 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Defense Benchmark: Agentic Threat Hunting Evaluation for LLMs in SecOps
Apr 22, 2026We introduce the Cyber Defense Benchmark, a benchmark for measuring how well large language model (LLM) agents perform the core SOC analyst task of threat hunting: given a database of raw Windows event logs with no guided questions or hints, identify the exact timestamps of malicious events. The benchmark wraps 106 real attack procedures from the OTRF Security-Datasets corpus - spanning 86 MITRE ATT&CK sub-techniques across 12 tactics - into a Gymnasium reinforcement-learning environment. Each episode presents the agent with an in-memory SQLite database of 75,000-135,000 log records produced by a deterministic campaign simulator that time-shifts and entity-obfuscates the raw recordings. The agent must iteratively submit SQL queries to discover malicious event timestamps and explicitly flag them, scored CTF-style against Sigma-rule-derived ground truth. Evaluating five frontier models - Claude Opus 4.6, GPT-5, Gemini 3.1 Pro, Kimi K2.5, and Gemini 3 Flash - on 26 campaigns covering 105 of 106 procedures, we find that all models fail dramatically: the best model (Claude Opus 4.6) submits correct flags for only 3.8% of malicious events on average, and no run across any model ever finds all flags. We define a passing score as >= 50% recall on every ATT&CK tactic - the minimum bar for unsupervised SOC deployment. No model passes: the leader clears this bar on 5 of 13 tactics and the remaining four on zero. These results suggest that current LLMs are poorly suited for open-ended, evidence-driven threat hunting despite strong performance on curated Q&A security benchmarks.
Anomaly Detection for Scalable Task Grouping in Reinforcement Learning-based RAN Optimization
Dec 06, 2023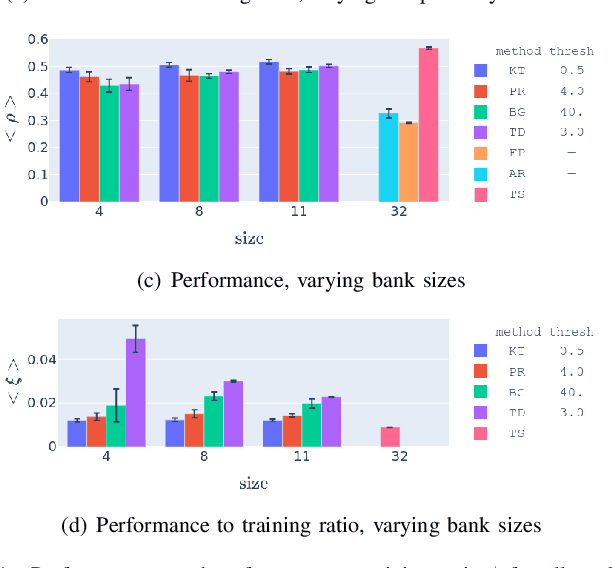
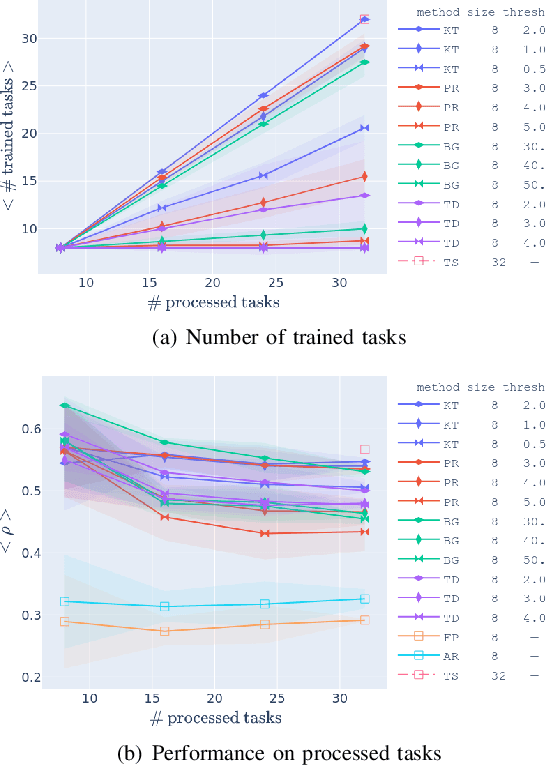
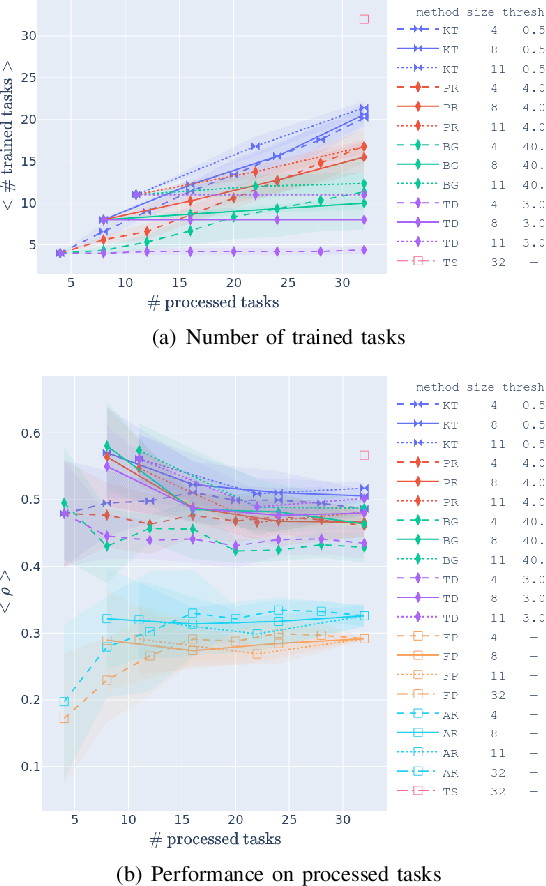
The use of learning-based methods for optimizing cellular radio access networks (RAN) has received increasing attention in recent years. This coincides with a rapid increase in the number of cell sites worldwide, driven largely by dramatic growth in cellular network traffic. Training and maintaining learned models that work well across a large number of cell sites has thus become a pertinent problem. This paper proposes a scalable framework for constructing a reinforcement learning policy bank that can perform RAN optimization across a large number of cell sites with varying traffic patterns. Central to our framework is a novel application of anomaly detection techniques to assess the compatibility between sites (tasks) and the policy bank. This allows our framework to intelligently identify when a policy can be reused for a task, and when a new policy needs to be trained and added to the policy bank. Our results show that our approach to compatibility assessment leads to an efficient use of computational resources, by allowing us to construct a performant policy bank without exhaustively training on all tasks, which makes it applicable under real-world constraints.
Self-Supervised Transformer Architecture for Change Detection in Radio Access Networks
Feb 03, 2023
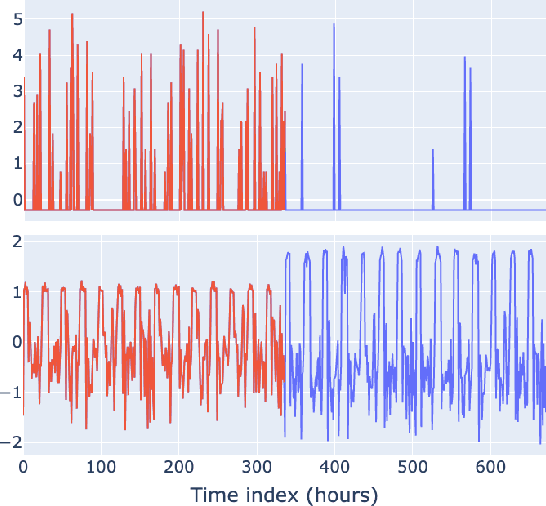
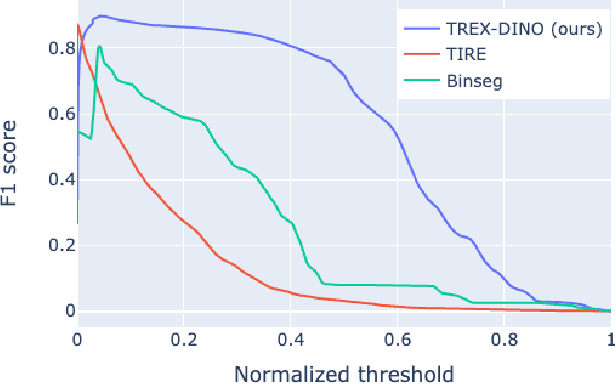

Radio Access Networks (RANs) for telecommunications represent large agglomerations of interconnected hardware consisting of hundreds of thousands of transmitting devices (cells). Such networks undergo frequent and often heterogeneous changes caused by network operators, who are seeking to tune their system parameters for optimal performance. The effects of such changes are challenging to predict and will become even more so with the adoption of 5G/6G networks. Therefore, RAN monitoring is vital for network operators. We propose a self-supervised learning framework that leverages self-attention and self-distillation for this task. It works by detecting changes in Performance Measurement data, a collection of time-varying metrics which reflect a set of diverse measurements of the network performance at the cell level. Experimental results show that our approach outperforms the state of the art by 4% on a real-world based dataset consisting of about hundred thousands timeseries. It also has the merits of being scalable and generalizable. This allows it to provide deep insight into the specifics of mode of operation changes while relying minimally on expert knowledge.