between high-level human language guidance and a robot photographer. We propose to communicate photography suggestions to the user via a reference picture that is retrieved from a curated gallery. We exploit a visual language model (VLM) and an object detector to characterize reference pictures via textual descriptions and use a large language model (LLM) to retrieve relevant reference pictures based on a user's language query through text-based reasoning. To correspond the reference picture and the observed scene, we exploit pre-trained features from a vision transformer capable of capturing semantic similarity across significantly varying images. Using these features, we compute pose adjustments for an RGB-D camera by solving a Perspective-n-Point (PnP) problem. We demonstrate our approach on a real-world manipulator equipped with a wrist camera. Our user studies show that photos taken by PhotoBot are often more aesthetically pleasing than those taken by users themselves, as measured by human feedback.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
CARTIER: Cartographic lAnguage Reasoning Targeted at Instruction Execution for Robots
Jul 21, 2023This work explores the capacity of large language models (LLMs) to address problems at the intersection of spatial planning and natural language interfaces for navigation.Our focus is on following relatively complex instructions that are more akin to natural conversation than traditional explicit procedural directives seen in robotics. Unlike most prior work, where navigation directives are provided as imperative commands (e.g., go to the fridge), we examine implicit directives within conversational interactions. We leverage the 3D simulator AI2Thor to create complex and repeatable scenarios at scale, and augment it by adding complex language queries for 40 object types. We demonstrate that a robot can better parse descriptive language queries than existing methods by using an LLM to interpret the user interaction in the context of a list of the objects in the scene.
ANSEL Photobot: A Robot Event Photographer with Semantic Intelligence
Feb 15, 2023Our work examines the way in which large language models can be used for robotic planning and sampling, specifically the context of automated photographic documentation. Specifically, we illustrate how to produce a photo-taking robot with an exceptional level of semantic awareness by leveraging recent advances in general purpose language (LM) and vision-language (VLM) models. Given a high-level description of an event we use an LM to generate a natural-language list of photo descriptions that one would expect a photographer to capture at the event. We then use a VLM to identify the best matches to these descriptions in the robot's video stream. The photo portfolios generated by our method are consistently rated as more appropriate to the event by human evaluators than those generated by existing methods.
Self-Supervised Transformer Architecture for Change Detection in Radio Access Networks
Feb 03, 2023
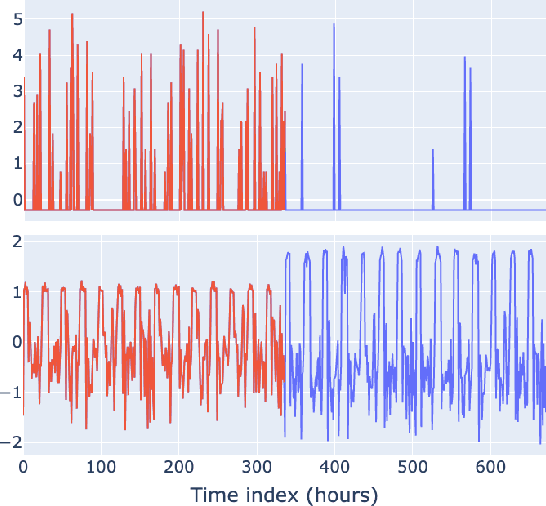
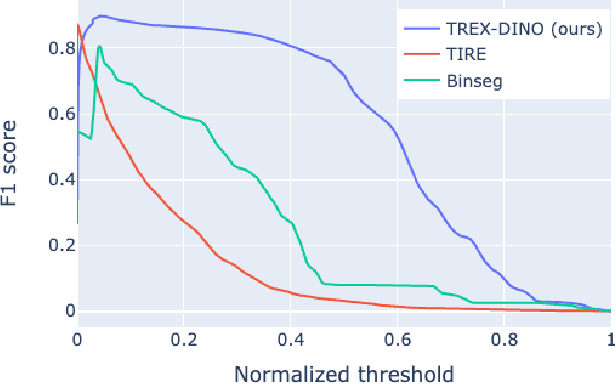

Radio Access Networks (RANs) for telecommunications represent large agglomerations of interconnected hardware consisting of hundreds of thousands of transmitting devices (cells). Such networks undergo frequent and often heterogeneous changes caused by network operators, who are seeking to tune their system parameters for optimal performance. The effects of such changes are challenging to predict and will become even more so with the adoption of 5G/6G networks. Therefore, RAN monitoring is vital for network operators. We propose a self-supervised learning framework that leverages self-attention and self-distillation for this task. It works by detecting changes in Performance Measurement data, a collection of time-varying metrics which reflect a set of diverse measurements of the network performance at the cell level. Experimental results show that our approach outperforms the state of the art by 4% on a real-world based dataset consisting of about hundred thousands timeseries. It also has the merits of being scalable and generalizable. This allows it to provide deep insight into the specifics of mode of operation changes while relying minimally on expert knowledge.